






20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 62449位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 28933位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。
9
Oct
“十字架”组合计数问题浅试
By 苏剑林 | 2022-10-09 | 18076位读者 | 引用
4
Jan
智能家居之热水器零冷水技术原理浅析
By 苏剑林 | 2023-01-04 | 38278位读者 | 引用如果家庭使用单一的热水器集中供热水,那么当我们想要用热水时,往往需要先放一段时间的冷水,而如果放冷水时间比较长的话,就会比较影响体验。所谓零冷水,实际上就是想办法提前把热水管中的冷水排放掉,以达到(几乎)瞬间出热水的效果。事实上,零冷水并不是什么高大上的技术,但可能由于观念没跟上、理解上有误等原因,零冷水技术还没有在家庭中得到普及,不过随着大家对生活品质的要求越来越高,零冷水确实在慢慢流行起来了。
本文来简单分析一下零冷水技术的实现原理,包括各种方案的优缺点和自省DIY的参考思路。
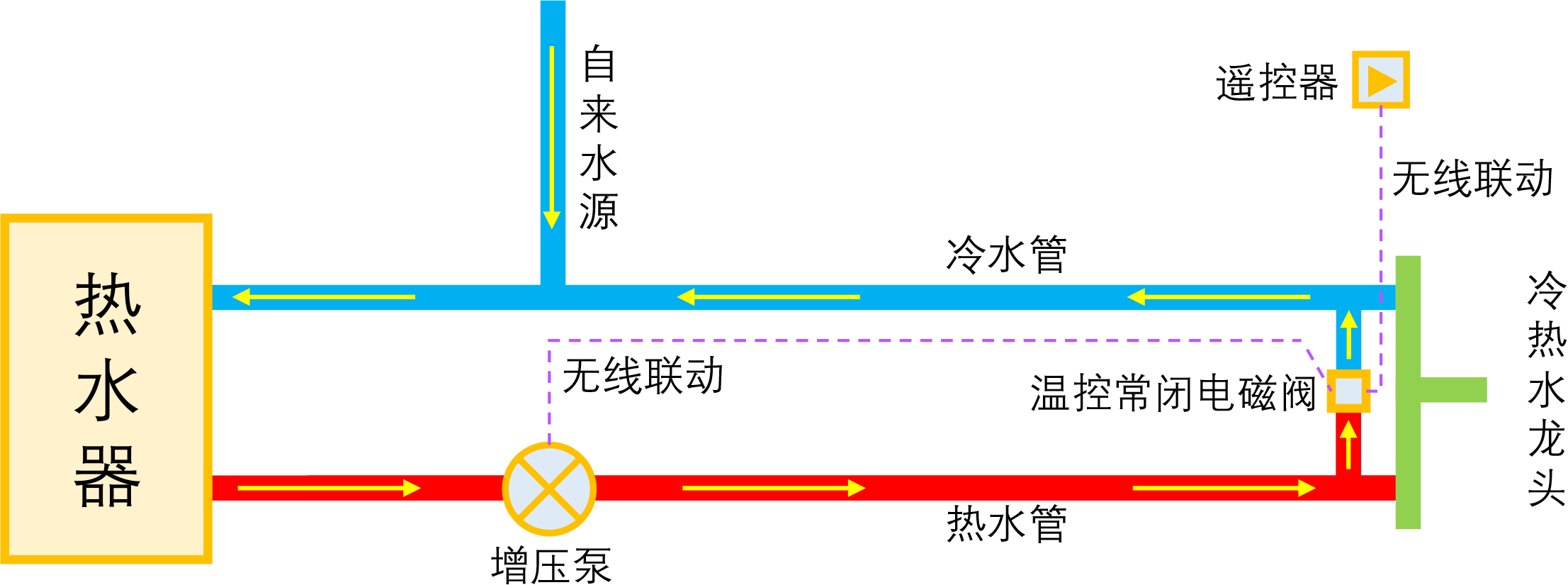
理想的零冷水方案
写在前面
在文章开始,需要纠正很多人的一个错误观念:零冷水不是为了省钱,而是为了提升生活品质。如果你是省钱最大的心态,那么接下来的内容就可以不用看了,零冷水技术对你毫无价值。
8
Jun
Naive Bayes is all you need ?
By 苏剑林 | 2023-06-08 | 39455位读者 | 引用很抱歉,起了这么个具有标题党特征的题目。在写完《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》之后,笔者就觉得朴素贝叶斯(Naive Bayes)跟Attention机制有很多相同的特征,后来再推导了一下发现,Attention机制其实可以看成是一种广义的、参数化的朴素贝叶斯。既然如此,“Attention is All You Need”不也就意味着“Naive Bayes is all you need”了?这就是本文标题的缘由。
接下来笔者将介绍自己的思考过程,分析如何从朴素贝叶斯角度来理解Attention机制。
朴素贝叶斯
本文主要考虑语言模型,它要建模的是$p(x_t|x_1,\cdots,x_{t-1})$。根据贝叶斯公式,我们有
\begin{equation}p(x_t|x_1,\cdots,x_{t-1}) = \frac{p(x_1,\cdots,x_{t-1}|x_t)p(x_t)}{p(x_1,\cdots,x_{t-1})}\propto p(x_1,\cdots,x_{t-1}|x_t)p(x_t)\end{equation}
31
May
关于NBCE方法的一些补充说明和分析
By 苏剑林 | 2023-05-31 | 23061位读者 | 引用上周在《NBCE:使用朴素贝叶斯扩展LLM的Context处理长度》中,我们介绍了一种基于朴素贝叶斯来扩展LLM的Context长度的方案NBCE(Naive Bayes-based Context Extension)。由于它有着即插即用、模型无关、不用微调等优点,也获得了一些读者的认可,总的来说目前大家反馈的测试效果还算可以。
当然,部分读者在使用的时候也提出了一些问题。本文就结合读者的疑问和笔者的后续思考,对NBCE方法做一些补充说明和分析。
方法回顾
假设$T$为要生成的token序列,$S_1,S_2,\cdots,S_n$是给定的若干个Context,我们需要根据$S_1,S_2,\cdots,S_n$生成$T$,那么就需要估计$p(T|S_1, S_2,\cdots,S_n)$。根据朴素贝叶斯思想,我们得到
\begin{equation}\log p(T|S_1, S_2,\cdots,S_n) = \color{red}{(\beta + 1)\overline{\log p(T|S)}} - \color{green}{\beta\log p(T)} + \color{skyblue}{\text{常数}}\label{eq:nbce-2}\end{equation}
17
Mar
为什么现在的LLM都是Decoder-only的架构?
By 苏剑林 | 2023-03-17 | 92258位读者 | 引用LLM是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
知乎上也有同款问题《为什么现在的LLM都是Decoder only的架构?》,上面的回答大多数聚焦于Decoder-only在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。文章多数推论以自己的实验结果为引,某些地方可能会跟某些文献的结果冲突,请读者自行取舍。
31
Jul
Transformer升级之路:11、将β进制位置进行到底
By 苏剑林 | 2023-07-31 | 44079位读者 | 引用在文章《Transformer升级之路:10、RoPE是一种β进制编码》中,我们给出了RoPE的$\beta$进制诠释,并基于进制转化的思路推导了能够在不微调的情况下就可以扩展Context长度的NTK-aware Scaled RoPE。不得不说,通过类比$\beta$进制的方式来理解位置编码,确实是一个非常美妙且富有启发性的视角,以至于笔者每次深入思考和回味之时,似乎总能从中得到新的领悟和收获。
本文将重新回顾RoPE的$\beta$进制诠释,并尝试将已有的NTK-aware Scaled RoPE一般化,以期望找到一种更优的策略来不微调地扩展LLM的Context长度。
进制类比
我们知道,RoPE的参数化沿用了Sinusoidal位置编码的形式。而不知道是巧合还是故意为之,整数$n$的Sinusoidal位置编码,与它的$\beta$进制编码,有很多相通之处。

最近评论