






27
Oct
什么时候多进程的加速比可以大于1?
By 苏剑林 | 2019-10-27 | 59697位读者 | 引用多进程或者多线程等并行加速目前已经不是什么难事了,相信很多读者都体验过。一般来说,我们会有这样的结论:多进程的加速比很难达到1。换句话说,当你用10进程去并行跑一个任务时,一般只能获得不到10倍的加速,而且进程越多,这个加速比往往就越低。
要注意,我们刚才说“很难达到1”,说明我们的潜意识里就觉得加速比最多也就是1。理论上确实是的,难不成用10进程还能获得20倍的加速?这不是天上掉馅饼吗?不过我前几天确实碰到了一个加速比远大于1的例子,所以在这里跟大家分享一下。
词频统计
我的原始任务是统计词频:我有很多文章,然后我们要对这些文章进行分词,最后汇总出一个词频表出来。一般的写法是这样的:
tokens = {}
for text in read_texts():
for token in tokenize(text):
tokens[token] = tokens.get(token, 0) + 1这种写法在我统计THUCNews全部文章的词频时,大概花了20分钟。
9
Mar
训练1000层的Transformer究竟有什么困难?
By 苏剑林 | 2022-03-09 | 77972位读者 | 引用众所周知,现在的Transformer越做越大,但这个“大”通常是“宽”而不是“深”,像GPT-3虽然参数有上千亿,但也只是一个96层的Transformer模型,与我们能想象的深度相差甚远。是什么限制了Transformer往“深”发展呢?可能有的读者认为是算力,但“宽而浅”的模型所需的算力不会比“窄而深”的模型少多少,所以算力并非主要限制,归根结底还是Transformer固有的训练困难。一般的观点是,深模型的训练困难源于梯度消失或者梯度爆炸,然而实践显示,哪怕通过各种手段改良了梯度,深模型依然不容易训练。
近来的一些工作(如Admin)指出,深模型训练的根本困难在于“增量爆炸”,即模型越深对输出的扰动就越大。上周的论文《DeepNet: Scaling Transformers to 1,000 Layers》则沿着这个思路进行尺度分析,根据分析结果调整了模型的归一化和初始化方案,最终成功训练出了1000层的Transformer模型。整个分析过程颇有参考价值,我们不妨来学习一下。
增量爆炸
原论文的完整分析比较长,而且有些假设或者描述细酌之下是不够合理的。所以在本文的分享中,笔者会尽量修正这些问题,试图以一个更合理的方式来得到类似结果。
1
Sep
Decoder-only的LLM为什么需要位置编码?
By 苏剑林 | 2024-09-01 | 31424位读者 | 引用众所周知,目前主流的LLM,都是基于Causal Attention的Decoder-only模型(对此我们在《为什么现在的LLM都是Decoder-only的架构?》也有过相关讨论),而对于Causal Attention,已经有不少工作表明它不需要额外的位置编码(简称NoPE)就可以取得非平凡的结果。然而,事实是主流的Decoder-only LLM都还是加上了额外的位置编码,比如RoPE、ALIBI等。
那么问题就来了:明明说了不加位置编码也可以,为什么主流的LLM反而都加上了呢?不是说“多一事不如少一事”吗?这篇文章我们从三个角度给出笔者的看法:
1、位置编码对于Attention的作用是什么?
2、NoPE的Causal Attention是怎么实现位置编码的?
3、NoPE实现的位置编码有什么不足?
18
Aug
【中文分词系列】 2. 基于切分的新词发现
By 苏剑林 | 2016-08-18 | 124780位读者 | 引用上一篇文章讲的是基于词典和AC自动机的快速分词。基于词典的分词有一个明显的优点,就是便于维护,容易适应领域。如果迁移到新的领域,那么只需要添加对应的领域新词,就可以实现较好地分词。当然,好的、适应领域的词典是否容易获得,这还得具体情况具体分析。本文要讨论的就是新词发现这一部分的内容。
这部分内容在去年的文章《新词发现的信息熵方法与实现》已经讨论过了,算法是来源于matrix67的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》。在那篇文章中,主要利用了三个指标——频数、凝固度(取对数之后就是我们所说的互信息熵)、自由度(边界熵)——来判断一个片段是否成词。如果真的动手去实现过这个算法的话,那么会发现有一系列的难度。首先,为了得到$n$字词,就需要找出$1\sim n$字的切片,然后分别做计算,这对于$n$比较大时,是件痛苦的时间;其次,最最痛苦的事情是边界熵的计算,边界熵要对每一个片段就行分组统计,然后再计算,这个工作量的很大的。本文提供了一种方案,可以使得新词发现的计算量大大降低。
24
Jun
VQ-VAE的简明介绍:量子化自编码器
By 苏剑林 | 2019-06-24 | 324365位读者 | 引用印象中很早之前就看到过VQ-VAE,当时对它并没有什么兴趣,而最近有两件事情重新引起了我对它的兴趣。一是VQ-VAE-2实现了能够匹配BigGAN的生成效果(来自机器之心的报道);二是我最近看一篇NLP论文《Unsupervised Paraphrasing without Translation》时发现里边也用到了VQ-VAE。这两件事情表明VQ-VAE应该是一个颇为通用和有意思的模型,所以我决定好好读读它。

个人复现的VQ-VAE在CelebA上的重构效果。可以留意到细节保留得还不错,但稍微放大后能留意到仍有一些模糊感。
27
Sep
必须要GPT3吗?不,BERT的MLM模型也能小样本学习
By 苏剑林 | 2020-09-27 | 153147位读者 | 引用大家都知道现在GPT3风头正盛,然而,到处都是GPT3、GPT3地推,读者是否记得GPT3论文的名字呢?事实上,GPT3的论文叫做《Language Models are Few-Shot Learners》,标题里边已经没有G、P、T几个单词了,只不过它跟开始的GPT是一脉相承的,因此还是以GPT称呼它。顾名思义,GPT3主打的是Few-Shot Learning,也就是小样本学习。此外,GPT3的另一个特点就是大,最大的版本多达1750亿参数,是BERT Base的一千多倍。
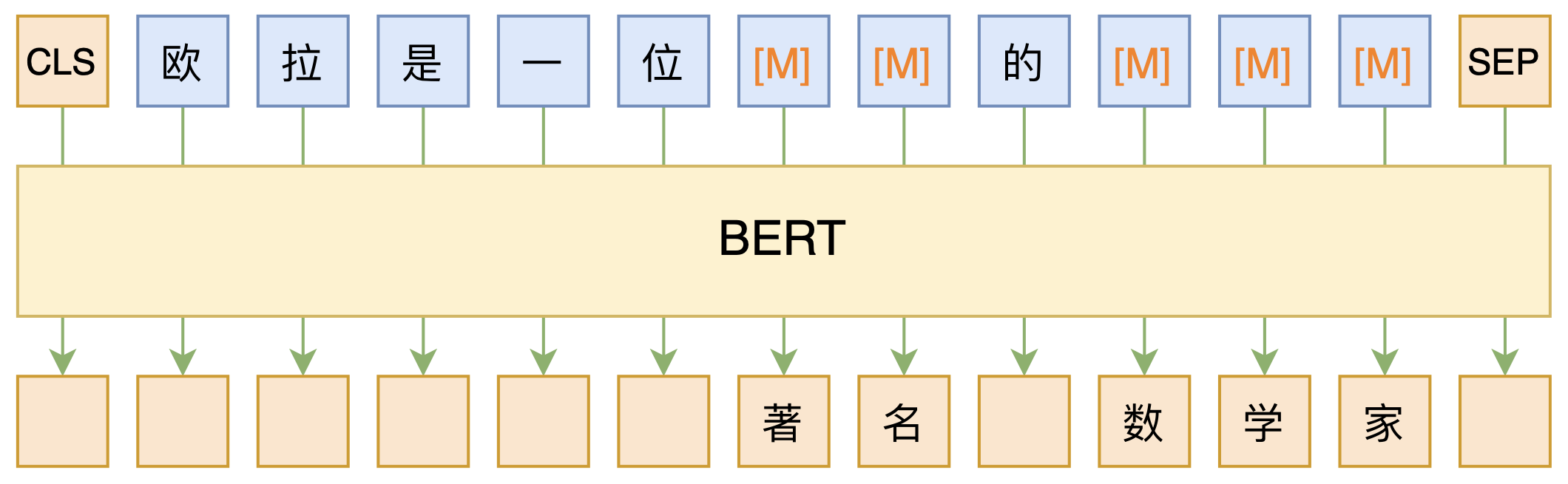
BERT的MLM模型简单示意图
正因如此,前些天Arxiv上的一篇论文《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》便引起了笔者的注意,意译过来就是“谁说一定要大的?小模型也可以做小样本学习”。显然,这标题对标的就是GPT3,于是笔者饶有兴趣地点进去看看是谁这么有勇气挑战GPT3,又是怎样的小模型能挑战GPT3?经过阅读,原来作者提出通过适当的构造,用BERT的MLM模型也可以做小样本学习,看完之后颇有一种“原来还可以这样做”的恍然大悟感~在此与大家分享一下。
27
Jun
重温SSM(四):有理生成函数的新视角
By 苏剑林 | 2024-06-27 | 17530位读者 | 引用在前三篇文章中,我们较为详细地讨论了HiPPO和S4的大部分数学细节。那么,对于接下来的第四篇文章,大家预期我们会讨论什么工作呢?S5、Mamba乃至Mamba2?都不是。本系列文章主要关心SSM的数学基础,旨在了解SSM的同时也补充自己的数学能力。而在上一篇文章我们简单提过S5和Mamba,S5是S4的简化版,相比S4基本上没有引入新的数学技巧,而Mamba系列虽然表现优异,但它已经将$A$简化为对角矩阵,所用到的数学技巧就更少了,它更多的是体现了工程方面的能力。
这篇文章我们来学习一篇暂时还声名不显的新工作《State-Free Inference of State-Space Models: The Transfer Function Approach》(简称RFT),它提出了一个新方案,将SSM的训练、推理乃至参数化,都彻底转到了生成函数空间中,为SSM的理解和应用开辟了新的视角
基础回顾
首先我们简单回顾一下上一篇文章关于S4的探讨结果。S4基于如下线性RNN
\begin{equation}\begin{aligned}
x_{k+1} =&\, \bar{A} x_k + \bar{B} u_k \\
y_{k+1} =&\, \bar{C}^* x_{k+1} \\
\end{aligned}\label{eq:linear}\end{equation}
17
Mar
为什么现在的LLM都是Decoder-only的架构?
By 苏剑林 | 2023-03-17 | 108188位读者 | 引用LLM是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
知乎上也有同款问题《为什么现在的LLM都是Decoder only的架构?》,上面的回答大多数聚焦于Decoder-only在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。文章多数推论以自己的实验结果为引,某些地方可能会跟某些文献的结果冲突,请读者自行取舍。

最近评论