






23
Dec
鬼斧神工:求n维球的体积
By 苏剑林 | 2014-12-23 | 103851位读者 | 引用今天早上同学问了我有关伽马函数和$n$维空间的球体积之间的关系,我记得我以前想要研究,但是并没有落实。既然她提问了,那么就完成这未完成的计划吧。
标准思路
简单来说,$n$维球体积就是如下$n$重积分
$$V_n(r)=\int_{x_1^2+x_2^2+\dots+x_n^2\leq r^2}dx_1 dx_2\dots dx_n$$
用更加几何的思路,我们通过一组平行面($n-1$维的平行面)分割,使得$n$维球分解为一系列近似小柱体,因此,可以得到递推公式
$$V_n (r)=\int_{-r}^r V_{n-1} \left(\sqrt{r^2-t^2}\right)dt$$
设$t=r\sin\theta_1$,就有
$$V_n (r)=r\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} V_{n-1} \left(r\cos\theta_1\right)\cos\theta_1 d\theta_1$$
27
Mar
海伦公式的一个别致的物理推导
By 苏剑林 | 2015-03-27 | 48364位读者 | 引用海伦公式是已知三角形三边的长度$a,b,c$来求面积$S$的公式,是一个相当漂亮的公式,它不算复杂,同时它关于$a,b,c$是对称的,充分体现了三边的同等地位。可是,这样具有对称美的公式推导,往往要经过一个不对称的过程,比如维基百科上的证明,这未免有点美中不足。本文的目的,就是想为此补充一个对称的推导。本文题目为“物理推导”,关键在于“推导”而不是“证明”,同时这里的“物理”并非是通过物理类比而来,而是推导的思想和方法很具有“物理味道”。
$$\sqrt{p(p-a)(p-b)(p-c)}$$
在推导开始之前,笔者给出一个评论:海伦公式似乎是由三边长求三角形面积的所有可能的公式之中最简单的一个。
17
Mar
你所没有思考过的平行线问题
By 苏剑林 | 2015-03-17 | 33827位读者 | 引用
欧几里得
本文的主题是平行线,了解数学的朋友可能会想我会写有关非欧几何的内容。但这次不是,本文的内容纯粹是我们从小就开始学习的欧氏几何,基于“欧几里得第五公设”(又称平行公设)。但即便是从小就学习的欧氏几何中的平行线,也许里边的很多问题我们都没有思考清楚。因为平行是几何中非常基本的情形,因此,在讨论这种基本命题的时候,相当容易会出现循环论证、甚至本末倒置的情况。
我们从初中开始就被灌输“同位角相等,两直线平行”、“内错角相等,两直线平行”之类的平行线判断法则,当然,还少不了的是“过直线外一点只能作一条直线与已知直线平行”。但是,这些内容之中,有多少是基本的公理,有多少是可以证明的,该如何证明,我想很多人都理解不清楚,我自己也没有一个很好的答案。那些在初中教授平行线的老师们,估计也没多少个能够把它说清楚的。后来我发现,我居然不会证明“同位角相等,两直线平行”,“欧几里得第五公设”好像并没有告诉我们这个判定法则呀。于是,我翻看了一下初中的数学教科书,发现原来当初“同位角相等,两直线平行”这一判定法则是不加证明地让我们接受的,无怪乎我怎么也想不到关于这一法则的简单的证明...
于是,我想写这篇文章,为大家理解平行线的整个逻辑提供一点参考。
20
Feb
熵的形象来源与熵的妙用
By 苏剑林 | 2016-02-20 | 29646位读者 | 引用在拙作《“熵”不起:从熵、最大熵原理到最大熵模型(一)》中,笔者从比较“专业”的角度引出了熵,并对熵做了诠释。当然,熵作为不确定性的度量,应该具有更通俗、更形象的来源,本文就是试图补充这一部分,并由此给出一些妙用。
熵的形象来源
我们考虑由0-9这十个数字组成的自然数,如果要求小于10000的话,那么很自然有10000个,如果我们说“某个小于10000的自然数”,那么0~9999都有可能出现,那么10000便是这件事的不确定性的一个度量。类似地,考虑$n$个不同元素(可重复使用)组成的长度为$m$的序列,那么这个序列有$n^m$种情况,这时$n^m$也是这件事情的不确定性的度量。
$n^m$是指数形式的,数字可能异常地大,因此我们取了对数,得到$m\log n$,这也可以作为不确定性的度量,它跟我们原来熵的定义是一致的。因为
$$m\log n=-\sum_{i=1}^{n^m} \frac{1}{n^m}\log \frac{1}{n^m}$$
读者可能会疑惑,$n^m$和$m\log n$都算是不确定性的度量,那么究竟是什么原因决定了我们用$m\log n$而不是用$n^m$呢?答案是可加性。取对数后的度量具有可加性,方便我们运算。当然,可加性只是便利的要求,并不是必然的。如果使用$n^m$形式,那么就相应地具有可乘性。
2
Jun
路径积分系列:3.路径积分
By 苏剑林 | 2016-06-02 | 70989位读者 | 引用路径积分是量子力学的一种描述方法,源于物理学家费曼[5],它是一种泛函积分,它已经成为现代量子理论的主流形式. 近年来,研究人员对它的兴趣愈发增加,尤其是它在量子领域以外的应用,出现了一些著作,如[7]. 但在国内了解路径积分的人并不多,很多量子物理专业的学生可能并没有听说过路径积分.
从数学角度来看,路径积分是求偏微分方程的Green函数的一种方法. 我们知道,在偏微分方程的研究中,如果能够求出对应的Green函数,那么对偏微分方程的研究会大有帮助,而通常情况下Green函数并不容易求解. 但构建路径积分只需要无穷小时刻的Green函数,因此形式和概念上都相当简单.
本章并没有新的内容,只是做了一个尝试:从随机游走问题出发,给出路径积分的一个简明而直接的介绍,展示了如何将抛物型的偏微分方程问题转化为路径积分形式.
从点的概率到路径的概率
在上一章对随机游走的研究中,我们得出从$x_0$出发,$t$时间后,走到$x_n$处的概率密度为
$$\frac{1}{\sqrt{2\pi \alpha T}}\exp\left(-\frac{(x_n-x_0)^2}{2\alpha t}\right).\tag{22}$$
这是某时刻某点到另一个时刻另一点的概率,在数学上,我们称之为扩散方程$(21)$的传播子,或者Green函数.
24
Jun
OCR技术浅探:4. 文字定位
By 苏剑林 | 2016-06-24 | 38101位读者 | 引用经过第一部分,我们已经较好地提取了图像的文本特征,下面进行文字定位. 主要过程分两步:1、邻近搜索,目的是圈出单行文字;2、文本切割,目的是将单行文本切割为单字.
邻近搜索
我们可以对提取的特征图进行连通区域搜索,得到的每个连通区域视为一个汉字. 这对于大多数汉字来说是适用,但是对于一些比较简单的汉字却不适用,比如“小”、“旦”、“八”、“元”这些字,由于不具有连通性,所以就被分拆开了,如图13. 因此,我们需要通过邻近搜索算法,来整合可能成字的区域,得到单行的文本区域.

图13 直接搜索连通区域,会把诸如“元”之类的字分拆开
邻近搜索的目的是进行膨胀,以把可能成字的区域“粘合”起来. 如果不进行搜索就膨胀,那么膨胀是各个方向同时进行的,这样有可能把上下行都粘合起来了. 因此,我们只允许区域向单一的一个方向膨胀. 我们正是要通过搜索邻近区域来确定膨胀方向(上、下、左、右):
邻近搜索* 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向.
既然涉及到了邻近,那么就需要有距离的概念. 下面给出一个比较合理的距离的定义.
距离
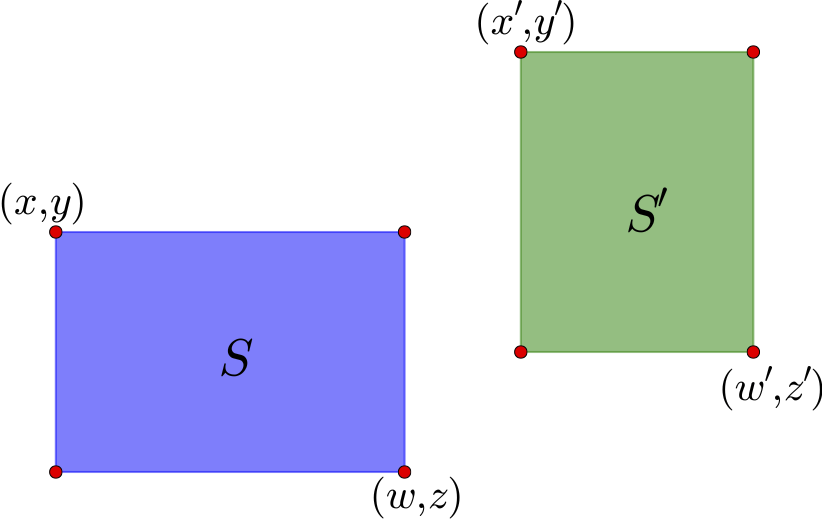
图14 两个示例区域
如上图,通过左上角坐标$(x,y)$和右下角坐标$(z,w)$就可以确定一个矩形区域,这里的坐标是以左上角为原点来算的. 这个区域的中心是$\left(\frac{x+w}{2},\frac{y+z}{2}\right)$. 对于图中的两个区域$S$和$S'$,可以计算它们的中心向量差
$$(x_c,y_c)=\left(\frac{x'+w'}{2}-\frac{x+w}{2},\frac{y'+z'}{2}-\frac{y+z}{2}\right)\tag{10}$$
如果直接使用$\sqrt{x_c^2+y_c^2}$作为距离是不合理的,因为这里的邻近应该是按边界来算,而不是中心点. 因此,需要减去区域的长度:
$$(x'_c,y'_c)=\left(x_c-\frac{w-x}{2}-\frac{w'-x'}{2},y_c-\frac{z-y}{2}-\frac{z'-y'}{2}\right)\tag{11}$$
距离定义为
$$d(S,S')=\sqrt{[\max(x'_c,0)]^2+[\max(y'_c,0)]^2}\tag{12}$$
至于方向,由$(x_c,y_c)$的幅角进行判断即可.
然而,按照前面的“邻近搜索*”方法,容易把上下两行文字粘合起来,因此,基于我们的横向排版假设,更好的方法是只允许横向膨胀:
邻近搜索 从一个连通区域出发,可以找到该连通区域的水平外切矩形,将连通区域扩展到整个矩形. 当该区域与最邻近区域的距离小于一定范围时,考虑这个矩形的膨胀,膨胀的方向是最邻近区域的所在方向,当且仅当所在方向是水平的,才执行膨胀操作.
结果
有了距离之后,我们就可以计算每两个连通区域之间的距离,然后找出最邻近的区域. 我们将每个区域向它最邻近的区域所在的方向扩大4分之一,这样邻近的区域就有可能融合为一个新的区域,从而把碎片整合.
实验表明,邻近搜索的思路能够有效地整合文字碎片,结果如图15.

图15 通过邻近搜索后,圈出的文字区域
24
Jun
OCR技术浅探:5. 文本切割
By 苏剑林 | 2016-06-24 | 43355位读者 | 引用

17
Aug
【中文分词系列】 1. 基于AC自动机的快速分词
By 苏剑林 | 2016-08-17 | 91342位读者 | 引用前言:这个暑假花了不少时间在中文分词和语言模型上面,碰了无数次壁,也得到了零星收获。打算写一个专题,分享一下心得体会。虽说是专题,但仅仅是一些笔记式的集合,并非系统的教程,请读者见谅。
中文分词
关于中文分词的介绍和重要性,我就不多说了,matrix67这里有一篇关于分词和分词算法很清晰的介绍,值得一读。在文本挖掘中,虽然已经有不少文章探索了不分词的处理方法,如本博客的《文本情感分类(三):分词 OR 不分词》,但在一般场合都会将分词作为文本挖掘的第一步,因此,一个有效的分词算法是很重要的。当然,中文分词作为第一步,已经被探索很久了,目前做的很多工作,都是总结性质的,最多是微弱的改进,并不会有很大的变化了。
目前中文分词主要有两种思路:查词典和字标注。首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。查词典的方法简单高效(得益于动态规划的思想),尤其是结合了语言模型的最大概率法,能够很好地解决歧义问题,但对于中文分词一大难度——未登录词(中文分词有两大难度:歧义和未登录词),则无法解决;为此,人们也提出了基于字标注的思路,所谓字标注,就是通过几个标记(比如4标注的是:single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾),把句子的正确分词法表示出来。这是一个序列(输入句子)到序列(标记序列)的过程,能够较好地解决未登录词的问题,但速度较慢,而且对于已经有了完备词典的场景下,字标注的分词效果可能也不如查词典方法。总之,各有优缺点(似乎是废话~),实际使用可能会结合两者,像结巴分词,用的是有向无环图的最大概率组合,而对于连续的单字,则使用字标注的HMM模型来识别。

最近评论