






1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 462723位读者 |话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介 #
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
基本结构 #
假如原句子为$X=(a,b,c,d,e,f)$,目标输出为$Y=(P,Q,R,S,T)$,那么一个基本的seq2seq就如下图所示。
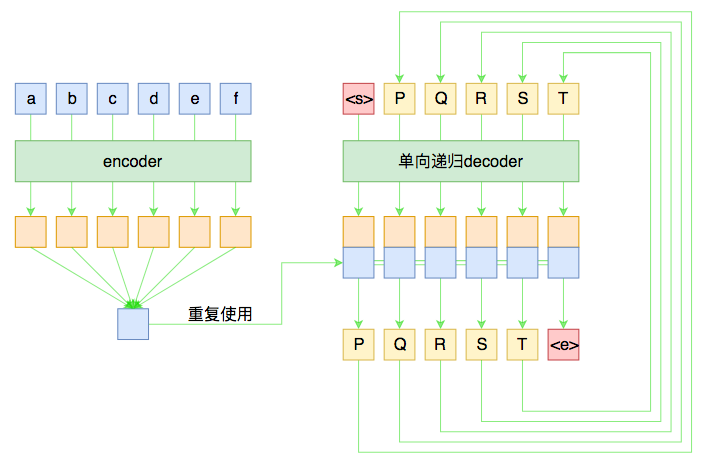
基本的seq2seq架构
尽管整个图的线条比较多,可能有点眼花,但其实结构很简单。左边是对输入的encoder,它负责把输入(可能是变长的)编码为一个固定大小的向量,这个可选择的模型就很多了,用GRU、LSTM等RNN结构或者CNN+Pooling、Google的纯Attention等都可以,这个固定大小的向量,理论上就包含了输入句子的全部信息。
而decoder负责将刚才我们编码出来的向量解码为我们期望的输出。与encoder不同,我们在图上强调decoder是“单向递归”的,因为解码过程是递归进行的,具体流程为:
1、所有输出端,都以一个通用的<start>标记开头,以<end>标记结尾,这两个标记也视为一个词/字;
2、将<start>输入decoder,然后得到隐藏层向量,将这个向量与encoder的输出混合,然后送入一个分类器,分类器的结果应当输出$P$;
3、将$P$输入decoder,得到新的隐藏层向量,再次与encoder的输出混合,送入分类器,分类器应输出$Q$;
4、依此递归,直到分类器的结果输出<end>。
这就是一个基本的seq2seq模型的解码过程,在解码的过程中,将每步的解码结果送入到下一步中去,直到输出<end>位置。
训练过程 #
事实上,上图也表明了一般的seq2seq的训练过程。由于训练的时候我们有标注数据对,因此我们能提前预知decoder每一步的输入和输出,因此整个结果实际上是“输入$X$和$Y_{\text{[:-1]}}$,预测$Y_{\text{[1:]}}$,即将目标$Y$错开一位来训练。这种训练方式,称之为Teacher-Forcing。
而decoder同样可以用GRU、LSTM或CNN等结构,但注意再次强调这种“预知未来”的特性仅仅在训练中才有可能,在预测阶段是不存在的,因此decoder在执行每一步时,不能提前使用后面步的输入。所以,如果用RNN结构,一般都只使用单向RNN;如果使用CNN或者纯Attention,那么需要把后面的部分给mask掉(对于卷积来说,就是在卷积核上乘上一个0/1矩阵,使得卷积只能读取当前位置及其“左边”的输入,对于Attention来说也类似,不过是对query的序列进行mask处理)。
敏感的读者可能会察觉到,这种训练方案是“局部”的,事实上不够端到端。比如当我们预测$R$时是假设$Q$已知的,即$Q$在前一步被成功预测,但这是不能直接得到保证的。一般前面某一步的预测出错,那么可能导致连锁反应,后面各步的训练和预测都没有意义了。
有学者考虑过这个问题,比如文章《Sequence-to-Sequence Learning as Beam-Search Optimization》把整个解码搜索过程也加入到训练过程,而且还是纯粹梯度下降的(不用强化学习),是非常值得借鉴的一种做法。不过局部训练的计算成本比较低,一般情况下我们都只是使用局部训练来训练seq2seq。
beam search #
前面已经多次提到了解码过程,但还不完整。事实上,对于seq2seq来说,我们是在建模
$$p(\boldsymbol{Y}|\boldsymbol{X})=p(Y_1|\boldsymbol{X})p(Y_2|\boldsymbol{X},Y_1)p(Y_3|\boldsymbol{X},Y_1,Y_2)p(Y_4|\boldsymbol{X},Y_1,Y_2,Y_3)p(Y_5|\boldsymbol{X},Y_1,Y_2,Y_3,Y_4)\tag{1}$$
显然在解码时,我们希望能找到最大概率的$\boldsymbol{Y}$,那要怎么做呢?
如果在第一步$p(Y_1|\boldsymbol{X})$时,直接选择最大概率的那个(我们期望是目标$P$),然后代入第二步$p(Y_2|\boldsymbol{X},Y_1)$,再次选择最大概率的$Y_2$,依此类推,每一步都选择当前最大概率的输出,那么就称为贪心搜索,是一种最低成本的解码方案。但是要注意,这种方案得到的结果未必是最优的,假如第一步我们选择了概率不是最大的$Y_1$,代入第二步时也许会得到非常大的条件概率$p(Y_2|\boldsymbol{X},Y_1)$,从而两者的乘积会超过逐位取最大的算法。
然而,如果真的要枚举所有路径取最优,那计算量是大到难以接受的(这不是一个马尔可夫过程,动态规划也用不了)。因此,seq2seq使用了一种折中的方法:beam search。
这种算法类似动态规划,但即使在能用动态规划的问题下,它还比动态规划要简单,它的思想是:在每步计算时,只保留当前最优的$top_k$个候选结果。比如取$top_k=3$,那么第一步时,我们只保留使得$p(Y_1|\boldsymbol{X})$最大的前3个$Y_1$,然后分别代入$p(Y_2|\boldsymbol{X},Y_1)$,然后各取前三个$Y_2$,这样一来我们就有$3^2=9$个组合了,这时我们计算每一种组合的总概率,然后还是只保留前三个,依次递归,直到出现了第一个<end>。显然,它本质上还属于贪心搜索的范畴,只不过贪心的过程中保留了更多的可能性,普通的贪心搜索相当于$top_k=1$。
seq2seq提升 #
前面所示的seq2seq模型是标准的,但它把整个输入编码为一个固定大小的向量,然后用这个向量解码,这意味着这个向量理论上能包含原来输入的所有信息,会对encoder和decoder有更高的要求,尤其在机器翻译等信息不变的任务上。因为这种模型相当于让我们“看了一遍中文后就直接写出对应的英文翻译”那样,要求有强大的记忆能力和解码能力,事实上普通人完全不必这样,我们还会反复翻看对比原文,这就导致了下面的两个技巧。
Attention #
Attention目前基本上已经是seq2seq模型的“标配”模块了,它的思想就是:每一步解码时,不仅仅要结合encoder编码出来的固定大小的向量(通读全文),还要往回查阅原来的每一个字词(精读局部),两者配合来决定当前步的输出。
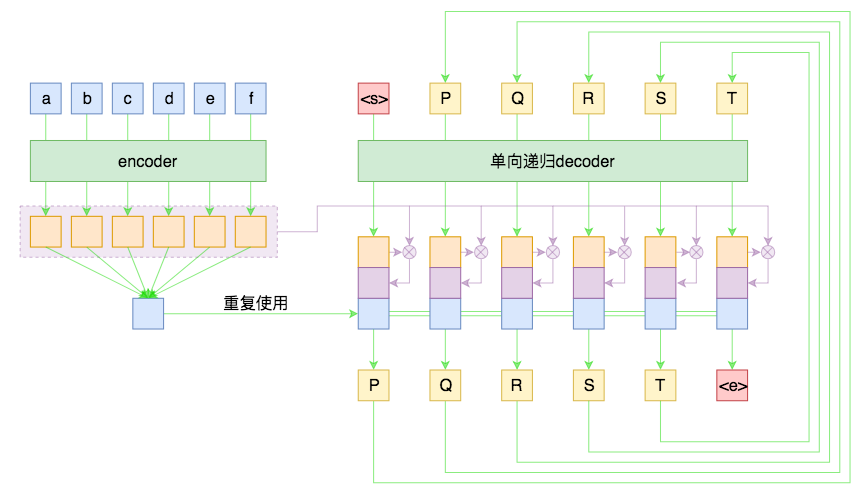
带Attention的seq2seq
至于Attention的具体做法,笔者之前已经撰文介绍过了,请参考《Attention is All You Need》浅读(简介+代码)。Attention一般分为乘性和加性两种,笔者介绍的是Google系统介绍的乘性的Attention,加性的Attention读者可以自行查阅,只要抓住query、key、value三个要素,Attention就都不难理解了。
先验知识 #
回到用seq2seq生成文章标题这个任务上,模型可以做些简化,并且可以引入一些先验知识。比如,由于输入语言和输出语言都是中文,因此encoder和decoder的Embedding层可以共享参数(也就是用同一套词向量)。这使得模型的参数量大幅度减少了。
此外,还有一个很有用的先验知识:标题中的大部分字词都在文章中出现过(注:仅仅是出现过,并不一定是连续出现,更不能说标题包含在文章中,不然就成为一个普通的序列标注问题了)。这样一来,我们可以用文章中的词集作为一个先验分布,加到解码过程的分类模型中,使得模型在解码输出时更倾向选用文章中已有的字词。
具体来说,在每一步预测时,我们得到总向量$\boldsymbol{x}$(如前面所述,它应该是decoder当前的隐层向量、encoder的编码向量、当前decoder与encoder的Attention编码三者的拼接),然后接入到全连接层,最终得到一个大小为$|V|$的向量$\boldsymbol{y}=(y_1,y_2,\dots,y_{|V|})$,其中$|V|$是词表的词数。$\boldsymbol{y}$经过softmax后,得到原本的概率
$$p_i = \frac{e^{y_i}}{\sum\limits_i e^{y_i}}\tag{2}$$
这就是原始的分类方案。引入先验分布的方案是,对于每篇文章,我们得到一个大小为$|V|$的0/1向量$\boldsymbol{\chi}=(\chi_1,\chi_2,\dots,\chi_{|V|})$,其中$\chi_i=1$意味着该词在文章中出现过,否则$\chi_i=0$。将这样的一个0/1向量经过一个缩放平移层得到:
$$\hat{\boldsymbol{y}}=\boldsymbol{s}\otimes \boldsymbol{\chi} + \boldsymbol{t}=(s_1\chi_1+t_1, s_2\chi_2+t_2, \dots, s_{|V|}\chi_{|V|}+t_{|V|})\tag{3}$$
其中$\boldsymbol{s},\boldsymbol{t}$为训练参数,然后将这个向量与原来的$\boldsymbol{y}$取平均后才做softmax
$$\boldsymbol{y}\leftarrow \frac{\boldsymbol{y}+\hat{\boldsymbol{y}}}{2},\quad p_i = \frac{e^{y_i}}{\sum\limits_i e^{y_i}}\tag{4}$$
经实验,这个先验分布的引入,有助于加快收敛,生成更稳定的、质量更优的标题。
Keras参考 #
又到了快乐的开源时光~
基本实现 #
基于上面的描述,我收集了80多万篇新闻的语料,来试图训练一个自动标题的模型。简单起见,我选择了以字为基本单位,并且引入了4个额外标记,分别代表mask、unk、start、end。而encoder我使用了双层双向LSTM,decoder使用了双层单向LSTM。具体细节可以参考源码(Python 2.7 + Keras 2.2.4 + Tensorflow 1.8):
我以6.4万文章为一个epoch,训练了50个epoch(一个多小时)之后,基本就生成了看上去还行的标题:
文章内容:8月28日,网络爆料称,华住集团旗下连锁酒店用户数据疑似发生泄露。从卖家发布的内容看,数据包含华住旗下汉庭、禧玥、桔子、宜必思等10余个品牌酒店的住客信息。泄露的信息包括华住官网注册资料、酒店入住登记的身份 信息及酒店开房记录,住客姓名、手机号、邮箱、身份证号、登录账号密码等。卖家对这个约5亿条数据打包出售。第三方安全平台威胁猎人对信息出售者提供的三万条数据进行验证,认为数据真实性非常高。当天下午,华住集团发 声明称,已在内部迅速开展核查,并第一时间报警。当晚,上海警方消息称,接到华住集团报案,警方已经介入调查。
生成标题:《酒店用户数据疑似发生泄露》文章内容:新浪体育讯 北京时间10月16日,NBA中国赛广州站如约开打,火箭再次胜出,以95-85击败篮网。姚明渐入佳境,打了18分39秒,8投5中,拿下10分5个篮板,他还盖帽1次。火箭以两战皆胜的战绩圆满结束中国行。
生成标题:《直击:火箭两战皆胜火箭再胜 广州站姚明10分5板》
当然这只是两个比较好的例子,还有很多不好的例子,直接用到工程上肯定是不够的,还需要很多“黑科技”优化才行。
mask #
在seq2seq中,做好mask是非常重要的,所谓mask,就是要遮掩掉不应该读取到的信息、或者是无用的信息,一般是用0/1向量来乘掉它。keras自带的mask机制十分不友好,有些层不支持mask,而普通的LSTM开启了mask后速度几乎下降了一半。所以现在我都是直接以0作为mask的标记,然后自己写个Lambda层进行转化的,这样速度基本无损,而且支持嵌入到任意层,具体可以参考上面的代码。
要注意我们以往一般是不区分mask和unk(未登录词)的,但如果采用我这种方案,还是把未登录词区分一下比较好,因为未登录词尽管我们不清楚具体含义,它还是一个真正的词,至少有占位作用,而mask是我们希望完全抹掉的信息。
解码端 #
代码中已经实现了beam search解码,读者可以自行测试不同的$top_k$对解码结果的影响。
这里要说的是,参考代码中对解码的实现是比较偷懒的,会使得解码速度大降。理论上来说,我们每次得到当前时刻的输出后,我们只需要传入到LSTM的下一步迭代中去,就可以得到下一时刻的输出,但这需要重写解码端的LSTM(也就是要区分训练阶段和测试阶段,两者共享权重),相对复杂,而且对初学者并不友好。所以我使用了一个非常粗暴的方案:每一步预测都重跑一次整个模型,这样一来代码量最少,但是越到后面越慢,原来是$\mathcal{O}(n)$的计算量变成了$\mathcal{O}(n^2)$。
最后的话 #
又用Keras跑通了一个例子,不错不错,坚定不移高举Keras旗帜~
自动标题任务的语料比较好找,而且在seq2seq任务中属于难度比较低的一个,适合大家练手,想要入坑的朋友赶紧上吧哈。
转载到请包括本文地址:https://spaces.ac.cn/archives/5861
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Sep. 01, 2018). 《玩转Keras之seq2seq自动生成标题 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/5861
@online{kexuefm-5861,
title={玩转Keras之seq2seq自动生成标题},
author={苏剑林},
year={2018},
month={Sep},
url={\url{https://spaces.ac.cn/archives/5861}},
}

September 17th, 2018
能否给个文件小样本,这个错误卡了
---> 92 # x = Bidirectional(CuDNNLSTM(char_size/2, return_sequences=True))(x)
93 # x = Bidirectional(CuDNNLSTM(char_size/2, return_sequences=True))(x)
TypeError: Value passed to parameter 'shape' has DataType float32 not in list of allowed values: int32, int64
你用python3吧?char_size/2改为char_size//2试试
September 27th, 2018
您好, 代码中有个问题:mv = K.max(v - (1. - v_mask) * 1e10, axis=1, keepdims=True) # maxpooling1d
这里实现最大池化,为什么要v-(1. - v_mask) * 1e10 这些和最大池化有什么关系呢
我们是希望在原来的句子内进行最大词化,但是因为我们进行了padding,所以原来长度为3的句子,可能变成了长度5,而后面两个词仅仅是占位符,没有特别意义。
但如果直接对长度为5的序列做最大池化的话,模型就有可能取到了后面两个序列的值(最大值可能是在最后两个序列中),事实上这是不允许的(预测结果应该跟padding没关系才行),所以我将后面两个序列的值都减去一个非常大的数$10^{10}$,这样一来,因为后面两个序列的数值都非常小,所以最大池化就不会取到它们了,结果就不会受到padding的影响了。
你说的有道理,麻烦再和您探讨一个问题哈,
# 下面几步只是实现了一个乘性attention
qw = K.dot(q, self.kernel)
a = K.batch_dot(qw, k, [2, 2]) / 10.
这第二行代码的结尾为什么要除以10呢
苏神您好,我复现了您的实验,发现效果的确十分出众。但是我还有一点点问题希望得到您的指导。
1.我发现你的代码得到的结果不会出现UNK未登录词的问题,这令我十分诧异,我想知道这是否与您选取了先验知识这一种方法有关?
2.我看您的训练数据为6.4w,batch_size是64,iteration为1000,我想请问这些超参数对于输出的影响是很大的么?我用了5w条数据进行实验,发现有时候选择50次epoch的结果甚至好于100次epoch。这是否可以认为模型出现了过拟合?
3.对于loss函数的定义,假设我选取得标题是“标题党”,这会不会导致loss函数会比实际要大很多?比如新闻是一段很正常得新闻,标题则为“震惊!XXXX”这一类的。
1、本身就是基于字的模型,自然出现未登录词的概率很小;
2、其实不是很大吧,通过划分验证集来筛选模型就好;
3、是有这种可能,不过还是实验结果出真知。
为什么变成楼中回复了呢。。。
苏神您好,我想请问你是如何进行Embedding操作的呢?我看了代码给我的感觉是,您是用的one-hot进行的字嵌入么?
你是不懂Embedding还是不懂本文的Embedding?本文就只是纯粹用了字嵌入,没什么特殊的。如果你是不懂Embedding,那么可以参考 https://kexue.fm/archives/4122
October 26th, 2018
我运行了代码,出现了这个错误:(, UnicodeEncodeError('ascii', u'Incompatible shapes: [64,1,128] vs. [64,42],
我的batch_size =64,麻烦博主看看是怎么回事
November 6th, 2018
您好,我用一个中文数据集和一个英文数据集训练之后效果都不理想。题目的可读性不好,可以方便问一下您数据集的来源吗。
http://thuctc.thunlp.org/
里边提供了一份新闻语料,第一行就是标题。
十分感谢您的分享
November 11th, 2018
苏神,我将您的代码应用到了英文文本中,以单词为单位。确实发现越到后面越慢,第3个epoch就停止了,对于您在文中O(n^2)的解释我不是很明白,不知道您能否结合代码说一下怎么把复杂度降下来呢?
我不知道你说什么意思。
我文章中说的是解码过程对于长句子是很慢的,是指预测的过程。既然是预测的过程,怎么会有“第3个epoch”的说法?如果是训练过程,训练过程跟本文所描述的并没有关系。
啊,好吧,谢谢苏神的回复。那苏神您知道训练越来越慢直到停止,可能是什么原因吗?
December 14th, 2018
最后的结果保存在weights文件?保存在h5文件中是不是更好
只保存weight的情况下没有区别。
如果你说保存整个模型(包括结构),那么随你喜欢;但不管有没有问题都不要跟我讨论,因为我反感直接保存整个模型的偷懒做法。
December 16th, 2018
您好~我运行代码后报错,请问您能帮忙解答下么!万分感谢
InvalidArgumentError (see above for traceback): No OpKernel was registered to support Op 'CudnnRNN' with these attrs. Registered devices: [CPU], Registered kernels:
[[Node: cu_dnnlstm_3/CudnnRNN = CudnnRNN[T=DT_FLOAT, direction="unidirectional", dropout=0, input_mode="linear_input", is_training=true, rnn_mode="lstm", seed=87654321, seed2=0](cu_dnnlstm_3/transpose, cu_dnnlstm_3/ExpandDims_1, cu_dnnlstm_3/ExpandDims_2, cu_dnnlstm_3/concat_1)]]
难道是我的电脑是CPU的,然后需要用GPU来并行计算么?
基本原因:你没有装CUDA和CUDNN,所以可以将CuDNNGRU换成GRU。
根本原因:能不能好好花几个月时间入门一下深度学习及其框架的基本使用方法,然后再来搞这些模型?不要看着代码想跑通就算了好不好~
呃,是的,昨晚看了keras官方文档,CuDNNLSTM这个需要在GRU上运行,但是我的电脑是集成显卡,没有独显所以出现了这个问题!因为刚刚进入NLP这个领域,所以就还在不断学习、不断摸索么!谢谢您了~
GPU,不是GRU,GPU是显卡的计算中心,GRU是一个RNN模型。
每个人都有菜鸟阶段,这无可厚非,真正不妥的地方在于:你应该好好入门,好好积累,而不是一来就跑综合性这么强的任务。
hahaha~对的,昨天打错字了~谢谢!
December 24th, 2018
苏神:
你好。最近在跑你的代码有几个想法想交流一下:
(1)摘要的话编码器词典和解码器词典一般是共享还是单独构造?我看您项目中编解码使用的是同一个词典。
(2)句子的padding长度,我看您代码中编解码的句子padding长度都是400,需不需要对于编解码来构造不同的序列padding长度,不过我考虑您后面使用mask去掉了,不知道是否有影响?
(3) q, v, v_mask = inputs
k = v
mv = K.max(v - (1. - v_mask) * 1e10, axis=1, keepdims=True) # maxpooling1d
mv = mv + K.zeros_like(q[:,:,:1]) # 将mv重复至“q的timesteps”份
# 下面几步只是实现了一个乘性attention
qw = K.dot(q, self.kernel)
a = K.batch_dot(qw, k, [2, 2]) / 10.
a -= (1. - K.permute_dimensions(v_mask, [0, 2, 1])) * 1e10
a = K.softmax(a)
o = K.batch_dot(a, v, [2, 1])
# 将各步结果拼接
return K.concatenate([o, q, mv], 2)
这部分代码我的理解是,o是ct,也就是关注的上下文向量。q为ht向量,但是mv是从v变换来的也就是x,这部分我没有看懂,也可能是我理解的不对。
写的比较长,希望得到您的回复。
您好,问了我们实验室的大神,好像明白了您的意思。将y数据处理的时候错开一位,然后再LSTM编码的时候已经隐含了yt-1和ht-1的数据,然后拼上了maxpooling的编码器的h以及attention向量,然后做softmax。不知道我这样理解对吗?
后面的理解没错。
至于是否共享embedding层,一般来说只要同一种语言之间的变换,都可以考虑共享embedding层。
嗯。我也是纠结了好久了。我看很多人做摘要的论文中是做的编码端的词典和解码端的词典,这样的缺点就是解码器能够选择的词语就比较少了。谢谢您的回复。
December 27th, 2018
苏神,再问您一个问题。
seq2seq一般都会把encoder最后的state反馈给decoder,作为decoder的Initstate。您推荐的10分钟学习seq2seq文章也是这样。我看您的程序encoder和decoder是通过attention和maxpooling的mv来使得编码器和解码器之间交互。不知道这样考虑是为了并行话吗?不初始化解码器的state会不会对性能有影响?
我这里主要是方便实现,而且看上去效果也不错,就这样搞了~
January 5th, 2019
hi,您好, 最近看到了你的文章,并仔细阅读了代码,以下是我的注解代码:
https://github.com/hkxIron/hkx_tf_practice/blob/master/tf_models/seq2seq/seq2seq.py,
看完代码后,有几点不解,感觉你的实现并非原始的seq2seq-attention, 原始作者论文为 NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE, 原论文中Si=g(S_(i-1), y_(i-1), C_i),而在代码中Si=g(s_(i-1)),只是在后面的full-connect层才用到C_i, y_(i-1),所以并非严格意义上的seq2seq-attention模型,望回复,多谢
感谢你的详细注释。
“并非原始的seq2seq-attention”,这个评价我接受,这也是事实;“并非严格意义上的seq2seq-attention”,这个我就不接受了。
谁来规定“严格的”或者“标准的”seq2seq-attention?我这样只是一种比较简单的写法,而且效果也不赖,形式上也满足encoder-decoder的设计,也确实包含了attention,怎么就不算“严格意义上的seq2seq-attention”了?
再次表示感谢。
你好,我原意是"并非原始的seq2seq-attention", 表述"并非严格意义上的seq2seq-attention"属于笔误,所以作者是不是可以在blog提一下与原始seq2seq-attention的区别,我阅读代码时就感觉有些不对劲,读完才明白的确有差别 .
基本上,我开源代码都会附带一篇文章,也就是说,我有一整篇文章(有时甚至好几篇)来作为代码的解说。如果读者非要不看文章就看代码,那我也没办法。如果看了文章,尤其是看了第一个图,我觉得并没有任何歧义~
而且,将原始的seq2seq的设计,看作是“标准的seq2seq”,其实我觉得不是一个明智的观点,甚至是一个阻碍自己理解的想法。如果这是标准,那么基于cnn的/纯attention的seq2seq很可能你就无法理解了~因为基于cnn的/纯attention的seq2seq,应该还更像我本文中的图1