






15
Feb
能量视角下的GAN模型(二):GAN=“分析”+“采样”
By 苏剑林 | 2019-02-15 | 133982位读者 | 引用在这个系列中,我们尝试从能量的视角理解GAN。我们会发现这个视角如此美妙和直观,甚至让人拍案叫绝。
上一篇文章里,我们给出了一个直白而用力的能量图景,这个图景可以让我们轻松理解GAN的很多内容,换句话说,通俗的解释已经能让我们完成大部分的理解了,并且把最终的结论都已经写了出来。在这篇文章中,我们继续从能量的视角理解GAN,这一次,我们争取把前面简单直白的描述,用相对严密的数学语言推导一遍。
跟第一篇文章一样,对于笔者来说,这个推导过程依然直接受启发于Bengio团队的新作《Maximum Entropy Generators for Energy-Based Models》。
原作者的开源实现:https://github.com/ritheshkumar95/energy_based_generative_models
本文的大致内容如下:
1、推导了能量分布下的正负相对抗的更新公式;
2、比较了理论分析与实验采样的区别,而将两者结合便得到了GAN框架;
3、导出了生成器的补充loss,理论上可以防止mode collapse;
4、简单提及了基于能量函数的MCMC采样。
6
Oct
从马尔科夫过程到主方程(推导过程)
By 苏剑林 | 2017-10-06 | 75958位读者 | 引用主方程(master equation)是对随机过程进行建模的重要方法,它代表着马尔科夫过程的微分形式,我们的专业主要工具之一就是主方程,说宏大一点,量子力学和统计力学等也不外乎是主方程的一个特例。
然而,笔者阅读了几个著作,比如《统计物理现代教程》,还有我导师的《生物系统的随机动力学》,我发现这些著作对于主方程的推导都很模糊,他们在着力解释结果的意义,但并不说明结果的思想来源,因此其过程难以让人信服。而知乎上有人提问《如何理解马尔科夫过程的主方程的推导过程?》但没有得到很好的答案,也表明了这个事实。
马尔可夫过程
主方程是用来描述马尔科夫过程的,而马尔科夫过程可以理解为运动的无记忆性,说通俗点,就是下一刻的概率分布,只跟当前时刻有关,跟历史状态无关。用概率公式写出来就是(这里只考虑连续型概率,因此这里的$p$是概率密度):
$$\begin{equation}\label{eq:maerkefu}p(x,\tau)=\int p(x,\tau|y,t) p(y,t) dy\end{equation}$$
这里的积分区域是全空间。这里的$p(x,\tau|y,t)$称为跃迁概率,即已经确定了$t$时刻来到了$y$位置后、在$\tau$时刻达到$x$的概率密度,这个式子的物理意义是很明显的,就不多做解释了。
26
Dec
《自然极值》系列——7.悬链线问题
By 苏剑林 | 2010-12-26 | 74639位读者 | 引用
约翰与他同时代的110位学者有通信联系,进行学术讨论的信件约有2500封,其中许多已成为珍贵的科学史文献,例如同他的哥哥雅各布以及莱布尼茨、惠更斯等人关于悬链线、最速降线(即旋轮线)和等周问题的通信讨论,虽然相互争论不断,特别是约翰和雅各布互相指责过于尖刻,使兄弟之间时常造成不快,但争论无疑会促进科学的发展,最速降线问题就导致了变分法的诞生。
有意思的是,1690年约翰·伯努利的哥哥雅可比·伯努利曾提出过悬链线问题向数学界征求答案。即:
固定项链的两端,在重力场中让它自然垂下,求项链的曲线方程.
吊桥上方的悬垂钢索,挂着水珠的蜘蛛网,电杆间的电线都是悬链线。伽利略最早注意到悬链线,猜测悬链线是抛物线。1691年莱布尼兹、惠更斯以及约翰·伯努利各自得到正确答案,所用方法是诞生不久的微积分。
15
May
地球引力场的悬链线方程
By 苏剑林 | 2011-05-15 | 63309位读者 | 引用之前曾在《自然极值》系列文章中提到过均匀重力场下的悬链线形状问题,并且在那文章中向读者提出:在一个质点(地球)引力场中的悬链线形状会是怎么样的。说实话,提出这个问题的时候,我还不懂怎么解答这个问题,不过现在会了,回头一看,已经几个月了,时间过得真快...
与之前的思路一样,我们依旧采用的是“平衡态公理”,即总势能最小。从天体力学中我们知道,任意两个质点间的势能为$-\frac{Gm_1 m_2}{r}$。对于本题的悬链线问题,我们可以把地球放到坐标原点位置,而悬链的两个固定点分别为$(x_1,y_1)$和$(x_2,y_2)$,链的总长度为l。即
$$\int_{x_1}^{x_2} \sqrt{dx^2+dy^2}=l$$
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 88284位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
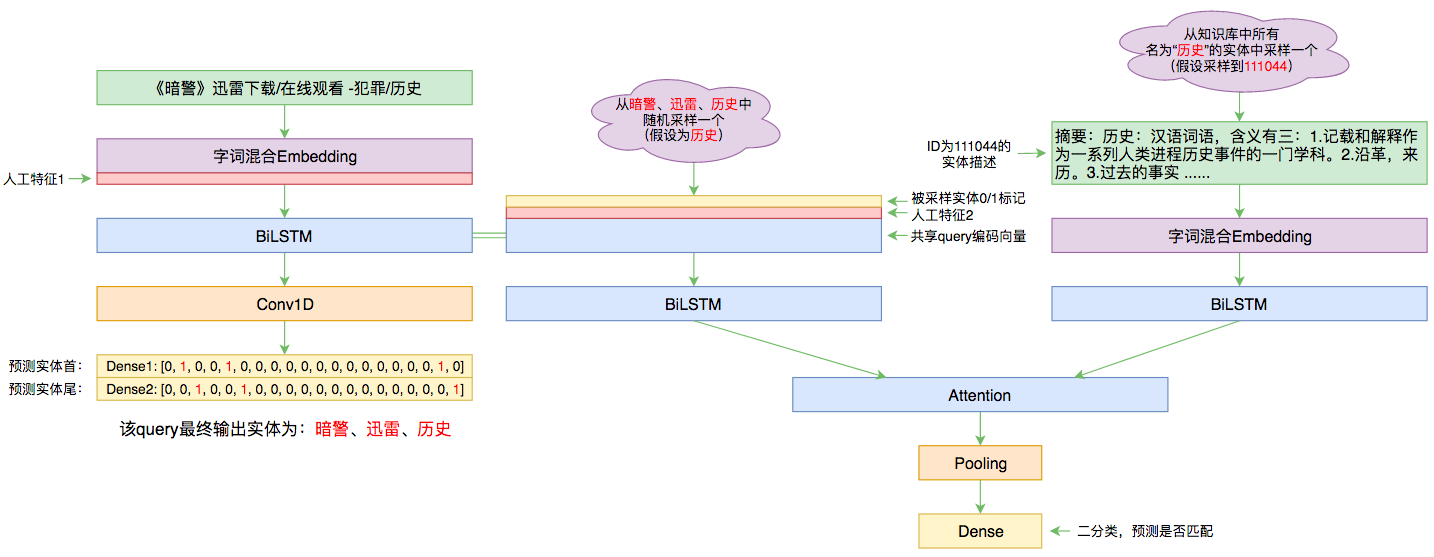
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 334437位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
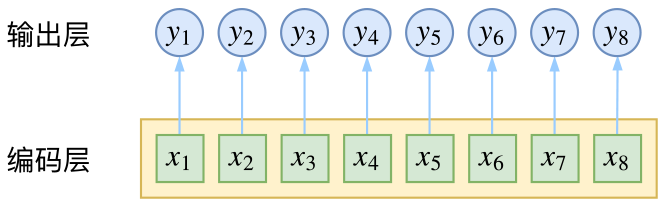
逐帧softmax并没有直接考虑输出的上下文关联
19
Aug
【中文分词系列】 3. 字标注法与HMM模型
By 苏剑林 | 2016-08-19 | 86546位读者 | 引用在这篇文章中,我们暂停查词典方法的介绍,转而介绍字标注的方法。前面已经提到过,字标注是通过给句子中每个字打上标签的思路来进行分词,比如之前提到过的,通过4标签来进行标注(single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾。均只取第一个字母。),这样,“为人民服务”就可以标注为“sbebe”了。4标注不是唯一的标注方式,类似地还有6标注,理论上来说,标注越多会越精细,理论上来说效果也越好,但标注太多也可能存在样本不足的问题,一般常用的就是4标注和6标注。
值得一提的是,这种通过给每个字打标签、进而将问题转化为序列到序列的学习,不仅仅是一种分词方法,还是一种解决大量自然语言问题的思路,比如命名实体识别等任务,同样可以用标注的方法来做。回到分词来,通过字标注法来进行分词的模型有隐马尔科夫模型(HMM)、最大熵模型(ME)、条件随机场模型(CRF),它们在精度上都是递增的,据说目前公开评测中分词效果最好的是4标注的CRF。然而,在本文中,我们要讲解的是最不精确的HMM。因为在我看来,它并非一个特定的模型,而是解决一大类问题的通用思想,一种简化问题的学问。
这一切,还得从概率模型谈起。
6
Jan
《Attention is All You Need》浅读(简介+代码)
By 苏剑林 | 2018-01-06 | 892795位读者 | 引用2017年中,有两篇类似同时也是笔者非常欣赏的论文,分别是FaceBook的《Convolutional Sequence to Sequence Learning》和Google的《Attention is All You Need》,它们都算是Seq2Seq上的创新,本质上来说,都是抛弃了RNN结构来做Seq2Seq任务。
这篇博文中,笔者对《Attention is All You Need》做一点简单的分析。当然,这两篇论文本身就比较火,因此网上已经有很多解读了(不过很多解读都是直接翻译论文的,鲜有自己的理解),因此这里尽可能多自己的文字,尽量不重复网上各位大佬已经说过的内容。
序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_t)$,其中$\boldsymbol{x}_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$\boldsymbol{X}\in \mathbb{R}^{n\times d}$。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
\begin{equation}\boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t)\end{equation}
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。

最近评论