






14
Aug
L2正则没有想象那么好?可能是“权重尺度偏移”惹的祸
By 苏剑林 | 2020-08-14 | 36648位读者 | 引用L2正则是机器学习常用的一种防止过拟合的方法(应该也是一道经常遇到的面试题)。简单来说,它就是希望权重的模长尽可能小一点,从而能抵御的扰动多一点,最终提高模型的泛化性能。但是读者可能也会发现,L2正则的表现通常没有理论上说的那么好,很多时候加了可能还有负作用。最近的一篇文章《Improve Generalization and Robustness of Neural Networks via Weight Scale Shifting Invariant Regularizations》从“权重尺度偏移”这个角度分析了L2正则的弊端,并提出了新的WEISSI正则项。整个分析过程颇有意思,在这里与大家分享一下。
相关内容
这一节中我们先简单回顾一下L2正则,然后介绍它与权重衰减的联系以及与之相关的AdamW优化器。
L2正则的理解
为什么要添加L2正则?这个问题可能有多个答案。有从Ridge回归角度回答的,有从贝叶斯推断角度回答的,这里给出从扰动敏感性的角度的理解。
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 69314位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。
13
Nov
也来谈谈RNN的梯度消失/爆炸问题
By 苏剑林 | 2020-11-13 | 91271位读者 | 引用尽管Transformer类的模型已经攻占了NLP的多数领域,但诸如LSTM、GRU之类的RNN模型依然在某些场景下有它的独特价值,所以RNN依然是值得我们好好学习的模型。而对于RNN梯度的相关分析,则是一个从优化角度思考分析模型的优秀例子,值得大家仔细琢磨理解。君不见,诸如“LSTM为什么能解决梯度消失/爆炸”等问题依然是目前流行的面试题之一...
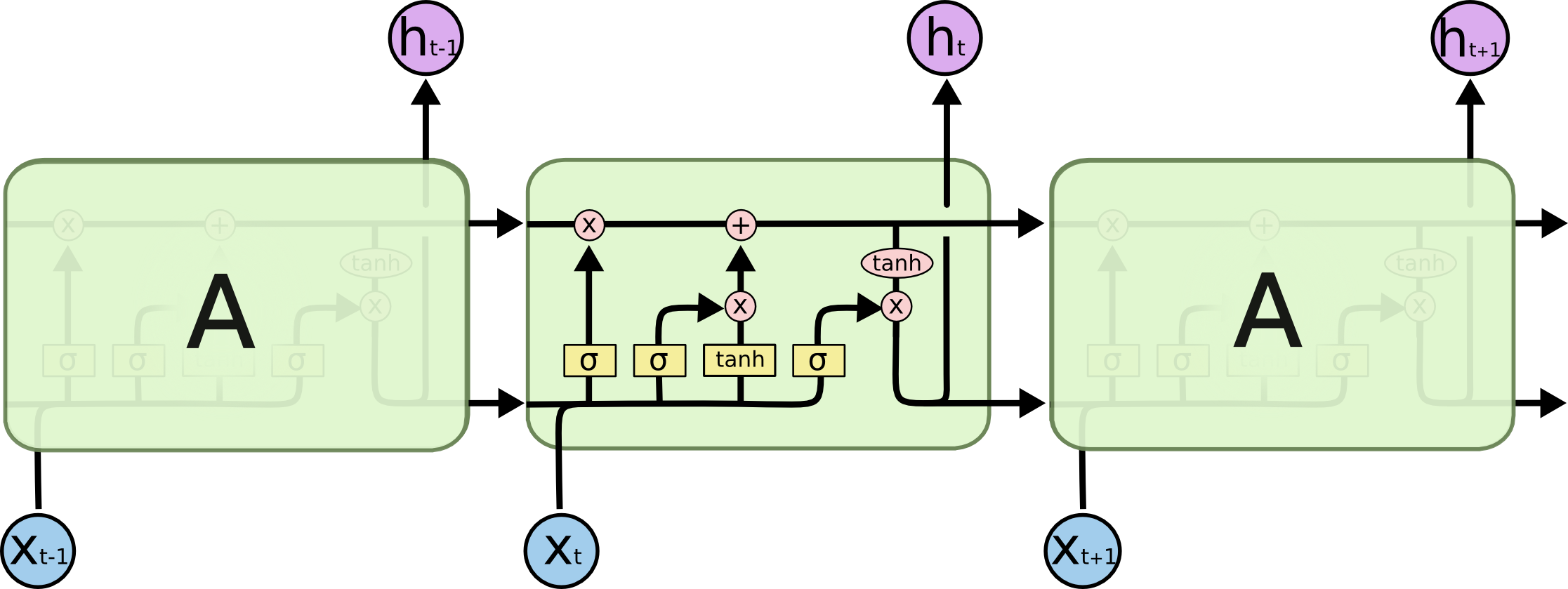
经典的LSTM
关于此类问题,已有不少网友做出过回答,然而笔者查找了一些文章(包括知乎上的部分回答、专栏以及经典的英文博客),发现没有找到比较好的答案:有些推导记号本身就混乱不堪,有些论述过程没有突出重点,整体而言感觉不够清晰自洽。为此,笔者也尝试给出自己的理解,供大家参考。
26
Jul
FlatNCE:小批次对比学习效果差的原因竟是浮点误差?
By 苏剑林 | 2021-07-26 | 46664位读者 | 引用自SimCLR在视觉无监督学习大放异彩以来,对比学习逐渐在CV乃至NLP中流行了起来,相关研究和工作越来越多。标准的对比学习的一个广为人知的缺点是需要比较大的batch_size(SimCLR在batch_size=4096时效果最佳),小batch_size的时候效果会明显降低,为此,后续工作的改进方向之一就是降低对大batch_size的依赖。那么,一个很自然的问题是:标准的对比学习在小batch_size时效果差的原因究竟是什么呢?
近日,一篇名为《Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE》对此问题作出了回答:因为浮点误差。看起来真的很让人难以置信,但论文的分析确实颇有道理,并且所提出的改进FlatNCE确实也工作得更好,让人不得不信服。
细微之处
接下来,笔者将按照自己的理解和记号来介绍原论文的主要内容。对比学习(Contrastive Learning)就不帮大家详细复习了,大体上来说,对于某个样本$x$,我们需要构建$K$个配对样本$y_1,y_2,\cdots,y_K$,其中$y_t$是正样本而其余都是负样本,然后分别给每个样本对$(x, y_i)$打分,分别记为$s_1,s_2,\cdots,s_K$,对比学习希望拉大正负样本对的得分差,通常直接用交叉熵作为损失:
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_i e^{s_i}} = \log \left(\sum_i e^{s_i}\right) - s_t = \log \left(1 + \sum_{i\neq t} e^{s_i - s_t}\right)\end{equation}
24
Aug
隐藏在动量中的梯度累积:少更新几步,效果反而更好?
By 苏剑林 | 2021-08-24 | 33364位读者 | 引用我们知道,梯度累积是在有限显存下实现大batch_size训练的常用技巧。在之前的文章《用时间换取效果:Keras梯度累积优化器》中,我们就简单介绍过梯度累积的实现,大致的思路是新增一组参数来缓存梯度,最后用缓存的梯度来更新模型。美中不足的是,新增一组参数会带来额外的显存占用。
这几天笔者在思考优化器的时候,突然意识到:梯度累积其实可以内置在带动量的优化器中!带着这个思路,笔者对优化了进行了一些推导和实验,最后还得到一个有意思但又有点反直觉的结论:少更新几步参数,模型最终效果可能会变好!
注:本文下面的结果,几乎原封不动且没有引用地出现在Google的论文《Combined Scaling for Zero-shot Transfer Learning》中,在此不做过多评价,请读者自行品评。
SGDM
在正式讨论之前,我们定义函数
\begin{equation}\chi_{t/k} = \left\{ \begin{aligned}&1,\quad t \equiv 0\,(\text{mod}\, k) \\
&0,\quad t \not\equiv 0\,(\text{mod}\, k)
\end{aligned}\right.\end{equation}
也就是说,$t$是一个整数,当它是$k$的倍数时,$\chi_{t/k}=1$,否则$\chi_{t/k}=0$,这其实就是一个$t$能否被$k$整除的示性函数。在后面的讨论中,我们将反复用到这个函数。
14
Feb
多任务学习漫谈(三):分主次之序
By 苏剑林 | 2022-02-14 | 36015位读者 | 引用多任务学习是一个很宽泛的命题,不同场景下多任务学习的目标不尽相同。在《多任务学习漫谈(一):以损失之名》和《多任务学习漫谈(二):行梯度之事》中,我们将多任务学习的目标理解为“做好每一个任务”,具体表现是“尽量平等地处理每一个任务”,我们可以称之为“平行型多任务学习”。然而,并不是所有多任务学习的目标都是如此,在很多场景下,我们主要还是想学好某一个主任务,其余任务都只是辅助,希望通过增加其他任务的学习来提升主任务的效果罢了,此类场景我们可以称为“主次型多任务学习”。
在这个背景下,如果还是沿用平行型多任务学习的“做好每一个任务”的学习方案,那么就可能会明显降低主任务的效果了。所以本文继续沿着“行梯度之事”的想法,探索主次型多任务学习的训练方案。
目标形式
在这篇文章中,我们假设读者已经阅读并且基本理解《多任务学习漫谈(二):行梯度之事》里边的思想和方法,那么在梯度视角下,让某个损失函数保持下降的必要条件是更新量与其梯度夹角至少大于90度,这是贯穿全文的设计思想。
9
Mar
训练1000层的Transformer究竟有什么困难?
By 苏剑林 | 2022-03-09 | 78462位读者 | 引用众所周知,现在的Transformer越做越大,但这个“大”通常是“宽”而不是“深”,像GPT-3虽然参数有上千亿,但也只是一个96层的Transformer模型,与我们能想象的深度相差甚远。是什么限制了Transformer往“深”发展呢?可能有的读者认为是算力,但“宽而浅”的模型所需的算力不会比“窄而深”的模型少多少,所以算力并非主要限制,归根结底还是Transformer固有的训练困难。一般的观点是,深模型的训练困难源于梯度消失或者梯度爆炸,然而实践显示,哪怕通过各种手段改良了梯度,深模型依然不容易训练。
近来的一些工作(如Admin)指出,深模型训练的根本困难在于“增量爆炸”,即模型越深对输出的扰动就越大。上周的论文《DeepNet: Scaling Transformers to 1,000 Layers》则沿着这个思路进行尺度分析,根据分析结果调整了模型的归一化和初始化方案,最终成功训练出了1000层的Transformer模型。整个分析过程颇有参考价值,我们不妨来学习一下。
增量爆炸
原论文的完整分析比较长,而且有些假设或者描述细酌之下是不够合理的。所以在本文的分享中,笔者会尽量修正这些问题,试图以一个更合理的方式来得到类似结果。
28
Apr
在bert4keras中使用混合精度和XLA加速训练
By 苏剑林 | 2022-04-28 | 27293位读者 | 引用之前笔者一直都是聚焦于模型的构思和实现,鲜有关注模型的训练加速,像混合精度和XLA这些技术,虽然也有听过,但没真正去实践过。这两天折腾了一番,成功在bert4keras中使用了混合精度和XLA来加速训练,在此做个简单的总结,供大家参考。
本文的多数经验结论并不只限于bert4keras中使用,之所以在标题中强调bert4keras,只不过bert4keras中的模型实现相对较为规整,因此启动这些加速技巧所要做的修改相对更少。
实验环境
本文的实验显卡为3090,使用的docker镜像为nvcr.io/nvidia/tensorflow:21.09-tf1-py3,其中自带的tensorflow版本为1.15.5。另外,实验所用的bert4keras版本为0.11.3。其他环境也可以参考着弄,要注意有折腾精神,不要指望着无脑调用。
顺便提一下,3090、A100等卡只能用cuda11,而tensorflow官网的1.15版本是不支持cuda11的,如果还想用tensorflow 1.x,那么只能用nvidia亲自维护的nvidia-tensorflow,或者用其构建的docker镜像。用nvidia而不是google维护的tensorflow,除了能让你在最新的显卡用上1.x版本外,还有nvidia专门做的一些额外优化,具体文档可以参考这里。

最近评论