






22
Oct
从梯度最大化看Attention的Scale操作
By 苏剑林 | 2023-10-22 | 71674位读者 | 引用我们知道,Scaled Dot-Product Attention的Scale因子是$\frac{1}{\sqrt{d}}$,其中$d$是$\boldsymbol{q},\boldsymbol{k}$的维度。这个Scale因子的一般解释是:如果不除以$\sqrt{d}$,那么初始的Attention就会很接近one hot分布,这会造成梯度消失,导致模型训练不起来。然而,可以证明的是,当Scale等于0时同样也会有梯度消失问题,这也就是说Scale太大太小都不行。
那么多大的Scale才适合呢?$\frac{1}{\sqrt{d}}$是最佳的Scale了吗?本文试图从梯度角度来回答这个问题。
已有结果
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经推导过标准的Scale因子$\frac{1}{\sqrt{d}}$,推导的思路很简单,假设初始阶段$\boldsymbol{q},\boldsymbol{k}\in\mathbb{R}^d$都采样自“均值为0、方差为1”的分布,那么可以算得
\begin{equation}\mathbb{V}ar[\boldsymbol{q}\cdot\boldsymbol{k}] = d\end{equation}
7
May
Cool Papers更新:简单搭建了一个站内检索系统
By 苏剑林 | 2024-05-07 | 42342位读者 | 引用自从《更便捷的Cool Papers打开方式:Chrome重定向扩展》之后,Cool Papers有两次比较大的变化,一次是引入了venue分支,逐步收录了一些会议历年的论文集,如ICLR、ICML等,这部分是动态人工扩充的,欢迎有心仪的会议的读者提更多需求;另一次就是本文的主题,前天新增加的站内检索功能。
本文将简单介绍一下新增功能,并对搭建站内检索系统的过程做个基本总结。
简介
在Cool Papers的首页,我们看到搜索入口:

Cool Papers(2024.05.07)
13
May
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA
By 苏剑林 | 2024-05-13 | 74925位读者 | 引用前几天,幻方发布的DeepSeek-V2引起了大家的热烈讨论。首先,最让人哗然的是1块钱100万token的价格,普遍比现有的各种竞品API便宜了两个数量级,以至于有人调侃“这个价格哪怕它输出乱码,我也会认为这个乱码是一种艺术”;其次,从模型的技术报告看,如此便宜的价格背后的关键技术之一是它新提出的MLA(Multi-head Latent Attention),这是对GQA的改进,据说能比GQA更省更好,也引起了读者的广泛关注。
接下来,本文将跟大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。
MHA
MHA(Multi-Head Attention),也就是多头注意力,是开山之作《Attention is all you need》所提出的一种Attention形式,可以说它是当前主流LLM的基础工作。在数学上,多头注意力MHA等价于多个独立的单头注意力的拼接,假设输入的(行)向量序列为$\boldsymbol{x}_1,\boldsymbol{x}_2,\cdots,\boldsymbol{x}_l$,其中$\boldsymbol{x}_i\in\mathbb{R}^d$,那么MHA可以形式地记为
8
Apr
生成扩散模型漫谈(二十二):信噪比与大图生成(上)
By 苏剑林 | 2024-04-08 | 48911位读者 | 引用盘点主流的图像扩散模型作品,我们会发现一个特点:当前多数做高分辨率图像生成(下面简称“大图生成”)的工作,都是先通过Encoder变换到Latent空间进行的(即LDM,Latent Diffusion Model),直接在原始Pixel空间训练的扩散模型,大多数分辨率都不超过64*64,而恰好,LDM通过AutoEncoder变换后的Latent,大小通常也不超过64*64。这就自然引出了一系列问题:扩散模型是不是对于高分辨率生成存在固有困难?能否在Pixel空间直接生成高分辨率图像?
论文《Simple diffusion: End-to-end diffusion for high resolution images》尝试回答了这个问题,它通过“信噪比”分析了大图生成的困难,并以此来优化noise schdule,同时提出只需在最低分辨率feature上对架构进行scale up、多尺度Loss等技巧来保证训练效率和效果,这些改动使得原论文成功在Pixel空间上训练了分辨率高达1024*1024的图像扩散模型。
29
May
Transformer升级之路:18、RoPE的底数选择原则
By 苏剑林 | 2024-05-29 | 144261位读者 | 引用我们知道,在RoPE中频率的计算公式为$\theta_i = b^{-2i/d}$,底数$b$默认值为10000。目前Long Context的主流做法之一是,先在$b=10000$上用短文本预训练,然后调大$b$并在长文本微调,其出发点是《Transformer升级之路:10、RoPE是一种β进制编码》里介绍的NTK-RoPE,它本身有较好长度外推性,换用更大的$b$再微调相比不加改动的微调,起始损失更小,收敛也更快。该过程给人的感觉是:调大$b$完全是因为“先短后长”的训练策略,如果一直都用长文本训练似乎就没必要调大$b$了?
上周的论文《Base of RoPE Bounds Context Length》试图回答这个问题,它基于一个期望性质研究了$b$的下界,由此指出更大的训练长度本身就应该选择更大的底数,与训练策略无关。整个分析思路颇有启发性,接下来我们一起来品鉴一番。
14
Jun
通向概率分布之路:盘点Softmax及其替代品
By 苏剑林 | 2024-06-14 | 28580位读者 | 引用不论是在基础的分类任务中,还是如今无处不在的注意力机制中,概率分布的构建都是一个关键步骤。具体来说,就是将一个$n$维的任意向量,转换为一个$n$元的离散型概率分布。众所周知,这个问题的标准答案是Softmax,它是指数归一化的形式,相对来说比较简单直观,同时也伴有很多优良性质,从而成为大部分场景下的“标配”。
尽管如此,Softmax在某些场景下也有一些不如人意之处,比如不够稀疏、无法绝对等于零等,因此很多替代品也应运而生。在这篇文章中,我们将简单总结一下Softmax的相关性质,并盘点和对比一下它的部分替代方案。
Softmax回顾
首先引入一些通用记号:$\boldsymbol{x} = (x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$是需要转为概率分布的$n$维向量,它的分量可正可负,也没有限定的上下界。$\Delta^{n-1}$定义为全体$n$元离散概率分布的集合,即
\begin{equation}\Delta^{n-1} = \left\{\boldsymbol{p}=(p_1,p_2,\cdots,p_n)\left|\, p_1,p_2,\cdots,p_n\geq 0,\sum_{i=1}^n p_i = 1\right.\right\}\end{equation}
之所以标注$n-1$而不是$n$,是因为约束$\sum\limits_{i=1}^n p_i = 1$定义了$n$维空间中的一个$n-1$维子平面,再加上$p_i\geq 0$的约束,$(p_1,p_2,\cdots,p_n)$的集合就只是该平面的一个子集,即实际维度只有$n-1$。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 24489位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
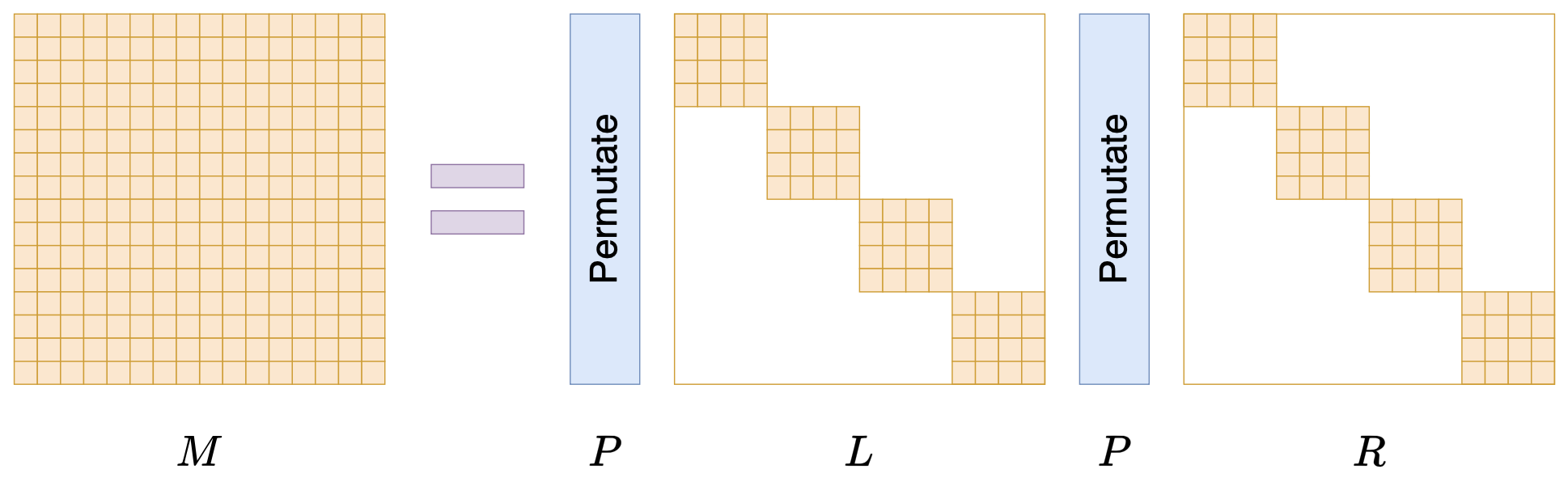
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
6
Aug
通向最优分布之路:概率空间的最小化
By 苏剑林 | 2024-08-06 | 19451位读者 | 引用当要求函数的最小值时,我们通常会先求导函数然后寻找其零点,比较幸运的情况下,这些零点之一正好是原函数的最小值点。如果是向量函数,则将导数改为梯度并求其零点。当梯度零点不易求得时,我们可以使用梯度下降来逐渐逼近最小值点。
以上这些都是无约束优化的基础结果,相信不少读者都有所了解。然而,本文的主题是概率空间中的优化,即目标函数的输入是一个概率分布,这类目标的优化更为复杂,因为它的搜索空间不再是无约束的,如果我们依旧去求解梯度零点或者执行梯度下降,所得结果未必能保证是一个概率分布。因此,我们需要寻找一种新的分析和计算方法,以确保优化结果能够符合概率分布的特性。
对此,笔者一直以来也感到颇为头疼,所以近来决定”痛定思痛“,针对概率分布的优化问题系统学习了一番,最后将学习所得整理在此,供大家参考。

最近评论