






24
Dec
概率分布的熵归一化(Entropy Normalization)
By 苏剑林 | 2021-12-24 | 48995位读者 | 引用在上一篇文章《从熵不变性看Attention的Scale操作》中,我们从熵不变性的角度推导了一个新的Attention Scale,并且实验显示具有熵不变性的新Scale确实能使得Attention的外推性能更好。这时候笔者就有一个很自然的疑问:
有没有类似L2 Normalization之类的操作,可以直接对概率分布进行变换,使得保持原始分布主要特性的同时,让它的熵为指定值?
笔者带着疑问搜索了一番,发现没有类似的研究,于是自己尝试推导了一下,算是得到了一个基本满意的结果,暂称为“熵归一化(Entropy Normalization)”,记录在此,供有需要的读者参考。
幂次变换
首先,假设$n$元分布$(p_1,p_2,\cdots,p_n)$,它的熵定义为
\begin{equation}\mathcal{H} = -\sum_i p_i \log p_i = \mathbb{E}[-\log p_i]\end{equation}
18
May
当BERT-whitening引入超参数:总有一款适合你
By 苏剑林 | 2022-05-18 | 39894位读者 | 引用在《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者提出了BERT-whitening,验证了一个线性变换就能媲美当时的SOTA方法BERT-flow。此外,BERT-whitening还可以对句向量进行降维,带来更低的内存占用和更快的检索速度。然而,在《无监督语义相似度哪家强?我们做了个比较全面的评测》中我们也发现,whitening操作并非总能带来提升,有些模型本身就很贴合任务(如经过有监督训练的SimBERT),那么额外的whitening操作往往会降低效果。
为了弥补这个不足,本文提出往BERT-whitening中引入了两个超参数,通过调节这两个超参数,我们几乎可以总是获得“降维不掉点”的结果。换句话说,即便是原来加上whitening后效果会下降的任务,如今也有机会在降维的同时获得相近甚至更好的效果了。
方法概要
目前BERT-whitening的流程是:
\begin{equation}\begin{aligned}
\tilde{\boldsymbol{x}}_i =&\, (\boldsymbol{x}_i - \boldsymbol{\mu})\boldsymbol{U}\boldsymbol{\Lambda}^{-1/2} \\
\boldsymbol{\mu} =&\, \frac{1}{N}\sum\limits_{i=1}^N \boldsymbol{x}_i \\
\boldsymbol{\Sigma} =&\, \frac{1}{N}\sum\limits_{i=1}^N (\boldsymbol{x}_i - \boldsymbol{\mu})^{\top}(\boldsymbol{x}_i - \boldsymbol{\mu}) = \boldsymbol{U}\boldsymbol{\Lambda}\boldsymbol{U}^{\top} \,\,(\text{SVD分解})
\end{aligned}\end{equation}
19
Jul
生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪
By 苏剑林 | 2022-07-19 | 142023位读者 | 引用到目前为止,笔者给出了生成扩散模型DDPM的两种推导,分别是《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中的通俗类比方案和《生成扩散模型漫谈(二):DDPM = 自回归式VAE》中的变分自编码器方案。两种方案可谓各有特点,前者更为直白易懂,但无法做更多的理论延伸和定量理解,后者理论分析上更加完备一些,但稍显形式化,启发性不足。
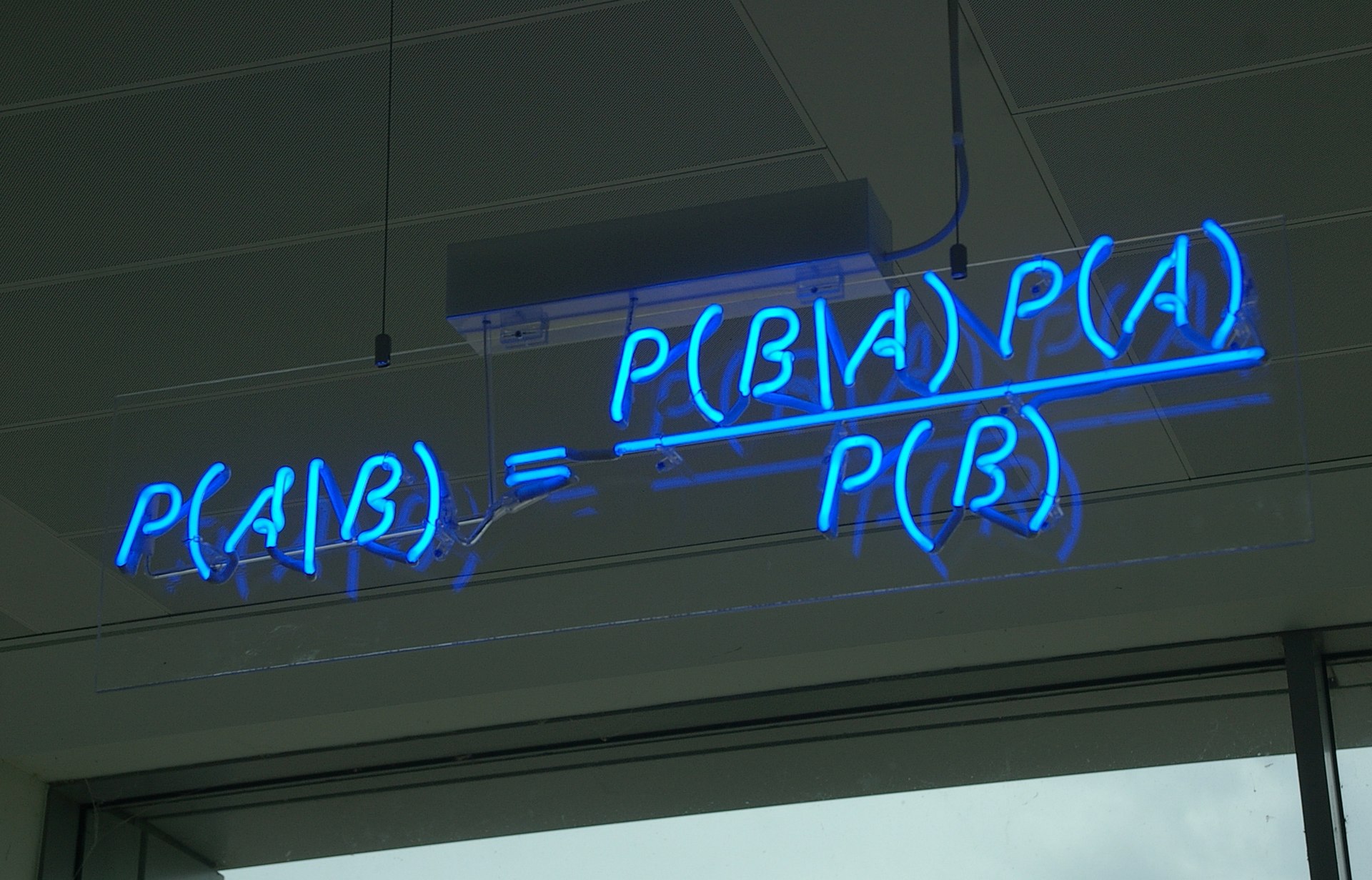
贝叶斯定理(来自维基百科)
在这篇文章中,我们再分享DDPM的一种推导,它主要利用到了贝叶斯定理来简化计算,整个过程的“推敲”味道颇浓,很有启发性。不仅如此,它还跟我们后面将要介绍的DDIM模型有着紧密的联系。
28
Jun
“维度灾难”之Hubness现象浅析
By 苏剑林 | 2022-06-28 | 39505位读者 | 引用这几天读到论文《Exploring and Exploiting Hubness Priors for High-Quality GAN Latent Sampling》,了解到了一个新的名词“Hubness现象”,说的是高维空间中的一种聚集效应,本质上是“维度灾难”的体现之一。论文借助Hubness的概念得到了一个提升GAN模型生成质量的方案,看起来还蛮有意思。所以笔者就顺便去学习了一下Hubness现象的相关内容,记录在此,供大家参考。
坍缩的球
“维度灾难”是一个很宽泛的概念,所有在高维空间中与相应的二维、三维空间版本出入很大的结论,都可以称之为“维度灾难”,比如《n维空间下两个随机向量的夹角分布》中介绍的“高维空间中任何两个向量几乎都是垂直的”。其中,有不少维度灾难现象有着同一个源头——“高维空间单位球与其外切正方体的体积之比逐渐坍缩至0”,包括本文的主题“Hubness现象”亦是如此。
12
Aug
生成扩散模型漫谈(七):最优扩散方差估计(上)
By 苏剑林 | 2022-08-12 | 77603位读者 | 引用对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈(二):DDPM = 自回归式VAE》我们提到,DDPM分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中的DDIM则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为0的DDIM的生成效果普遍差于方差非0的DDPM;而《生成扩散模型漫谈(五):一般框架之SDE篇》显示前、反向SDE的方差应该是一致的,但这原则上在$\Delta t\to 0$时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。
3
Aug
生成扩散模型漫谈(五):一般框架之SDE篇
By 苏剑林 | 2022-08-03 | 196924位读者 | 引用在写生成扩散模型的第一篇文章时,就有读者在评论区推荐了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,可以说该论文构建了一个相当一般化的生成扩散模型理论框架,将DDPM、SDE、ODE等诸多结果联系了起来。诚然,这是一篇好论文,但并不是一篇适合初学者的论文,里边直接用到了随机微分方程(SDE)、Fokker-Planck方程、得分匹配等大量结果,上手难度还是颇大的。
不过,在经过了前四篇文章的积累后,现在我们可以尝试去学习一下这篇论文了。在接下来的文章中,笔者将尝试从尽可能少的理论基础出发,尽量复现原论文中的推导结果。
随机微分
在DDPM中,扩散过程被划分为了固定的$T$步,还是用《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》的类比来说,就是“拆楼”和“建楼”都被事先划分为了$T$步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。
14
Sep
生成扩散模型漫谈(十):统一扩散模型(理论篇)
By 苏剑林 | 2022-09-14 | 72974位读者 | 引用老读者也许会发现,相比之前的更新频率,这篇文章可谓是“姗姗来迟”,因为这篇文章“想得太多”了。
通过前面九篇文章,我们已经对生成扩散模型做了一个相对全面的介绍。虽然理论内容很多,但我们可以发现,前面介绍的扩散模型处理的都是连续型对象,并且都是基于正态噪声来构建前向过程。而“想得太多”的本文,则希望能够构建一个能突破以上限制的扩散模型统一框架(Unified Diffusion Model,UDM):
1、不限对象类型(可以是连续型$\boldsymbol{x}$,也可以是离散型的$\boldsymbol{x}$);
2、不限前向过程(可以用加噪、模糊、遮掩、删减等各种变换构建前向过程);
3、不限时间类型(可以是离散型的$t$,也可以是连续型的$t$);
4、包含已有结果(可以推出前面的DDPM、DDIM、SDE、ODE等结果)。
这是不是太过“异想天开”了?有没有那么理想的框架?本文就来尝试一下。
21
Sep
生成扩散模型漫谈(十一):统一扩散模型(应用篇)
By 苏剑林 | 2022-09-21 | 45054位读者 | 引用在《生成扩散模型漫谈(十):统一扩散模型(理论篇)》中,笔者自称构建了一个统一的模型框架(Unified Diffusion Model,UDM),它允许更一般的扩散方式和数据类型。那么UDM框架究竟能否实现如期目的呢?本文通过一些具体例子来演示其一般性。
框架回顾
首先,UDM通过选择噪声分布$q(\boldsymbol{\varepsilon})$和变换$\boldsymbol{\mathcal{F}}$来构建前向过程
\begin{equation}\boldsymbol{x}_t = \boldsymbol{\mathcal{F}}_t(\boldsymbol{x}_0,\boldsymbol{\varepsilon}),\quad \boldsymbol{\varepsilon}\sim q(\boldsymbol{\varepsilon})\end{equation}
然后,通过如下的分解来实现反向过程$\boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)$的采样
\begin{equation}\hat{\boldsymbol{x}}_0\sim p(\boldsymbol{x}_0|\boldsymbol{x}_t)\quad \& \quad \boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0=\hat{\boldsymbol{x}}_0)\end{equation}
其中$p(\boldsymbol{x}_0|\boldsymbol{x}_t)$就是用$\boldsymbol{x}_t$预估$\boldsymbol{x}_0$的概率,一般用简单分布$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$来近似建模,训练目标基本上就是$-\log q(\boldsymbol{x}_0|\boldsymbol{x}_t)$或其简单变体。当$\boldsymbol{x}_0$是连续型数据时,$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$一般就取条件正态分布;当$\boldsymbol{x}_0$是离散型数据时,$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$可以选择自回归模型或者非自回归模型。

最近评论