






31
May
基于最小熵原理的NLP库:nlp zero
By 苏剑林 | 2018-05-31 | 104552位读者 | 引用陆陆续续写了几篇最小熵原理的博客,致力于无监督做NLP的一些基础工作。为了方便大家实验,把文章中涉及到的一些算法封装为一个库,供有需要的读者测试使用。
由于面向的是无监督NLP场景,而且基本都是NLP任务的基础工作,因此命名为nlp zero。
地址
Github: https://github.com/bojone/nlp-zero
Pypi: https://pypi.org/project/nlp-zero/
可以直接通过
pip install nlp-zero==0.1.6进行安装。整个库纯Python实现,没有第三方调用,支持Python2.x和3.x。
6
May
变分自编码器(五):VAE + BN = 更好的VAE
By 苏剑林 | 2020-05-06 | 205333位读者 | 引用本文我们继续之前的变分自编码器系列,分析一下如何防止NLP中的VAE模型出现“KL散度消失(KL Vanishing)”现象。本文受到参考文献是ACL 2020的论文《A Batch Normalized Inference Network Keeps the KL Vanishing Away》的启发,并自行做了进一步的完善。
值得一提的是,本文最后得到的方案还是颇为简洁的——只需往编码输出加入BN(Batch Normalization),然后加个简单的scale——但确实很有效,因此值得正在研究相关问题的读者一试。同时,相关结论也适用于一般的VAE模型(包括CV的),如果按照笔者的看法,它甚至可以作为VAE模型的“标配”。
最后,要提醒读者这算是一篇VAE的进阶论文,所以请读者对VAE有一定了解后再来阅读本文。
VAE简单回顾
这里我们简单回顾一下VAE模型,并且讨论一下VAE在NLP中所遇到的困难。关于VAE的更详细介绍,请读者参考笔者的旧作《变分自编码器(一):原来是这么一回事》、《变分自编码器(二):从贝叶斯观点出发》等。
VAE的训练流程
VAE的训练流程大概可以图示为
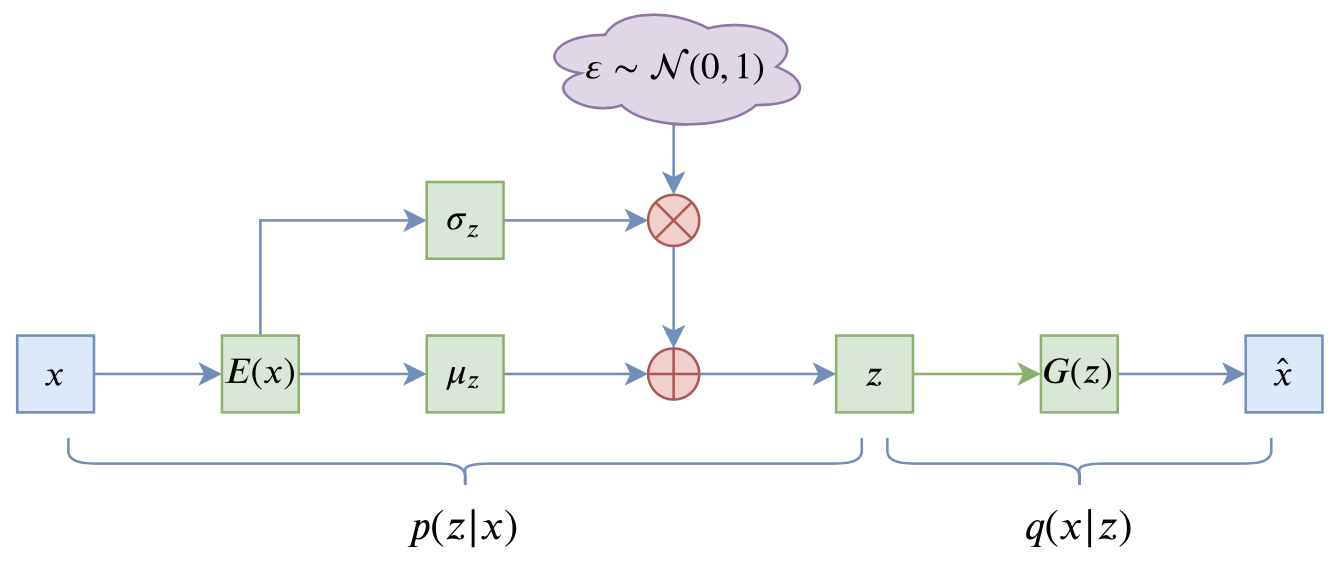
VAE训练流程图示
12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 152705位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
23
Jan
揭开迷雾,来一顿美味的Capsule盛宴
By 苏剑林 | 2018-01-23 | 444643位读者 | 引用
Geoffrey Hinton在谷歌多伦多办公室
由深度学习先驱Hinton开源的Capsule论文《Dynamic Routing Between Capsules》,无疑是去年深度学习界最热点的消息之一。得益于各种媒体的各种吹捧,Capsule被冠以了各种神秘的色彩,诸如“抛弃了梯度下降”、“推倒深度学习重来”等字眼层出不穷,但也有人觉得Capsule不外乎是一个新的炒作概念。
本文试图揭开让人迷惘的云雾,领悟Capsule背后的原理和魅力,品尝这一顿Capsule盛宴。同时,笔者补做了一个自己设计的实验,这个实验能比原论文的实验更有力说明Capsule的确产生效果了。
菜谱一览:
1、Capsule是什么?
2、Capsule为什么要这样做?
3、Capsule真的好吗?
4、我觉得Capsule怎样?
5、若干小菜。
12
Feb
再来一顿贺岁宴:从K-Means到Capsule
By 苏剑林 | 2018-02-12 | 225609位读者 | 引用在本文中,我们再次对Capsule进行一次分析。
整体上来看,Capsule算法的细节不是很复杂,对照着它的流程把Capsule用框架实现它基本是没问题的。所以,困难的问题是理解Capsule究竟做了什么,以及为什么要这样做,尤其是Dynamic Routing那几步。
为什么我要反复对Capsule进行分析?这并非单纯的“炒冷饭”,而是为了得到对Capsule原理的理解。众所周知,Capsule给人的感觉就是“有太多人为约定的内容”,没有一种“虽然我不懂,但我相信应该就是这样”的直观感受。我希望尽可能将Capsule的来龙去脉思考清楚,使我们能觉得Capsule是一个自然、流畅的模型,甚至对它举一反三。
在《揭开迷雾,来一顿美味的Capsule盛宴》中,笔者先分析了动态路由的结果,然后指出输出是输入的某种聚类,这个“从结果到原因”的过程多多少少有些望文生义的猜测成分;这次则反过来,直接确认输出是输入的聚类,然后反推动态路由应该是怎样的,其中含糊的成分大大减少。两篇文章之间有一定的互补作用。
30
May
最小熵原理(三):“飞象过河”之句模版和语言结构
By 苏剑林 | 2018-05-30 | 60122位读者 | 引用在前一文《最小熵原理(二):“当机立断”之词库构建》中,我们以最小熵原理为出发点进行了一系列的数学推导,最终得到$(2.15)$和$(2.17)$式,它告诉我们两个互信息比较大的元素我们应该将它们合并起来,这有利于降低“学习难度”。于是利用这一原理,我们通过邻字互信息来实现了词库的无监督生成。
由字到词、由词到词组,考察的是相邻的元素能不能合并成一个好“套路”。可是套路为什么非得要相邻的呢?当然不一定相邻,我们学习语言的时候,不仅仅会学习到词语、词组,还要学习到“固定搭配”,也就是说词语怎么运用才是合理的,这是语法的体现,是本文所要探究的,希望最终能达到一定的无监督句法分析的效果。
由于这次我们考虑的是跨邻词的语言关联,因此我给它起个名字为“飞象过河”,正是
“套路宝典”第二式——“飞象过河”
语言结构
对于大多数人来说,并不会真正知道什么是语法,他们脑海里就只有一些“固定搭配”、“定式”,或者更正式一点可以叫“模版”。大多数情况下,我们是根据模版来说出合理的话来。而不同的人的说话模版可能有所不同,这就是个人的说话风格,甚至是“口头禅”。
1
Sep
玩转Keras之seq2seq自动生成标题
By 苏剑林 | 2018-09-01 | 368237位读者 | 引用话说自称搞了这么久的NLP,我都还没有真正跑过NLP与深度学习结合的经典之作——seq2seq。这两天兴致来了,决定学习并实践一番seq2seq,当然最后少不了Keras实现了。
seq2seq可以做的事情非常多,我这挑选的是比较简单的根据文章内容生成标题(中文),也可以理解为自动摘要的一种。选择这个任务主要是因为“文章-标题”这样的语料对比较好找,能快速实验一下。
seq2seq简介
所谓seq2seq,就是指一般的序列到序列的转换任务,比如机器翻译、自动文摘等等,这种任务的特点是输入序列和输出序列是不对齐的,如果对齐的话,那么我们称之为序列标注,这就比seq2seq简单很多了。所以尽管序列标注任务也可以理解为序列到序列的转换,但我们在谈到seq2seq时,一般不包含序列标注。
要自己实现seq2seq,关键是搞懂seq2seq的原理和架构,一旦弄清楚了,其实不管哪个框架实现起来都不复杂。早期有一个第三方实现的Keras的seq2seq库,现在作者也已经放弃更新了,也许就是觉得这么简单的事情没必要再建一个库了吧。可以参考的资料还有去年Keras官方博客中写的《A ten-minute introduction to sequence-to-sequence learning in Keras》。
28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 195701位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
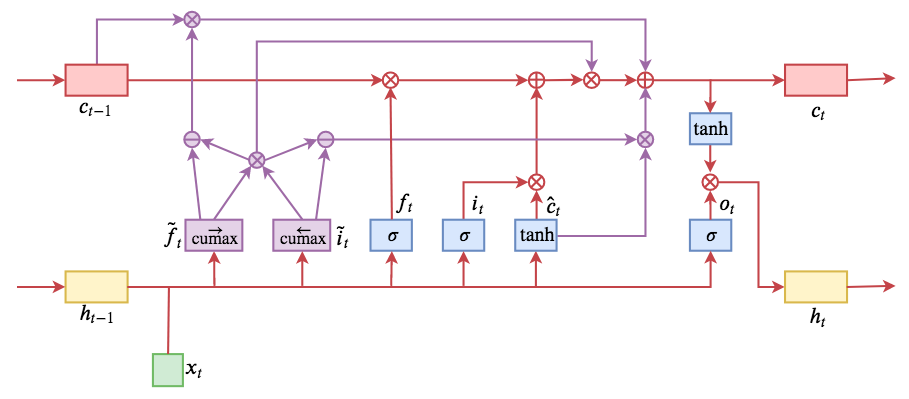
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~

最近评论