






11
Jun
SimBERTv2来了!融合检索和生成的RoFormer-Sim模型
By 苏剑林 | 2021-06-11 | 111136位读者 | 引用去年我们放出了SimBERT模型,它算是我们开源的比较成功的模型之一,获得了不少读者的认可。简单来说,SimBERT是一个融生成和检索于一体的模型,可以用来作为句向量的一个比较高的baseline,也可以用来实现相似问句的自动生成,可以作为辅助数据扩增工具使用,这一功能是开创性的。
近段时间,我们以RoFormer为基础模型,对SimBERT相关技术进一步整合和优化,最终发布了升级版的RoFormer-Sim模型。
简介
RoFormer-Sim是SimBERT的升级版,我们也可以通俗地称之为“SimBERTv2”,而SimBERT则默认是指旧版。从外部看,除了基础架构换成了RoFormer外,RoFormer-Sim跟SimBERT没什么明显差别,事实上它们主要的区别在于训练的细节上,我们可以用两个公式进行对比:
\begin{array}{c}
\text{SimBERT} = \text{BERT} + \text{UniLM} + \text{对比学习} \\[5pt]
\text{RoFormer-Sim} = \text{RoFormer} + \text{UniLM} + \text{对比学习} + \text{BART} + \text{蒸馏}\\
\end{array}
23
Jul
完成了一个typecho的签名图片
By 苏剑林 | 2010-07-23 | 23554位读者 | 引用
26
Aug
fashion-mnist的gan玩具
By 苏剑林 | 2017-08-26 | 59332位读者 | 引用
fashion_mnist_demo
mnist的手写数字识别数据集一直是各种机器学习算法的试金石之一,最近有个新的数据集要向它叫板,称为fashion-mnist,内容是衣服鞋帽等分类。为了便于用户往fashion-mnist迁移,作者把数据集做成了几乎跟mnist手写数字识别数据集一模一样——同样数量、尺寸的图片,同样是10分类,甚至连数据打包和命名都跟mnist一样。看来fashion mnist为了取代mnist,也是拼了,下足了功夫,一切都做得一模一样,最大限度降低了使用成本~这叫板的心很坚定呀。
叫板的原因很简单——很多人吐槽,如果一个算法在mnist没用,那就一定没用了,但如果一个算法在mnist上有效,那它也不见得在真实问题中有效~也就是说,这个数据集太简单,没啥代表性。
fashion-mnist的github:https://github.com/zalandoresearch/fashion-mnist/
24
Aug
Transformer升级之路:14、当HWFA遇见ReRoPE
By 苏剑林 | 2023-08-24 | 32168位读者 | 引用在上一篇文章《Transformer升级之路:13、逆用Leaky ReRoPE》中,笔者尝试通过在训练阶段逆用Leaky ReRoPE的思路,使得推理阶段的位置编码变为正常的RoPE,从而在达到长度外推的同时解决ReRoPE推理变慢的缺点。遗憾的是,从实验结果来看,“Leaky ReRoPE → RoPE”的效果并不如“RoPE → ReRoPE/Leaky ReRoPE”,因此这个问题尚未完全解决。
此时,笔者想到此前在《Transformer升级之路:9、一种全局长度外推的新思路》提出的HWFA本身就具有一定的长度外推能力,如果跟ReRoPE“强强联合”,是否会有更好的效果?更关键是,HWFA的加入可以大幅度降低推理成本,从而弥补ReRoPE的不足!
温故
首先,“例行公事”地回顾一下HWFA。HWFA(Hybird Window-Full Attention)并非一个具体的模型,而是一种Attention的组合方式,能够在基本保持效果不变的前提下,增强Attention模型的长度外推能力,同时还能降低训练和推理成本。
15
Aug
让MathJax更好地兼容谷歌翻译和延时加载
By 苏剑林 | 2024-08-15 | 17701位读者 | 引用很早之前,就有读者提出希望把Cool Papers上面的数学公式渲染一下,因为很多偏数学的论文,它们的摘要甚至标题上都带有LaTeX代码写的数学公式,如果不把这些公式渲染出来,那么看上去就像是一堆乱码,确实会比较影响阅读体验。然而,之前的测试显示,负责渲染公式的MathJax跟谷歌翻译和延时加载都不大兼容,所以尽管需求存在已久,但笔者一直没有把它加上去。
不过好消息是,经过反复查阅和调试,这两天笔者总算把兼容性问题解决了,所以现在大家看到的Cool Papers已经能够渲染数学公式了。这篇文章总结一下解决方案,供大家参考。

摘要带有公式的论文
1
Jul
又是Dropout两次!这次它做到了有监督任务的SOTA
By 苏剑林 | 2021-07-01 | 214250位读者 | 引用关注NLP新进展的读者,想必对四月份发布的SimCSE印象颇深,它通过简单的“Dropout两次”来构造正样本进行对比学习,达到了无监督语义相似度任务的全面SOTA。无独有偶,最近的论文《R-Drop: Regularized Dropout for Neural Networks》提出了R-Drop,它将“Dropout两次”的思想用到了有监督任务中,每个实验结果几乎都取得了明显的提升。此外,笔者在自己的实验还发现,它在半监督任务上也能有不俗的表现。
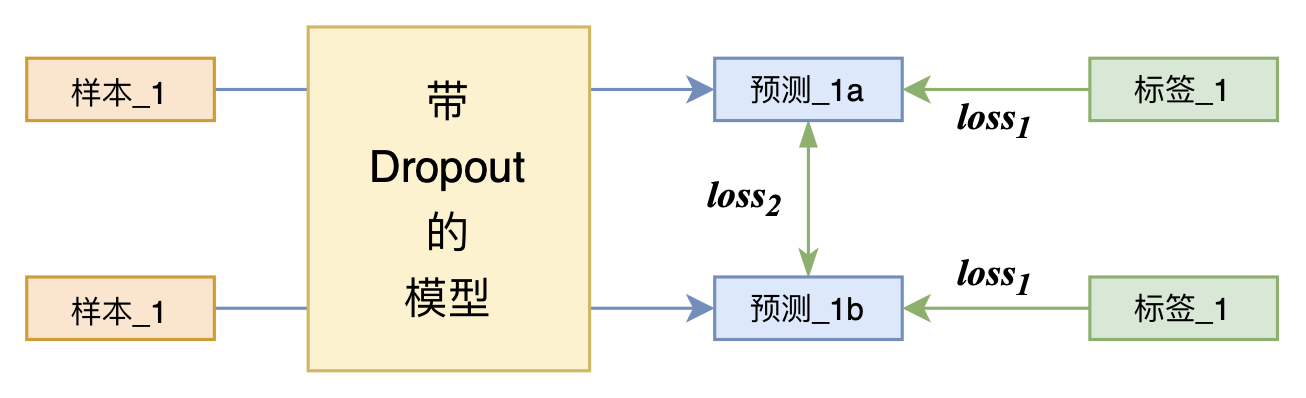
R-Drop示意图
小小的“Dropout两次”,居然跑出了“五项全能”的感觉,不得不令人惊讶。本文来介绍一下R-Drop,并分享一下笔者对它背后原理的思考。
18
Sep
提速不掉点:基于词颗粒度的中文WoBERT
By 苏剑林 | 2020-09-18 | 112490位读者 | 引用当前,大部分中文预训练模型都是以字为基本单位的,也就是说中文语句会被拆分为一个个字。中文也有一些多颗粒度的语言模型,比如创新工场的ZEN和字节跳动的AMBERT,但这类模型的基本单位还是字,只不过想办法融合了词信息。目前以词为单位的中文预训练模型很少,据笔者所了解到就只有腾讯UER开源了一个以词为颗粒度的BERT模型,但实测效果并不好。
那么,纯粹以词为单位的中文预训练模型效果究竟如何呢?有没有它的存在价值呢?最近,我们预训练并开源了以词为单位的中文BERT模型,称之为WoBERT(Word-based BERT,我的BERT!),实验显示基于词的WoBERT在不少任务上有它独特的优势,比如速度明显的提升,同时效果基本不降甚至也有提升。在此对我们的工作做一个总结。
29
Nov
Dropout视角下的MLM和MAE:一些新的启发
By 苏剑林 | 2021-11-29 | 75263位读者 | 引用大家都知道,BERT的MLM(Masked Language Model)任务在预训练和微调时的不一致,也就是预训练出现了[MASK]而下游任务微调时没有[MASK],是经常被吐槽的问题,很多工作都认为这是影响BERT微调性能的重要原因,并针对性地提出了很多改进,如XL-NET、ELECTRA、MacBERT等。本文我们将从Dropout的角度来分析MLM的这种不一致性,并且提出一种简单的操作来修正这种不一致性。
同样的分析还可以用于何凯明最近提出的比较热门的MAE(Masked Autoencoder)模型,结果是MAE相比MLM确实具有更好的一致性,由此我们可以引出一种可以能加快训练速度的正则化手段。
Dropout
首先,我们重温一下Dropout。从数学上来看,Dropout是通过伯努利分布来为模型引入随机噪声的操作,所以我们也简单复习一下伯努利分布。

最近评论