






9
Mar
训练1000层的Transformer究竟有什么困难?
By 苏剑林 | 2022-03-09 | 78384位读者 | 引用众所周知,现在的Transformer越做越大,但这个“大”通常是“宽”而不是“深”,像GPT-3虽然参数有上千亿,但也只是一个96层的Transformer模型,与我们能想象的深度相差甚远。是什么限制了Transformer往“深”发展呢?可能有的读者认为是算力,但“宽而浅”的模型所需的算力不会比“窄而深”的模型少多少,所以算力并非主要限制,归根结底还是Transformer固有的训练困难。一般的观点是,深模型的训练困难源于梯度消失或者梯度爆炸,然而实践显示,哪怕通过各种手段改良了梯度,深模型依然不容易训练。
近来的一些工作(如Admin)指出,深模型训练的根本困难在于“增量爆炸”,即模型越深对输出的扰动就越大。上周的论文《DeepNet: Scaling Transformers to 1,000 Layers》则沿着这个思路进行尺度分析,根据分析结果调整了模型的归一化和初始化方案,最终成功训练出了1000层的Transformer模型。整个分析过程颇有参考价值,我们不妨来学习一下。
增量爆炸
原论文的完整分析比较长,而且有些假设或者描述细酌之下是不够合理的。所以在本文的分享中,笔者会尽量修正这些问题,试图以一个更合理的方式来得到类似结果。
7
Jun
相对位置编码Transformer的一个理论缺陷与对策
By 苏剑林 | 2022-06-07 | 94991位读者 | 引用位置编码是Transformer中很重要的一环,在《让研究人员绞尽脑汁的Transformer位置编码》中我们就总结了一些常见的位置编码设计。大体上,我们将Transformer的位置编码分为“绝对位置编码”和“相对位置编码”两类,其中“相对位置编码”在众多NLP/CV的实验表现相对来说更加好些。
然而,我们可以发现,目前相对位置编码几乎都是在Softmax之前的Attention矩阵上进行操作的,这种施加方式实际上都存在一个理论上的缺陷,使得Transformer无法成为“万能拟合器”。本文就来分析这个问题,并探讨一些解决方案。
简单探针
顾名思义,位置编码就是用来给模型补充上位置信息的。那么,如何判断一个模型有没有足够的识别位置的能力呢?笔者之前曾构思过一个简单的探针实验:
对于一个有识别位置能力的模型,应该有能力准确实现如下映射 \begin{equation}\begin{array}{lc} \text{输入:} & [0, 0, \cdots, 0, 0] \\ & \downarrow\\ \text{输出:} & [1, 2, \cdots, n-1, n] \end{array}\end{equation}
8
Jul
“闭门造车”之多模态思路浅谈(二):自回归
By 苏剑林 | 2024-07-08 | 54763位读者 | 引用这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。
在前文《“闭门造车”之多模态思路浅谈(一):无损输入》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重的信息损失,所以更有前景或者说更长远的方案应该是输入连续型特征,比如直接将图像的原始像素特征Patchify后输入到模型中。
然而,连续型输入对于图像理解自然简单,但对图像生成来说则引入了额外的困难,因为非离散化无法直接套用文本的自回归框架,多少都要加入一些新内容如扩散,这就引出了本文的主题——如何进行多模态的自回归学习与生成。当然,非离散化只是表面的困难,更艰巨的部份还在后头...
无损含义
首先我们再来明确一下无损的含义。无损并不是指整个计算过程中一丁点损失都不能有,这不现实,也不符合我们所理解的深度学习的要义——在2015年的文章《闲聊:神经网络与深度学习》我们就提到过,深度学习成功的关键是信息损失。所以,这里无损的含义很简单,单纯是希望作为模型的输入来说尽可能无损。
7
Aug
修改Transformer结构,设计一个更快更好的MLM模型
By 苏剑林 | 2020-08-07 | 54969位读者 | 引用大家都知道,MLM(Masked Language Model)是BERT、RoBERTa的预训练方式,顾名思义,就是mask掉原始序列的一些token,然后让模型去预测这些被mask掉的token。随着研究的深入,大家发现MLM不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载BERT的MLM权重就可以当作UniLM来做Seq2Seq任务(参考这里),又比如发表在ACL 2020的《Spelling Error Correction with Soft-Masked BERT》将MLM模型用于文本纠错。
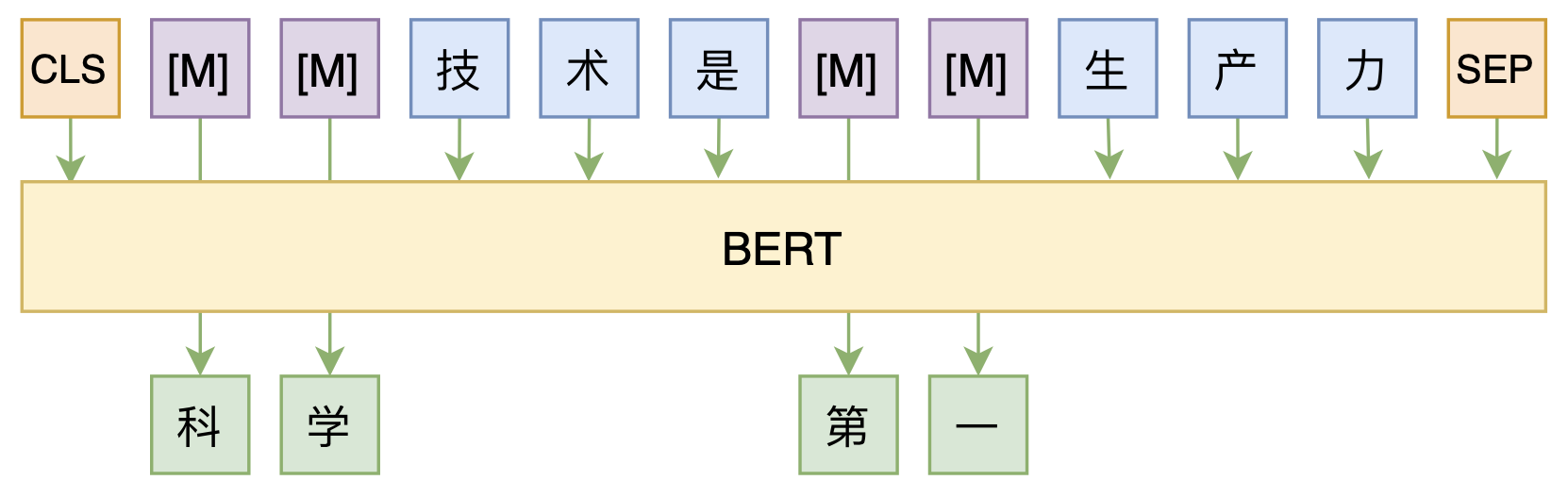
MLM任务示意图
然而,仔细读过BERT的论文或者亲自尝试过的读者应该都知道,原始的MLM的训练效率是比较低的,因为每次只能mask掉一小部分的token来训练。ACL 2020的论文《Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning》也思考了这个问题,并且提出了一种新的MLM模型设计,能够有更高的训练效率和更好的效果。
8
Oct
预训练一下,Transformer的长序列成绩还能涨不少!
By 苏剑林 | 2023-10-08 | 37802位读者 | 引用作为LLM的主流模型架构,Transformer在各类任务上的总体表现都出色,大多数情况下,Transformer的槽点只是它的平方复杂度,而不是效果——除了一个名为Long Range Arena(下面简称LRA)的Benchmark。一直以来,LRA一直是线性RNN类模型的“主场”,与之相比Transformer在上面有明显的差距,以至于让人怀疑这是否就是Transformer的固有缺陷。
不过,近日论文《Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors》将这“缺失的一环”给补齐了。论文指出,缺乏预训练是Transformer在LRA上效果较差的主要原因,而所有架构都可以通过预训练获得一定的提升,Transformer的提升则更为明显。
旧背景
Long Range Arena(LRA)是长序列建模的一个Benchmark,提出自论文《Long Range Arena: A Benchmark for Efficient Transformers》,从论文标题就可以看出,LRA是为了测试各种Efficient版的Transformer而构建的,里边包含了多种类型的数据,序列长度从1k到16k不等,此前不少Efficient Transformer的工作也都在LRA进行了测试。虽然在代表性方面有些争议,但LRA依然不失为一个测试Efficient Transformer的长序列能力的经典Benchmark。
16
Oct
Cool Papers浏览器扩展升级至v0.2.0
By 苏剑林 | 2024-10-16 | 19633位读者 | 引用年初,我们在《更便捷的Cool Papers打开方式:Chrome重定向扩展》中发布了一个Chrome浏览器插件(Cool Papers Redirector v0.1.0),可以通过右击菜单从任意页面中重定向到Cool Papers中,让大家更方便地获取Kimi对论文的理解。前几天我们把该插件升级到了v0.2.0,并顺利上架到了Chrome应用商店中,遂在此向大家推送一下。
更新汇总
相比旧版v0.1.0,当前版v0.2.0的主要更新内容如下:
1、右键菜单跳转改为在新标签页打开;
2、右键菜单支持同时访问多个论文ID;
3、右键菜单支持PDF页面;
4、右键菜单新增更多论文源(arXiv、OpenReview、ACL、IJCAI、PMLR);
5、右键菜单在搜索不到论文ID时,转入站内搜索(即划词搜索);
6、在某些网站的适当位置插入快捷跳转链接(arXiv、OpenReview,ACL)。
7
Feb
年三十折腾极路由之SSH反向代理
By 苏剑林 | 2016-02-07 | 61761位读者 | 引用
猴年快乐!
今天是年三十了,这里简单祝大家除夕快乐,新年快乐!愿大家在新的一年里都晋升为学神。^_^
这两天主要在折腾家里的路由器。平时家里只有爸妈两人,所以为了节省,家里只是通过中继隔壁家的网络来上网。本来家里用小米路由器mini,可是小米mini中继模式下功能限制非常多,我又不想刷第三方固件(因为这样会失去app控制功能,不是很方便),所以干脆换了个极路由3。极路由在中继模式下仍然保留了大部分功能(我觉得这样才是正常的,我不理解小米mini在中继之后就没了那么多功能究竟是什么逻辑)。
作为折腾派,一个新路由到手,总有很多东西要配置,极路由本身是基于openwrt的,因此可玩性也很强。首先要完成中继,然后上网,这个很简单就不多说了。其次是获得ssh权限,在极路由那里叫做“申请开发者模式”,或者叫root(感觉极路由想做路由界的苹果,但是在如今这个时代,苹果当初那种发展模式估计很难发展起来了),这个步骤也不难,不过申请之后就会失去极路由的保修资格(不理解这是什么逻辑)。
本文主要介绍了怎么在openwrt(极路由)上安装python,以及建立SSH反向代理(实现内网穿透)。

最近评论