






19
Mar
为什么需要残差?一个来自DeepNet的视角
By 苏剑林 | 2022-03-19 | 57655位读者 | 引用在《训练1000层的Transformer究竟有什么困难?》中我们介绍了微软提出的能训练1000层Transformer的DeepNet技术。而对于DeepNet,读者一般也有两种反应,一是为此感到惊叹而点赞,另一则是觉得新瓶装旧酒没意思。出现后一种反应的读者,往往是因为DeepNet所提出的两个改进点——增大恒等路径权重和降低残差分支初始化——实在过于稀松平常,并且其他工作也出现过类似的结论,因此很难有什么新鲜感。
诚然,单从结论来看,DeepNet实在算不上多有意思,但笔者觉得,DeepNet的过程远比结论更为重要,它有意思的地方在于提供了一个简明有效的梯度量级分析思路,并可以用于分析很多相关问题,比如本文要讨论的“为什么需要残差”,它就可以给出一个比较贴近本质的答案。
增量爆炸
为什么需要残差?答案是有了残差才更好训练深层模型,这里的深层可能是百层、千层甚至万层。那么问题就变成了为什么没有残差就不容易训练深层模型呢?
29
Mar
为什么Pre Norm的效果不如Post Norm?
By 苏剑林 | 2022-03-29 | 92303位读者 | 引用Pre Norm与Post Norm之间的对比是一个“老生常谈”的话题了,本博客就多次讨论过这个问题,比如文章《浅谈Transformer的初始化、参数化与标准化》、《模型优化漫谈:BERT的初始标准差为什么是0.02?》等。目前比较明确的结论是:同一设置之下,Pre Norm结构往往更容易训练,但最终效果通常不如Post Norm。Pre Norm更容易训练好理解,因为它的恒等路径更突出,但为什么它效果反而没那么好呢?
笔者之前也一直没有好的答案,直到前些时间在知乎上看到 @唐翔昊 的一个回复后才“恍然大悟”,原来这个问题竟然有一个非常直观的理解!本文让我们一起来学习一下。
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 30902位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。
30
Nov
用热传导方程来指导自监督学习
By 苏剑林 | 2022-11-30 | 29334位读者 | 引用用理论物理来卷机器学习已经不是什么新鲜事了,比如上个月介绍的《生成扩散模型漫谈(十三):从万有引力到扩散模型》就是经典一例。最近一篇新出的论文《Self-Supervised Learning based on Heat Equation》,顾名思义,用热传导方程来做(图像领域的)自监督学习,引起了笔者的兴趣。这种物理方程如何在机器学习中发挥作用?同样的思路能否迁移到NLP中?让我们一起来读读论文。
基本方程
如下图,左边是物理中热传导方程的解,右端则是CAM、积分梯度等显著性方法得到的归因热力图,可以看到两者有一定的相似之处,于是作者认为热传导方程可以作为好的视觉特征的一个重要先验。
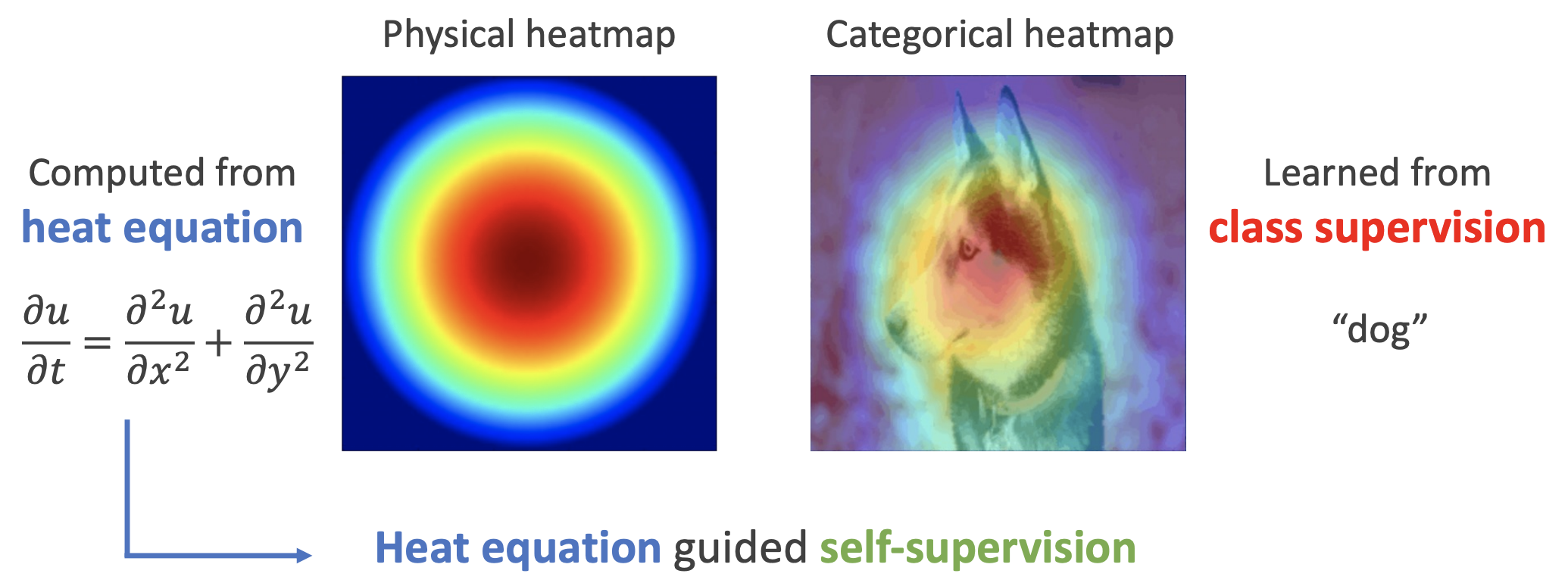
热方程的热力图(左)和视觉模型的热力图(右)
8
Jun
Naive Bayes is all you need ?
By 苏剑林 | 2023-06-08 | 43908位读者 | 引用很抱歉,起了这么个具有标题党特征的题目。在写完《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》之后,笔者就觉得朴素贝叶斯(Naive Bayes)跟Attention机制有很多相同的特征,后来再推导了一下发现,Attention机制其实可以看成是一种广义的、参数化的朴素贝叶斯。既然如此,“Attention is All You Need”不也就意味着“Naive Bayes is all you need”了?这就是本文标题的缘由。
接下来笔者将介绍自己的思考过程,分析如何从朴素贝叶斯角度来理解Attention机制。
朴素贝叶斯
本文主要考虑语言模型,它要建模的是$p(x_t|x_1,\cdots,x_{t-1})$。根据贝叶斯公式,我们有
\begin{equation}p(x_t|x_1,\cdots,x_{t-1}) = \frac{p(x_1,\cdots,x_{t-1}|x_t)p(x_t)}{p(x_1,\cdots,x_{t-1})}\propto p(x_1,\cdots,x_{t-1}|x_t)p(x_t)\end{equation}
20
Mar
《为什么现在的LLM都是Decoder-only的架构?》FAQ
By 苏剑林 | 2023-03-20 | 48984位读者 | 引用上周笔者写了《为什么现在的LLM都是Decoder-only的架构?》,总结了一下我在这个问题上的一些实验结论和猜测。果然是热点问题流量大,paperweekly的转发没多久阅读量就破万了,知乎上点赞数也不少。在几个平台上,陆陆续续收到了读者的一些意见或者疑问,总结了其中一些有代表性的问题,做成了本篇FAQ,希望能进一步帮助大家解决疑惑。
回顾
在《为什么现在的LLM都是Decoder-only的架构?》中,笔者对GPT和UniLM两种架构做了对比实验,然后结合以往的研究经历,猜测了如下结论:
1、输入部分的注意力改为双向不会带来收益,Encoder-Decoder架构的优势很可能只是源于参数翻倍;
2、双向注意力没有带来收益,可能是因为双向注意力的低秩问题导致效果下降。
所以,基于这两点推测,我们得到结论:
在同等参数量、同等推理成本下,Decoder-only架构是最优选择。
20
Jul
语言模型输出端共享Embedding的重新探索
By 苏剑林 | 2023-07-20 | 29186位读者 | 引用预训练刚兴起时,在语言模型的输出端重用Embedding权重是很常见的操作,比如BERT、第一版的T5、早期的GPT,都使用了这个操作,这是因为当模型主干部分不大且词表很大时,Embedding层的参数量很可观,如果输出端再新增一个独立的同样大小的权重矩阵的话,会导致显存消耗的激增。不过随着模型参数规模的增大,Embedding层的占比相对变小了,加之《Rethinking embedding coupling in pre-trained language models》等研究表明共享Embedding可能会有些负面影响,所以现在共享Embedding的做法已经越来越少了。
本文旨在分析在共享Embedding权重时可能遇到的问题,并探索如何更有效地进行初始化和参数化。尽管共享Embedding看起来已经“过时”,但这依然不失为一道有趣的研究题目。
26
Sep
脑洞大开:非线性RNN居然也可以并行计算?
By 苏剑林 | 2023-09-26 | 53013位读者 | 引用近年来,线性RNN由于其可并行训练以及常数推理成本等特性,吸引了一定研究人员的关注(例如笔者之前写的《Google新作试图“复活”RNN:RNN能否再次辉煌?》),这让RNN在Transformer遍地开花的潮流中仍有“一席之地”。然而,目前看来这“一席之地”只属于线性RNN,因为非线性RNN无法高效地并行训练,所以在架构之争中是“心有余而力不足”。
不过,一篇名为《Parallelizing Non-Linear Sequential Models over the Sequence Length》的论文有不同的看法,它提出了一种迭代算法,宣传可以实现非线性RNN的并行训练!真有如此神奇?接下来我们一探究竟。
求不动点
原论文对其方法做了非常一般的介绍,而且其侧重点是PDE和ODE,这里我们直接从RNN入手。考虑常见的简单非线性RNN:
\begin{equation}x_t = \tanh(Ax_{t-1} + u_t)\label{eq:rnn}\end{equation}

最近评论