






27
Oct
算符的艺术:差分、微分与伯努利数
By 苏剑林 | 2014-10-27 | 38521位读者 | 引用两年前,笔者曾写过《算子与线性常微分方程》两篇,简单介绍了把线形常微分方程算符化,然后通过对算符求逆的方法求得常微分方程的通解。而在这篇文章中,笔者打算介绍关于算符类似的内容:差分算符、微分算符以及与之相关的伯努利数(Bernoulli数)。
我们记$D=\frac{d}{dx}$,那么$Df=\frac{df}{dx}$,同时定义$\Delta_t f(x)=f(x+t)-f(x)$,并且记$\Delta \equiv \Delta_1 =f(x+1)-f(x)$,这里我们研究的$f(x)$,都是具有良好性态的。我们知道,$f(x+t)$在$t=0$附近的泰勒展式为
$$\begin{aligned}f(x+t)&=f(x) + \frac{df(x)}{dx}t + \frac{1}{2!}\frac{d^2 f(x)}{dx^2}t^2 + \frac{1}{3!}\frac{d^3 f(x)}{dx^3}t^3 + \dots\\
&=\left(1+t\frac{d}{dx}+\frac{1}{2!}t^2\frac{d^2}{dx^2}+\dots\right)f(x)\\
&=\left(1+tD+\frac{1}{2!}t^2 D^2+\dots\right)f(x)\end{aligned}$$
24
Nov
力的无穷分解与格林函数法
By 苏剑林 | 2014-11-24 | 36508位读者 | 引用我小时候一直有个疑问:
直升机上的螺旋桨能不能用来挡雨?
一般的螺旋桨是若干个“条状”物通过旋转对称而形成的,也就是说,它并非一个面,按常理来说,它是没办法用来挡雨的。但是,如果在高速旋转的情况下,甚至假设旋转速度可以任意大,那么我们任意时刻都没有办法穿过它了,这种情况下,它似乎与一个实在的面无异?
力的无穷分解
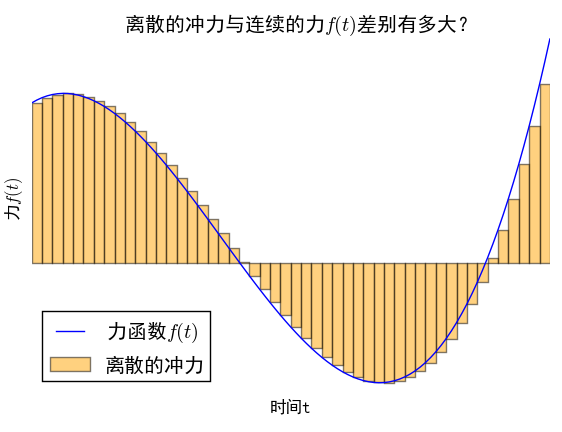
力的离散化
而让人惊喜的是,在通常的物理系统中,将力分段为无数个小区间内的恒力的做法,能够导致正确的答案,而且,这恰好是线性常微分方程的格林函数法。下面我们来分析这一做法。
15
Apr
斯特灵(stirling)公式与渐近级数
By 苏剑林 | 2016-04-15 | 60861位读者 | 引用斯特灵近似,或者称斯特灵公式,最开始是作为阶乘的近似提出
$$n!\sim \sqrt{2\pi n}\left(\frac{n}{e}\right)^n$$
符号$\sim$意味着
$$\lim_{n\to\infty}\frac{\sqrt{2\pi n}\left(\frac{n}{e}\right)^n}{n!}=1$$
将斯特灵公式进一步提高精度,就得到所谓的斯特灵级数
$$n!=\sqrt{2\pi n}\left(\frac{n}{e}\right)^n\left(1+\frac{1}{12n}+\frac{1}{288n^2}\dots\right)$$
很遗憾,这个是渐近级数。
相关资料有:
https://zh.wikipedia.org/zh-cn/斯特灵公式
https://en.wikipedia.org/wiki/Stirling%27s_approximation
本文将会谈到斯特灵公式及其渐近级数的一个改进的推导,并解释渐近级数为什么渐近。
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 216432位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
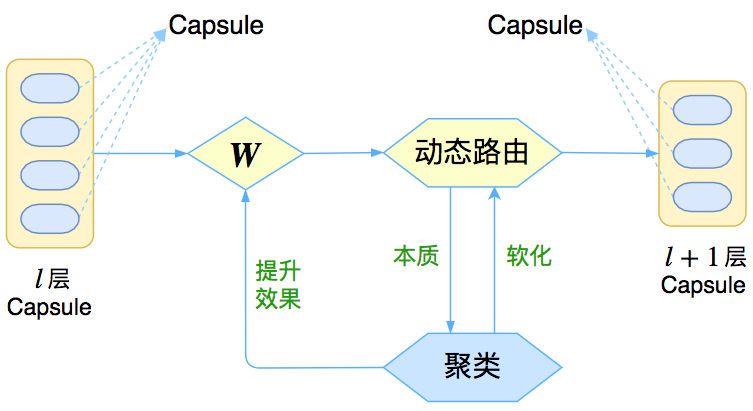
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
23
Jun
貌离神合的RNN与ODE:花式RNN简介
By 苏剑林 | 2018-06-23 | 103876位读者 | 引用本来笔者已经决心不玩RNN了,但是在上个星期思考时忽然意识到RNN实际上对应了ODE(常微分方程)的数值解法,这为我一直以来想做的事情——用深度学习来解决一些纯数学问题——提供了思路。事实上这是一个颇为有趣和有用的结果,遂介绍一翻。顺便地,本文也涉及到了自己动手编写RNN的内容,所以本文也可以作为编写自定义的RNN层的一个简单教程。
注:本文并非前段时间的热点“神经ODE”的介绍(但有一定的联系)。
RNN基本
什么是RNN?
众所周知,RNN是“循环神经网络(Recurrent Neural Network)”,跟CNN不同,RNN可以说是一类模型的总称,而并非单个模型。简单来讲,只要是输入向量序列$(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_T)$,输出另外一个向量序列$(\boldsymbol{y}_1,\boldsymbol{y}_2,\dots,\boldsymbol{y}_T)$,并且满足如下递归关系
$$\boldsymbol{y}_t=f(\boldsymbol{y}_{t-1}, \boldsymbol{x}_t, t)\tag{1}$$
的模型,都可以称为RNN。也正因为如此,原始的朴素RNN,还有改进的如GRU、LSTM、SRU等模型,我们都称为RNN,因为它们都可以作为上式的一个特例。还有一些看上去与RNN没关的内容,比如前不久介绍的CRF的分母的计算,实际上也是一个简单的RNN。
说白了,RNN其实就是递归计算。
19
Oct
最小熵原理(五):“层层递进”之社区发现与聚类
By 苏剑林 | 2019-10-19 | 153792位读者 | 引用让我们不厌其烦地回顾一下:最小熵原理是一个无监督学习的原理,“熵”就是学习成本,而降低学习成本是我们的不懈追求,所以通过“最小化学习成本”就能够无监督地学习出很多符合我们认知的结果,这就是最小熵原理的基本理念。
这篇文章里,我们会介绍一种相当漂亮的聚类算法,它同样也体现了最小熵原理,或者说它可以通过最小熵原理导出来,名为InfoMap,或者MapEquation。事实上InfoMap已经是2007年的成果了,最早的论文是《Maps of random walks on complex networks reveal community structure》,虽然看起来很旧,但我认为它仍是当前最漂亮的聚类算法,因为它不仅告诉了我们“怎么聚类”,更重要的是给了我们一个“为什么要聚类”的优雅的信息论解释,并从这个解释中直接导出了整个聚类过程。
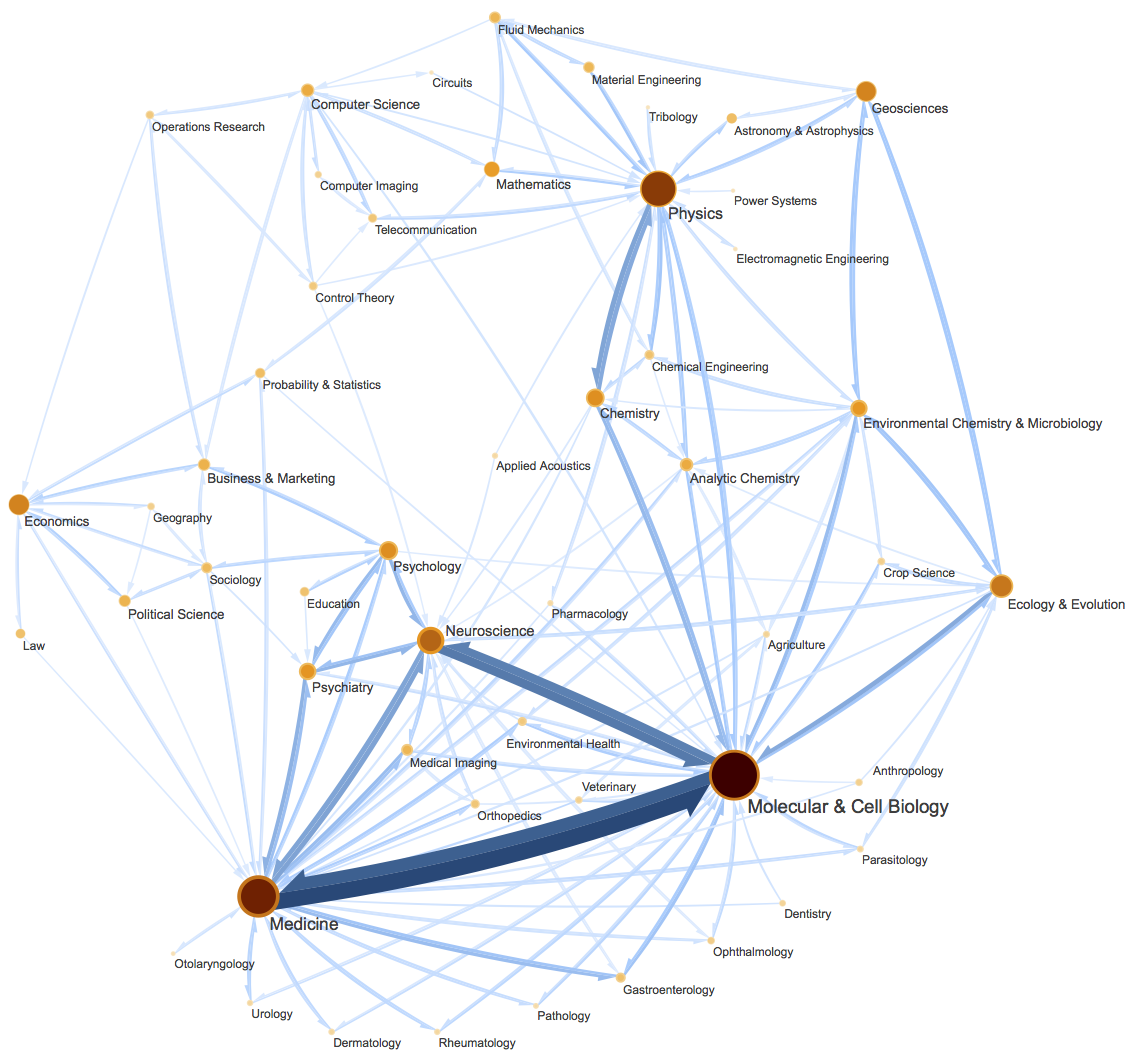
一个复杂有向图网络示意图。图片来自InfoMap最早的论文《Maps of random walks on complex networks reveal community structure》
当然,它的定位并不仅仅局限在聚类上,更准确地说,它是一种图网络上的“社区发现”算法。所谓社区发现(Community Detection),大概意思是给定一个有向/无向图网络,然后找出这个网络上的“抱团”情况,至于详细含义,大家可以自行搜索一下。简单来说,它跟聚类相似,但是比聚类的含义更丰富。(还可以参考《什么是社区发现?》)
31
Jan
Transformer升级之路:8、长度外推性与位置鲁棒性
By 苏剑林 | 2023-01-31 | 45706位读者 | 引用上一篇文章《Transformer升级之路:7、长度外推性与局部注意力》我们讨论了Transformer的长度外推性,得出的结论是长度外推性是一个训练和预测的不一致问题,而解决这个不一致的主要思路是将注意力局部化,很多外推性好的改进某种意义上都是局部注意力的变体。诚然,目前语言模型的诸多指标看来局部注意力的思路确实能解决长度外推问题,但这种“强行截断”的做法也许会不符合某些读者的审美,因为人工雕琢痕迹太强,缺乏了自然感,同时也让人质疑它们在非语言模型任务上的有效性。
本文我们从模型对位置编码的鲁棒性角度来重新审视长度外推性这个问题,此思路可以在基本不对注意力进行修改的前提下改进Transformer的长度外推效果,并且还适用多种位置编码,总体来说方法更为优雅自然,而且还适用于非语言模型任务。
17
Apr
生成扩散模型漫谈(二十三):信噪比与大图生成(下)
By 苏剑林 | 2024-04-17 | 32436位读者 | 引用上一篇文章《生成扩散模型漫谈(二十二):信噪比与大图生成(上)》中,我们介绍了通过对齐低分辨率的信噪比来改进noise schedule,从而改善直接在像素空间训练的高分辨率图像生成(大图生成)的扩散模型效果。而这篇文章的主角同样是信噪比和大图生成,但做到了更加让人惊叹的事情——直接将训练好低分辨率图像的扩散模型用于高分辨率图像生成,不用额外的训练,并且效果和推理成本都媲美直接训练的大图模型!
这个工作出自最近的论文《Upsample Guidance: Scale Up Diffusion Models without Training》,它巧妙地将低分辨率模型上采样作为引导信号,并结合了CNN对纹理细节的平移不变性,成功实现了免训练高分辨率图像生成。
思想探讨
我们知道,扩散模型的训练目标是去噪(Denoise,也是DDPM的第一个D)。按我们的直觉,去噪这个任务应该是分辨率无关的,换句话说,理想情况下低分辨率图像训练的去噪模型应该也能用于高分辨率图像去噪,从而低分辨率的扩散模型应该也能直接用于高分辨率图像生成。

最近评论