






19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 141577位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
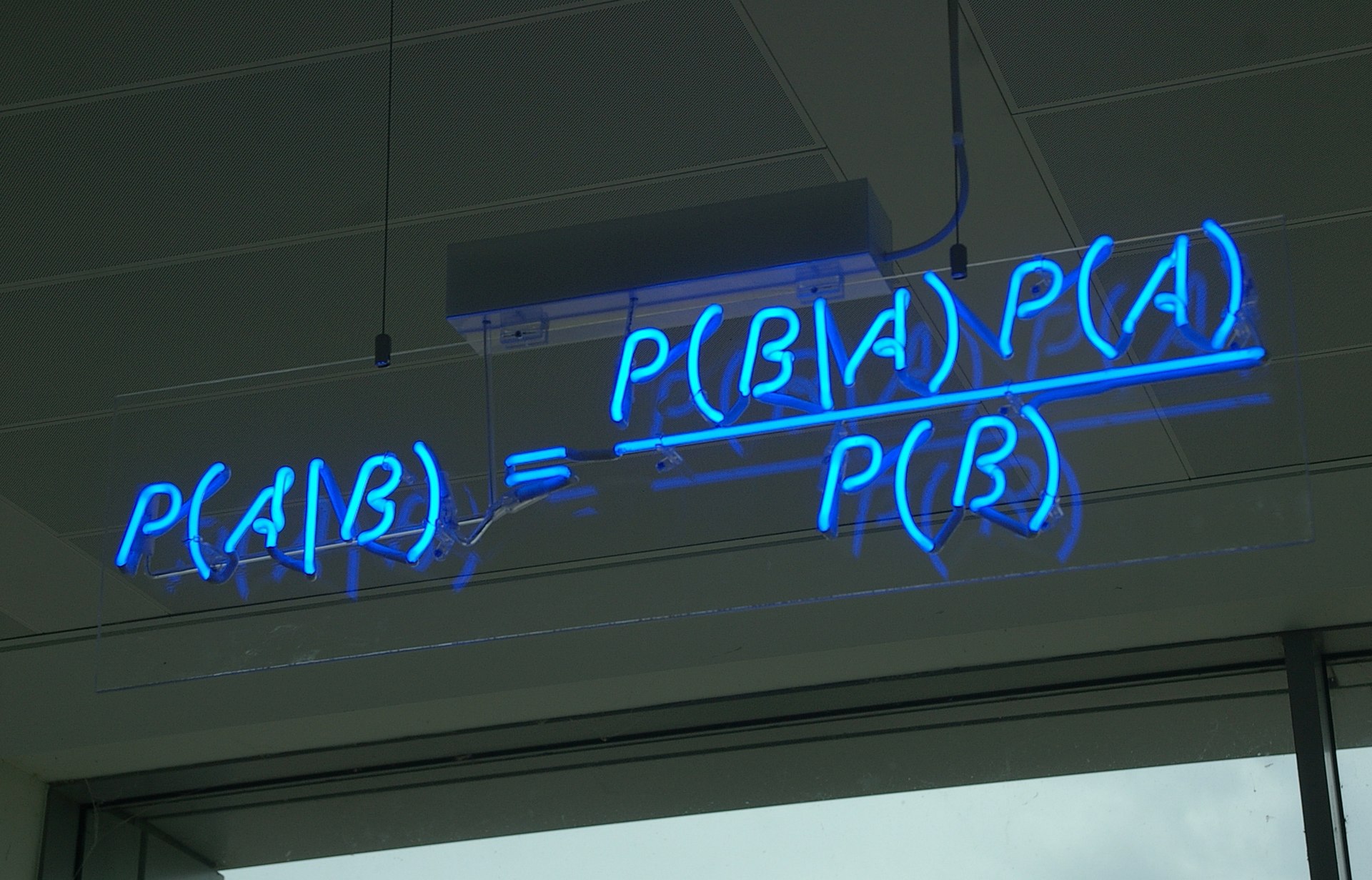
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
18
Aug
生成扩散模型漫谈(八):最优扩散方差估计(下)
By 苏剑林 | 2022-08-18 | 43671位读者 | 引用在上一篇文章《生成扩散模型漫谈(七):最优扩散方差估计(上)》中,我们介绍并推导了Analytic-DPM中的扩散模型最优方差估计结果,它是直接给出了已经训练好的生成扩散模型的最优方差的一个解析估计,实验显示该估计结果确实能有效提高扩散模型的生成质量。
这篇文章我们继续介绍Analytic-DPM的升级版,出自同一作者团队的论文《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》,在官方Github中被称为“Extended-Analytic-DPM”,下面我们也用这个称呼。
结果回顾
上一篇文章是在DDIM的基础上,推出DDIM的生成过程最优方差应该是
\begin{equation}\sigma_t^2 + \gamma_t^2\bar{\sigma}_t^2\end{equation}
其中$\bar{\sigma}_t^2$是分布$p(\boldsymbol{x}_0|\boldsymbol{x}_t)$的方差,它有如下的估计结果(这里取“方差估计2”的结果):
\begin{equation}\bar{\sigma}_t^2 = \frac{\bar{\beta}_t^2}{\bar{\alpha}_t^2}\left(1 - \frac{1}{d}\mathbb{E}_{\boldsymbol{x}_t\sim p(\boldsymbol{x}_t)}\left[ \Vert\boldsymbol{\epsilon}_{\boldsymbol{\theta}}(\boldsymbol{x}_t, t)\Vert^2\right]\right)\label{eq:basic}\end{equation}
25
Oct
圆内随机n点在同一个圆心角为θ的扇形的概率
By 苏剑林 | 2022-10-25 | 37852位读者 | 引用
31
May
关于NBCE方法的一些补充说明和分析
By 苏剑林 | 2023-05-31 | 26382位读者 | 引用上周在《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》中,我们介绍了一种基于朴素贝叶斯来扩展LLM的Context长度的方案NBCE(Naive Bayes-based Context Extension)。由于它有着即插即用、模型无关、不用微调等优点,也获得了一些读者的认可,总的来说目前大家反馈的测试效果还算可以。
当然,部分读者在使用的时候也提出了一些问题。本文就结合读者的疑问和笔者的后续思考,对NBCE方法做一些补充说明和分析。
方法回顾
假设$T$为要生成的token序列,$S_1,S_2,\cdots,S_n$是给定的若干个Context,我们需要根据$S_1,S_2,\cdots,S_n$生成$T$,那么就需要估计$p(T|S_1, S_2,\cdots,S_n)$。根据朴素贝叶斯思想,我们得到
\begin{equation}\log p(T|S_1, S_2,\cdots,S_n) = \color{red}{(\beta + 1)\overline{\log p(T|S)}} - \color{green}{\beta\log p(T)} + \color{skyblue}{\text{常数}}\label{eq:nbce-2}\end{equation}
20
Jul
语言模型输出端共享Embedding的重新探索
By 苏剑林 | 2023-07-20 | 30916位读者 | 引用预训练刚兴起时,在语言模型的输出端重用Embedding权重是很常见的操作,比如BERT、第一版的T5、早期的GPT,都使用了这个操作,这是因为当模型主干部分不大且词表很大时,Embedding层的参数量很可观,如果输出端再新增一个独立的同样大小的权重矩阵的话,会导致显存消耗的激增。不过随着模型参数规模的增大,Embedding层的占比相对变小了,加之《Rethinking embedding coupling in pre-trained language models》等研究表明共享Embedding可能会有些负面影响,所以现在共享Embedding的做法已经越来越少了。
本文旨在分析在共享Embedding权重时可能遇到的问题,并探索如何更有效地进行初始化和参数化。尽管共享Embedding看起来已经“过时”,但这依然不失为一道有趣的研究题目。
28
Aug
Lion/Tiger优化器训练下的Embedding异常和对策
By 苏剑林 | 2023-08-28 | 30214位读者 | 引用打从在《Tiger:一个“抠”到极致的优化器》提出了Tiger优化器之后,Tiger就一直成为了我训练模型的“标配”优化器。最近笔者已经尝试将Tiger用到了70亿参数模型的预训练之中,前期效果看上来尚可,初步说明Tiger也是能Scale Up的。不过,在查看训练好的模型权重时,笔者发现Embedding出现了一些异常值,有些Embedding的分量达到了$\pm 100$的级别。
经过分析,笔者发现类似现象并不会在Adam中出现,这是Tiger或者Lion这种带符号函数$\text{sign}$的优化器特有的问题,对此文末提供了两种参考解决方案。本文将记录笔者的分析过程,供大家参考。
现象
接下来,我们的分析都以Tiger优化器为例,但分析过程和结论同样适用于Lion。
14
Aug
Transformer升级之路:13、逆用Leaky ReRoPE
By 苏剑林 | 2023-08-14 | 21187位读者 | 引用上周在《Transformer升级之路:12、无限外推的ReRoPE?》中,笔者提出了ReRoPE和Leaky ReRoPE,诸多实验结果表明,它们能够在几乎不损失训练效果的情况下免微调地扩展LLM的Context长度,并且实现了“longer context, lower loss”的理想特性,此外跟NTK-aware Scaled RoPE不同的是,其中ReRoPE似乎还有表现出了无限的Context处理能力。
总之,ReRoPE看起来相当让人满意,但美中不足的是会增加推理成本,具体表现为第一步推理需要算两次Attention,以及后续每步推理需要重新计算位置编码。本文试图通过在训练中逆用Leaky ReRoPE的方法来解决这个问题。
回顾
让我们不厌其烦地重温一下:RoPE形式上是一种绝对位置编码,但实际达到的效果是相对位置编码,对应的相对位置矩阵是:
\begin{equation}\begin{pmatrix}0 & \\
1 & 0 & \\
2 & 1 & 0 &\\
3 & 2 & 1 & 0 & \\
\ddots & 3 & 2 & 1 & 0 & \\
\ddots & \ddots & 3 & 2 & 1 & 0 & \\
\ddots & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots \\
\small{L - 2} & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots & \ddots \\
\small{L - 1} & \small{L - 2} & \ddots & \ddots & \ddots & 3 & 2 & 1 & 0 & \\
\end{pmatrix}\label{eq:rope}\end{equation}
16
Sep
随机分词浅探:从Viterbi Decoding到Viterbi Sampling
By 苏剑林 | 2023-09-16 | 21564位读者 | 引用上一篇文章《大词表语言模型在续写任务上的一个问题及对策》发布后,很快就有读者指出可以在训练阶段引入带有随机性的分词结果来解决同样的问题,并且已经有论文和实现。经过进一步查阅学习,笔者发现这是一个名为Subword Regularization的技巧,最早应用在NMT(机器翻译)中,目前SentencePiece也有相应的实现。看起来这个技巧确实能缓解前述问题,甚至有助于增强语言模型的容错能力,所以就有了将它加进去BytePiece的想法。
那么问题来了,如何将确定性分词改为随机性分词呢?BytePiece是基于Unigram模型的,它通过Viterbi算法找最大概率的分词方案,既然有概率,是否就可以自然地导出随机采样?本文来讨论这个问题,并分享自己的解决方案。

最近评论