






30
Oct
缅怀金庸 | 愿你登上10930小行星继续翱翔
By 苏剑林 | 2018-10-30 | 21863位读者 | 引用
金庸大师
金庸走了,享年94岁。
虽然说这些高龄大师们,不管是科学家还是文学家,他们在晚年基本上都不会有什么产出,过于理性的话会有“去了就去了,好像也没有什么损失”的感觉。然而,事实是大师的逝去总让我们有一种悲伤的震撼感,总让我们觉得似乎一个时代又逝去了。霍金是这样,金庸也是这样。
对于金老爷子来说,是一个武侠时代过去了,是一个江湖过去了。
飞雪连天射白鹿,笑书神侠倚碧鸳。
这个对联描述了金庸的14部作品,加上《越女剑》,就构成了他的15部武侠小说。金庸用这15部小说,描述了一个个活灵活现的江湖,不,说江湖好象都太小了,读完这15部作品,你会感觉他描述了整个中国几千年的历史、整个社会。
5
Dec
万能的seq2seq:基于seq2seq的阅读理解问答
By 苏剑林 | 2019-12-05 | 87106位读者 | 引用今天给bert4keras新增加了一个例子:阅读理解式问答(task_reading_comprehension_by_seq2seq.py),语料跟之前一样,都是用WebQA和SogouQA,最终的得分在0.77左右(单模型,没精调)。

用seq2seq做阅读理解的模型图示
方法简述
由于这次主要目的是给bert4keras增加demo,因此效率就不是主要关心的目标了。这次的目标主要是通用性和易用性,所以用了最万能的方案——seq2seq来实现做阅读理解。
用seq2seq做的话,基本不用怎么关心模型设计,只要把篇章和问题拼接起来,然后预测答案就行了。此外,seq2seq的方案还自然地包括了判断篇章有无答案的方法,以及自然地导出一种多篇章投票的思路。总而言之,不考虑效率的话,seq2seq做阅读理解是一种相当优雅的方案。
这次实现seq2seq还是用UNILM的方案,如果还不了解的读者,可以先阅读《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》了解相应内容。
14
Dec
基于Conditional Layer Normalization的条件文本生成
By 苏剑林 | 2019-12-14 | 113358位读者 | 引用从文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》中我们可以知道,只要配合适当的Attention Mask,Bert(或者其他Transformer模型)就可以用来做无条件生成(Language Model)和序列翻译(Seq2Seq)任务。
可如果是有条件生成呢?比如控制文本的类别,按类别随机生成文本,也就是Conditional Language Model;又比如传入一副图像,来生成一段相关的文本描述,也就是Image Caption。
相关工作
八月份的论文《Encoder-Agnostic Adaptation for Conditional Language Generation》比较系统地分析了利用预训练模型做条件生成的几种方案;九月份有一篇论文《CTRL: A Conditional Transformer Language Model for Controllable Generation》提供了一个基于条件生成来预训练的模型,不过这本质还是跟GPT一样的语言模型,只能以文字输入为条件;而最近的论文《Plug and Play Language Models: a Simple Approach to Controlled Text Generation》将$p(x|y)$转化为$p(x)p(y|x)$来探究基于预训练模型的条件生成。
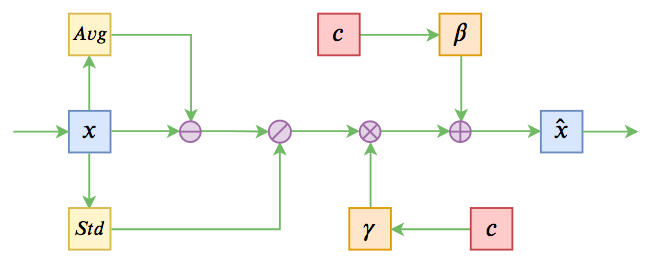
条件Normalization示意图
不过这些经典工作都不是本文要介绍的。本文关注的是以一个固定长度的向量作为条件的文本生成的场景,而方法是Conditional Layer Normalization——把条件融合到Layer Normalization的$\beta$和$\gamma$中去。

最近评论