






29
Jul
基于GRU和AM-Softmax的句子相似度模型
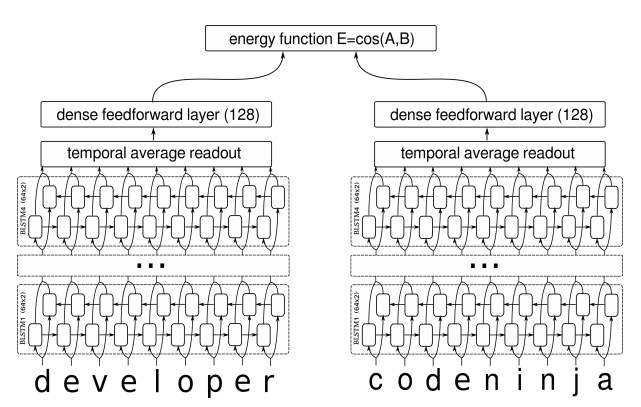
By 苏剑林 | 2018-07-29 | 331486位读者 | 引用搞计算机视觉的朋友会知道,AM-Softmax是人脸识别中的成果。所以这篇文章就是借鉴人脸识别的做法来做句子相似度模型,顺便介绍在Keras下各种margin loss的写法。
背景
细想之下会发现,句子相似度与人脸识别有很多的相似之处~
已有的做法
在我搜索到的资料中,深度学习做句子相似度模型,就只有两种做法:一是输入一对句子,然后输出一个0/1标签代表相似程度,也就是视为一个二分类问题,比如《Learning Text Similarity with Siamese Recurrent Networks》中的模型是这样的
将句子相似度视为二分类模型
包括今年拍拍贷的“魔镜杯”,也是这种格式。另外一种做法是输入一个三元组“(句子A,跟A相似的句子,跟A不相似的句子)”,然后用triplet loss的做法解决,比如文章《Applying Deep Learning To Answer Selection: A Study And An Open Task》中的做法。
这两种做法其实也可以看成是一种,本质上是一样的,只不过loss和训练方法有所差别。但是,这两种方法却都有一个很严重的问题:负样本采样严重不足,导致效果提升非常慢。
10
Jun
漫谈重参数:从正态分布到Gumbel Softmax
By 苏剑林 | 2019-06-10 | 223716位读者 | 引用最近在用VAE处理一些文本问题的时候遇到了对离散形式的后验分布求期望的问题,于是沿着“离散分布 + 重参数”这个思路一直搜索下去,最后搜到了Gumbel Softmax,从对Gumbel Softmax的学习过程中,把重参数的相关内容都捋了一遍,还学到一些梯度估计的新知识,遂记录在此。
文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。
基本概念
重参数(Reparameterization)实际上是处理如下期望形式的目标函数的一种技巧:
\begin{equation}L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\label{eq:base}\end{equation}
这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现($f(z)$对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于$z$的连续性,它对应不同的形式:
\begin{equation}\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\end{equation}
当然,离散情况下我们更喜欢将记号$z$换成$y$或者$c$。
25
Apr
将“Softmax+交叉熵”推广到多标签分类问题
By 苏剑林 | 2020-04-25 | 332202位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
一般来说,在处理常规的多分类问题时,我们会在模型的最后用一个全连接层输出每个类的分数,然后用softmax激活并用交叉熵作为损失函数。在这篇文章里,我们尝试将“Softmax+交叉熵”方案推广到多标签分类场景,希望能得到用于多标签分类任务的、不需要特别调整类权重和阈值的loss。

类别不平衡
单标签到多标签
一般来说,多分类问题指的就是单标签分类问题,即从$n$个候选类别中选$1$个目标类别。假设各个类的得分分别为$s_1,s_2,
\dots,s_n$,目标类为$t\in\{1,2,\dots,n\}$,那么所用的loss为
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_{i=1}^n e^{s_i}}= - s_t + \log \sum\limits_{i=1}^n e^{s_i}\label{eq:log-softmax}\end{equation}
这个loss的优化方向是让目标类的得分$s_t$变为$s_1,s_2,\dots,s_t$中的最大值。关于softmax的相关内容,还可以参考《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等文章。
4
Jul
线性Attention的探索:Attention必须有个Softmax吗?
By 苏剑林 | 2020-07-04 | 215726位读者 | 引用众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是$\mathcal{O}(n^2)$级别的,$n$是序列长度,所以当$n$比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到$\mathcal{O}(n\log n)$甚至$\mathcal{O}(n)$。
前几天笔者读到了论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》,了解到了线性化Attention(Linear Attention)这个探索点,继而阅读了一些相关文献,有一些不错的收获,最后将自己对线性化Attention的理解汇总在此文中。
Attention
当前最流行的Attention机制当属Scaled-Dot Attention,形式为
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\label{eq:std-att}\end{equation}
这里的$\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}$,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设$\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}$,一般场景下都有$n > d$甚至$n\gg d$(BERT base里边$d=64$)。
1
Sep
从三角不等式到Margin Softmax
By 苏剑林 | 2021-09-01 | 33248位读者 | 引用在《基于GRU和AM-Softmax的句子相似度模型》中我们介绍了AM-Softmax,它是一种带margin的softmax,通常用于用分类做检索的场景。当时通过图示的方式简单说了一下引入margin是因为“分类与排序的不等价性”,但没有比较定量地解释这种不等价性的来源。
在这篇文章里,我们来重提这个话题,从距离的三角不等式的角度来推导和理解margin的必要性。
三角不等式
平时,我们说的距离一般指比较直观的“欧氏距离”,但在数学上距离,距离又叫“度量”,它有公理化的定义,是指定义在某个集合上的二元函数$d(x,y)$,满足:
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 72098位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
7
May
多标签“Softmax+交叉熵”的软标签版本
By 苏剑林 | 2022-05-07 | 47677位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
在《将“Softmax+交叉熵”推广到多标签分类问题》中,我们提出了一个用于多标签分类的损失函数:
\begin{equation}\log \left(1 + \sum\limits_{i\in\Omega_{neg}} e^{s_i}\right) + \log \left(1 + \sum\limits_{j\in\Omega_{pos}} e^{-s_j}\right)\label{eq:original}\end{equation}
这个损失函数有着单标签分类中“Softmax+交叉熵”的优点,即便在正负类不平衡的依然能够有效工作。但从这个损失函数的形式我们可以看到,它只适用于“硬标签”,这就意味着label smoothing、mixup等技巧就没法用了。本文则尝试解决这个问题,提出上述损失函数的一个软标签版本。
巧妙联系
多标签分类的经典方案就是转化为多个二分类问题,即每个类别用sigmoid函数$\sigma(x)=1/(1+e^{-x})$激活,然后各自用二分类交叉熵损失。当正负类别极其不平衡时,这种做法的表现通常会比较糟糕,而相比之下损失$\eqref{eq:original}$通常是一个更优的选择。
11
Apr
熵不变性Softmax的一个快速推导
By 苏剑林 | 2022-04-11 | 18305位读者 | 引用在文章《从熵不变性看Attention的Scale操作》中,我们推导了一版具有熵不变性质的注意力机制:
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{\kappa \log n}{d}QK^{\top}\right)V\label{eq:a}\end{equation}
可以观察到,它主要是往Softmax里边引入了长度相关的缩放因子$\log n$来实现的。原来的推导比较繁琐,并且做了较多的假设,不利于直观理解,本文为其补充一个相对简明快速的推导。
推导过程
我们可以抛开注意力机制的背景,直接设有$s_1,s_2,\cdots,s_n\in\mathbb{R}$,定义
$$p_i = \frac{e^{\lambda s_i}}{\sum\limits_{i=1}^n e^{\lambda s_i}}$$

最近评论