






22
Oct
从梯度最大化看Attention的Scale操作
By 苏剑林 | 2023-10-22 | 67276位读者 | 引用我们知道,Scaled Dot-Product Attention的Scale因子是$\frac{1}{\sqrt{d}}$,其中$d$是$\boldsymbol{q},\boldsymbol{k}$的维度。这个Scale因子的一般解释是:如果不除以$\sqrt{d}$,那么初始的Attention就会很接近one hot分布,这会造成梯度消失,导致模型训练不起来。然而,可以证明的是,当Scale等于0时同样也会有梯度消失问题,这也就是说Scale太大太小都不行。
那么多大的Scale才适合呢?$\frac{1}{\sqrt{d}}$是最佳的Scale了吗?本文试图从梯度角度来回答这个问题。
已有结果
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经推导过标准的Scale因子$\frac{1}{\sqrt{d}}$,推导的思路很简单,假设初始阶段$\boldsymbol{q},\boldsymbol{k}\in\mathbb{R}^d$都采样自“均值为0、方差为1”的分布,那么可以算得
\begin{equation}\mathbb{V}ar[\boldsymbol{q}\cdot\boldsymbol{k}] = d\end{equation}
13
May
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
By 苏剑林 | 2024-05-13 | 68315位读者 | 引用前几天,幻方发布的DeepSeek-V2引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA(Multi-head Latent Attention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。
接下来,本文将跟大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。
MHA
MHA(Multi-Head Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种Attention形式,可以说它是当前主流LLM的基础工作。在数学上,多头注意力MHA等价于多个独立的单头注意力的拼接,假设输入的(行)向量序列为$\boldsymbol{x}_1,\boldsymbol{x}_2,\cdots,\boldsymbol{x}_l$,其中$\boldsymbol{x}_i\in\mathbb{R}^d$,那么MHA可以形式地记为
17
Apr
生成扩散模型漫谈(二十三):信噪比与大图生成(下)
By 苏剑林 | 2024-04-17 | 30145位读者 | 引用上一篇文章《生成扩散模型漫谈(二十二):信噪比与大图生成(上)》中,我们介绍了通过对齐低分辨率的信噪比来改进noise schedule,从而改善直接在像素空间训练的高分辨率图像生成(大图生成)的扩散模型效果。而这篇文章的主角同样是信噪比和大图生成,但做到了更加让人惊叹的事情——直接将训练好低分辨率图像的扩散模型用于高分辨率图像生成,不用额外的训练,并且效果和推理成本都媲美直接训练的大图模型!
这个工作出自最近的论文《Upsample Guidance: Scale Up Diffusion Models without Training》,它巧妙地将低分辨率模型上采样作为引导信号,并结合了CNN对纹理细节的平移不变性,成功实现了免训练高分辨率图像生成。
思想探讨
我们知道,扩散模型的训练目标是去噪(Denoise,也是DDPM的第一个D)。按我们的直觉,去噪这个任务应该是分辨率无关的,换句话说,理想情况下低分辨率图像训练的去噪模型应该也能用于高分辨率图像去噪,从而低分辨率的扩散模型应该也能直接用于高分辨率图像生成。
8
Aug
生成扩散模型漫谈(六):一般框架之ODE篇
By 苏剑林 | 2022-08-08 | 103416位读者 | 引用上一篇文章《生成扩散模型漫谈(五):一般框架之SDE篇》中,我们对宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》做了基本的介绍和推导。然而,顾名思义,上一篇文章主要涉及的是原论文中SDE相关的部分,而遗留了被称为“概率流ODE(Probability flow ODE)”的部分内容,所以本文对此做个补充分享。
事实上,遗留的这部分内容在原论文的正文中只占了一小节的篇幅,但我们需要新开一篇文章来介绍它,因为笔者想了很久后发现,该结果的推导还是没办法绕开Fokker-Planck方程,所以我们需要一定的篇幅来介绍Fokker-Planck方程,然后才能请主角ODE登场。
再次反思
我们来大致总结一下上一篇文章的内容:首先,我们通过SDE来定义了一个前向过程(“拆楼”):
\begin{equation}d\boldsymbol{x} = \boldsymbol{f}_t(\boldsymbol{x}) dt + g_t d\boldsymbol{w}\label{eq:sde-forward}\end{equation}
1
Mar
科学空间|Scientific Spaces 介绍
By 苏剑林 | 2009-03-01 | 396062位读者 | 引用中山大学基础数学研究生,本科为华南师范大学。93年从奥尔特星云移民地球,因忘记回家路线,遂仰望星空,希望找到时空之路。同时兼爱各种科学,热衷钻牛角尖,因此经常碰壁,但偶然把牛角钻穿,也乐在其中。偏爱物理、天文、计算机,喜欢思考,虽擅长理性分析,但也容易感情用事,崇拜Feynman。爱好阅读,没事偷懒玩玩象棋,闲时爱好进入厨房做几道小菜,偶尔也开开数据“挖掘机”。明明要学基础数学,偏偏不务正业,沉溺神经网络,妄想人工智能,曾未在ACL、AAAI、COLING等会议上发表一篇文章。近期还挣扎在NLP大坑,在科学空间(https://kexue.fm)期待大家的拯救。
历史内容
华南师范大学数学系学生。93年从奥尔特星云移民地球,因忘记回家路线,遂仰望星空,希望找到时空之路。同时兼爱各种科学,热衷钻牛角尖,因此经常碰壁,但偶然把牛角钻穿,也乐在其中。偏爱物理、天文,喜欢思考,虽擅长理性分析,但也容易感情用事,崇拜费曼。长期阅读《天文爱好者》和《环球科学》,没事偷懒玩玩象棋,闲时爱好进入厨房做几道小菜,偶尔也当当电工。近期主要学习理论物理,在科学空间期待大家的指教。
名称:科学空间|Scientific Spaces
网址:http://kexue.fm
站长:苏剑林
信念:探索我们的世界,聆听我们的自然
网站历史
2009.03.01 网站初步建立,刚开始的时候使用的是BoBlog以及宇宙驿站的空间,内容定位:科学转载。 2009.03.28 开始进行大规模推广,访问量开始提高 2009.03-05 期间进行过多次改变,特别是Blog程序的转换,内容上的改革等
7
Nov
人不能忘本|我的数学竞赛题
By 苏剑林 | 2009-11-07 | 39311位读者 | 引用
1
May
我们打算飞到小行星上——但是,哪一颗好呢?
By 苏剑林 | 2010-05-01 | 33996位读者 | 引用
漫游在太空的小行星
站长:已经很久没有翻译过科普文章了。现在再来尝试一下,依旧是“Google+金山+搜索+理解”的模式,依旧是那么烂的水平,依旧是那么差的文采,呵呵。有任何意见欢迎提出。 4月15日,美国总统巴拉克·奥巴马视察了位于佛罗里达州的肯尼迪航天中心并发表演讲,提出美国航天新计划:美国未来航天的目的地是火星和小行星,终止布什政府提出的国家载人航天飞行项目。他强有力地回击了其政策的批评者,同时呼吁私营企业铺设飞往火星的创新之路,而不是以国家之力展示美国的优势。 众所周知,载人登小行星比载人登月难多了。除了苛刻的技术条件外,适合登录的小行星也不多,奥巴马的新方案真的可行吗?让我们拭目以待!
15
Aug
《方程与宇宙》:拉格朗日点的点点滴滴(四)
By 苏剑林 | 2010-08-15 | 92106位读者 | 引用The New Calculation Of Lagrangian Point 1,2,3
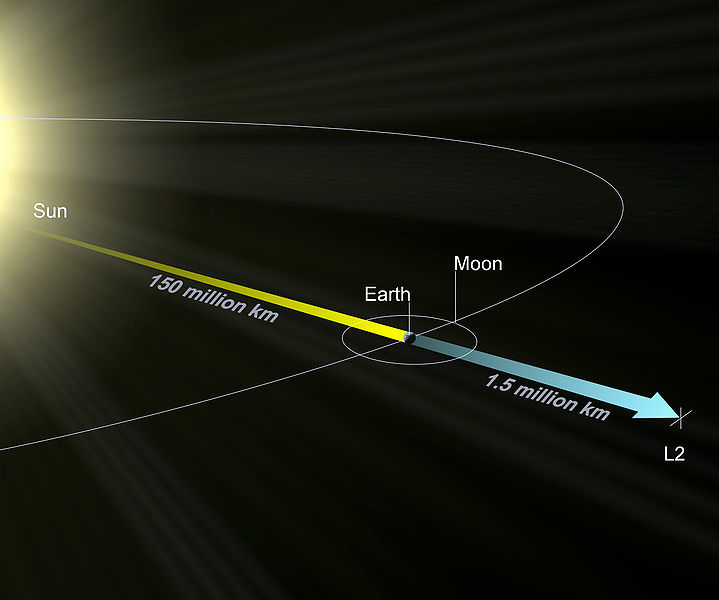
L2_rendering
关于n体问题,选择质心或其他定点为参考点,我们可以列出下面的运动方程:
$$\ddot{\vec{r}}_k=\sum_{i=1,i != k}^{n} Gm_i\frac{\vec{r}_i-\vec{r}_k}{|\vec{r}_i-\vec{r}_k|^3}\tag{19}$$
现在我们只考虑三体问题。天文学家一直希望能够找到三体问题的简洁解,可是很遗憾,庞加莱已经证明了三体问题的解是混沌的,也就是说任何微小的扰动都有可能造成不可预料的后果(可以形象的比喻为:巴西的一只蝴蝶翅膀的扇动,有可能因此美国的一场龙卷风)。

最近评论