






15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 438852位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。
16
Mar
现在可以用Keras玩中文GPT2了(GPT2_ML)
By 苏剑林 | 2020-03-16 | 95418位读者 | 引用前段时间留意到有大牛开源了一个中文的GPT2模型,是最大的15亿参数规模的,看作者给的demo,生成效果还是蛮惊艳的,就想着加载到自己的bert4keras来玩玩。不过早期的bert4keras整体架构写得比较“死”,集成多个不同的模型很不方便。前两周终于看不下去了,把bert4keras的整体结构重写了一遍,现在的bert4keras总能算比较灵活地编写各种Transformer结构的模型了,比如GPT2、T5等都已经集成在里边了。
GPT2科普
GPT,相信很多读者都听说过它了,简单来说,它就是一个基于Transformer结构的语言模型,源自论文《GPT:Improving Language Understanding by Generative Pre-Training》,但它又不是为了做语言模型而生,它是通过语言模型来预训练自身,然后在下游任务微调,提高下游任务的表现。它是“Transformer + 预训练 + 微调”这种模式的先驱者,相对而言,BERT都算是它的“后辈”,而GPT2,则是GPT的升级版——模型更大,训练数据更多——模型最大版的参数量达到了15亿。
18
Jul
用变分推断统一理解生成模型(VAE、GAN、AAE、ALI)
By 苏剑林 | 2018-07-18 | 352403位读者 | 引用前言:我小学开始就喜欢纯数学,后来也喜欢上物理,还学习过一段时间的理论物理,直到本科毕业时,我才慢慢进入机器学习领域。所以,哪怕在机器学习领域中,我的研究习惯还保留着数学和物理的风格:企图从最少的原理出发,理解、推导尽可能多的东西。这篇文章是我这个理念的结果之一,试图以变分推断作为出发点,来统一地理解深度学习中的各种模型,尤其是各种让人眼花缭乱的GAN。本文已经挂到arxiv上,需要读英文原稿的可以移步到《Variational Inference: A Unified Framework of Generative Models and Some Revelations》。
下面是文章的介绍。其实,中文版的信息可能还比英文版要稍微丰富一些,原谅我这蹩脚的英语...
摘要:本文从一种新的视角阐述了变分推断,并证明了EM算法、VAE、GAN、AAE、ALI(BiGAN)都可以作为变分推断的某个特例。其中,论文也表明了标准的GAN的优化目标是不完备的,这可以解释为什么GAN的训练需要谨慎地选择各个超参数。最后,文中给出了一个可以改善这种不完备性的正则项,实验表明该正则项能增强GAN训练的稳定性。
近年来,深度生成模型,尤其是GAN,取得了巨大的成功。现在我们已经可以找到数十个乃至上百个GAN的变种。然而,其中的大部分都是凭着经验改进的,鲜有比较完备的理论指导。
本文的目标是通过变分推断来给这些生成模型建立一个统一的框架。首先,本文先介绍了变分推断的一个新形式,这个新形式其实在博客以前的文章中就已经介绍过,它可以让我们在几行字之内导出变分自编码器(VAE)和EM算法。然后,利用这个新形式,我们能直接导出GAN,并且发现标准GAN的loss实则是不完备的,缺少了一个正则项。如果没有这个正则项,我们就需要谨慎地调整超参数,才能使得模型收敛。
3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 414280位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
20
Aug
开源一版DGCNN阅读理解问答模型(Keras版)
By 苏剑林 | 2019-08-20 | 74117位读者 | 引用去年写过《基于CNN的阅读理解式问答模型:DGCNN》,介绍了一个纯卷积的简单的问答模型。当时是用Tensorflow实现的,而且没有开源,这几天抽空用Keras复现了一下,决定开源。
模型综述
关于DGCNN的基本介绍,这里不再赘述。本文的模型并不是之前模型的重复实现,而是有所改动,这里只介绍一下被改动的地方。
1、这里放出的模型,线下验证集的分数大概是0.72(之前大约是0.75);
2、本次模型以字为单位,使用笔者之前探索出来的“字词混合Embedding”(之前是以词为单位);
3、本次模型完全去掉了人工特征(之前用了8个人工特征);
4、本次模型去掉了位置Embedding(之前将位置Embedding拼接到输入上);
5、模型架构和训练细节有所微调。
7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 104711位读者 | 引用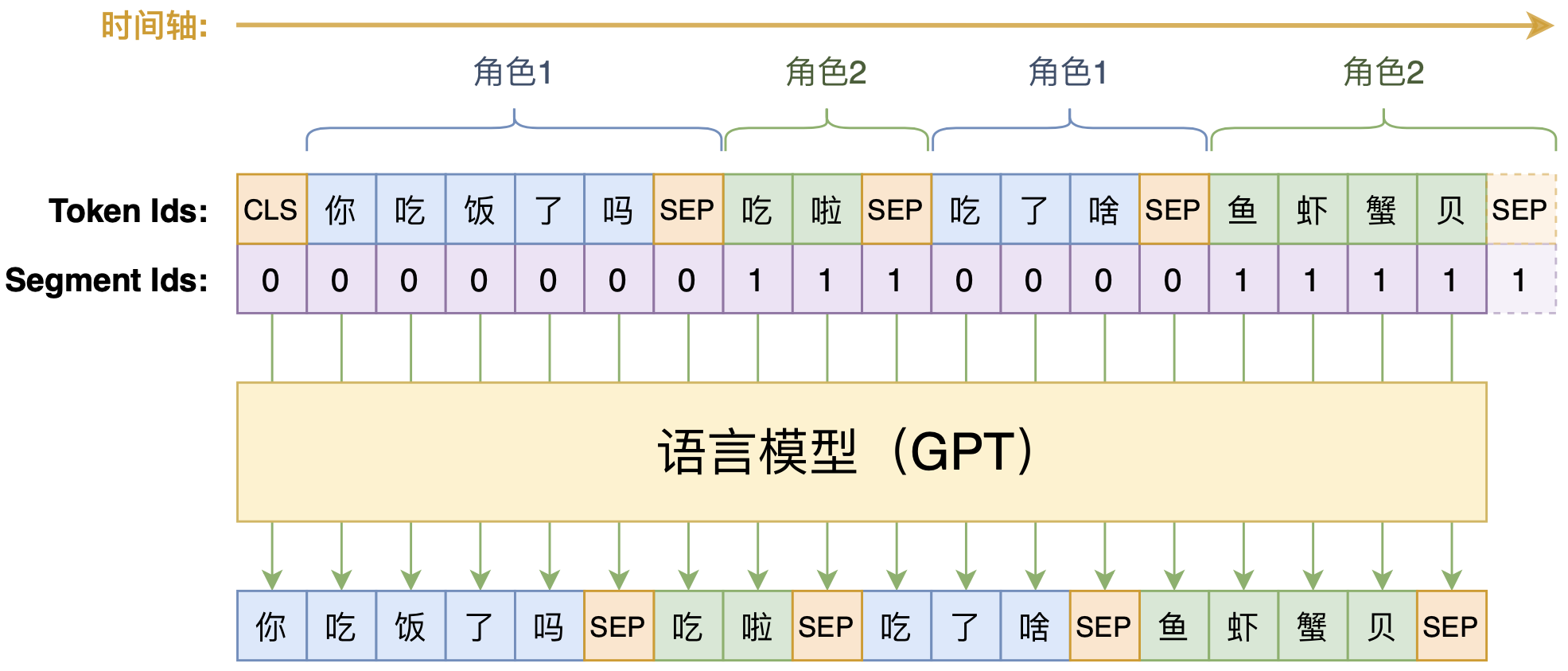
22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 66584位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。
27
Feb
配置不同的学习率,LoRA还能再涨一点?
By 苏剑林 | 2024-02-27 | 47570位读者 | 引用LoRA(Low-Rank Adaptation)是当前LLM的参数高效微调手段之一,此前我们在《梯度视角下的LoRA:简介、分析、猜测及推广》也有过简单讨论。这篇文章我们来学习LoRA的一个新结论:
给LoRA的两个矩阵分配不同的学习率,LoRA的效果还能进一步提升。
该结论出自最近的论文《LoRA+: Efficient Low Rank Adaptation of Large Models》(下称“LoRA+”)。咋看之下,该结论似乎没有什么特别的,因为配置不同的学习率相当于引入了新的超参数,通常来说只要引入并精调超参数都会有提升。“LoRA+”的特别之处在于,它从理论角度肯定了这个必要性,并且断定最优解必然是右矩阵的学习率大于左矩阵的学习率。简而言之,“LoRA+”称得上是理论指导训练并且在实践中确实有效的经典例子,值得仔细学习一番。
结论简析
假设预训练参数为$W_0 \in \mathbb{R}^{n\times m}$,如果使用全量参数微调,那么增量也是一个$n\times m$矩阵。为了降低参数量,LoRA将更新量约束为低秩矩阵,即设$W=W_0 + AB$,其中$A\in\mathbb{R}^{n\times r},B\in\mathbb{R}^{r\times m}$以及有$r\ll \min(n,m)$,用新的$W$替换模型原有参数,然后固定$W_0$不变,训练的时候只更新$A,B$,如下图所示:
$$\style{display: inline-block; width: 24ex; padding: 10ex 0; border: 1px solid #6C8EBF; background-color: #DAE8FC}{W_0\in\mathbb{R}^{n\times m}} \quad + \quad \style{display: inline-block; width: 8ex; padding: 10ex 0; border: 1px solid #D79B00; background-color: #FFE6CC}{A\in\mathbb{R}^{n\times r}}\quad\times\quad \style{display: inline-block; width: 24ex; padding: 3ex 0; border: 1px solid #D79B00; background-color: #FFE6CC}{B\in\mathbb{R}^{r\times m}}$$

最近评论