






15
May
Coming Back...
By 苏剑林 | 2016-05-15 | 38288位读者 | 引用上一篇博文的发布时间是4月15日,到今天刚好一个月没更新了,但是科学空间的访问量还在。感谢大家对本空间的支持,BoJone对久未更新表示非常抱歉。在恢复更新之前,请允许笔者记记流水账。
在“消失”的一个月中,笔者主要的事情是毕业论文和数据挖掘竞赛。首先毕业论文方面,论文于4月22日交稿,4月29日答辩,答辩完后就意味着毕业论文的事情结束了。我的毕业论文主要写了路径积分在描述随机游走、偏微分方程、随机微分方程的应用。既然是本科论文,就不能说得太晦涩,因此论文整体来看还是比较易读的,可以作为路径积分的入门教程。后面我会略加修改,分开几部分发布在科学空间中的,到时请大家批评指正。
说到路径积分,不得不说到做《量子力学与路径积分》的习题解答这件事情了。很遗憾,这一个多月来,基本没有时间做习题。不过后面我会继续做下去的,已发布的版本,也请有兴趣的读者指出问题。记得年初的时候,朋友问我今年的愿望是什么,我随意地回答了“希望做完一本书的习题”,这本书,当然就是《量子力学与路径积分》了,我相信今年应该能够完成的。
12
Apr
【备忘】用树莓派3做无线路由器
By 苏剑林 | 2016-04-12 | 65015位读者 | 引用3月初发布的树莓派3自带了WiFi和蓝牙,再加上它本来就有一个网口,因此俨然就是一台无线路由器了。我也忍不住入手了一个,打算用来做路由器和NAS。树莓派做路由器的教程已经有很多了,当然,基本都是基于树莓派2的,3之前的版本都没有自带WiFi,因此需要自己配无线网卡,而3自带了无线网卡,配置就方便多了。参考了两篇外文教程,成功配置,在这里记录一下。
参考教程:
https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
https://gist.github.com/Lewiscowles1986/fecd4de0b45b2029c390#file-rpi3-ap-setup-sh
2
Jun
路径积分系列:3.路径积分
By 苏剑林 | 2016-06-02 | 74155位读者 | 引用路径积分是量子力学的一种描述方法,源于物理学家费曼[5],它是一种泛函积分,它已经成为现代量子理论的主流形式. 近年来,研究人员对它的兴趣愈发增加,尤其是它在量子领域以外的应用,出现了一些著作,如[7]. 但在国内了解路径积分的人并不多,很多量子物理专业的学生可能并没有听说过路径积分.
从数学角度来看,路径积分是求偏微分方程的Green函数的一种方法. 我们知道,在偏微分方程的研究中,如果能够求出对应的Green函数,那么对偏微分方程的研究会大有帮助,而通常情况下Green函数并不容易求解. 但构建路径积分只需要无穷小时刻的Green函数,因此形式和概念上都相当简单.
本章并没有新的内容,只是做了一个尝试:从随机游走问题出发,给出路径积分的一个简明而直接的介绍,展示了如何将抛物型的偏微分方程问题转化为路径积分形式.
从点的概率到路径的概率
在上一章对随机游走的研究中,我们得出从$x_0$出发,$t$时间后,走到$x_n$处的概率密度为
$$\frac{1}{\sqrt{2\pi \alpha T}}\exp\left(-\frac{(x_n-x_0)^2}{2\alpha t}\right).\tag{22}$$
这是某时刻某点到另一个时刻另一点的概率,在数学上,我们称之为扩散方程$(21)$的传播子,或者Green函数.
18
Jun
OCR技术浅探:3. 特征提取(2)
By 苏剑林 | 2016-06-18 | 38629位读者 | 引用
25
Jun
OCR技术浅探:6. 光学识别
By 苏剑林 | 2016-06-25 | 71654位读者 | 引用经过第一、二步,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别.
模型选择
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型.
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型. 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果. 事实上,我们选择卷积神经网络的主要原因有:
1. 对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2. 比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3. 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的.
17
Jun
OCR技术浅探:1. 全文简述
By 苏剑林 | 2016-06-17 | 43818位读者 | 引用写在前面:前面的博文已经提过,在上个月我参加了第四届泰迪杯数据挖掘竞赛,做的是A题,跟OCR系统有些联系,还承诺过会把最终的结果开源。最近忙于毕业、搬东西,一直没空整理这些内容,现在抽空整理一下。
把结果发出来,并不是因为结果有多厉害、多先进(相反,当我对比了百度的这篇论文《基于深度学习的图像识别进展:百度的若干实践》之后,才发现论文的内容本质上还是传统那一套,远远还跟不上时代的潮流),而是因为虽然OCR技术可以说比较成熟了,但网络上根本就没有对OCR系统进行较为详细讲解的文章,而本文就权当补充这部分内容吧。我一直认为,技术应该要开源才能得到发展(当然,在中国这一点也确实值得商榷,因为开源很容易造成山寨),不管是数学物理研究还是数据挖掘,我大多数都会发表到博客中,与大家交流。
17
Jun
OCR技术浅探:2. 背景与假设
By 苏剑林 | 2016-06-17 | 38331位读者 | 引用研究背景
关于光学字符识别(Optical Character Recognition, 下面都简称OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不少成熟的OCR技术和产品产生,比如汉王OCR、ABBYY FineReader、Tesseract OCR等. 值得一提的是,ABBYY FineReader不仅正确率高(包括对中文的识别),而且还能保留大部分的排版效果,是一个非常强大的OCR商业软件.
然而,在诸多的OCR成品中,除了Tesseract OCR外,其他的都是闭源的、甚至是商业的软件,我们既无法将它们嵌入到我们自己的程序中,也无法对其进行改进. 开源的唯一选择是Google的Tesseract OCR,但它的识别效果不算很好,而且中文识别正确率偏低,有待进一步改进.
综上所述,不管是为了学术研究还是实际应用,都有必要对OCR技术进行探究和改进. 我们队伍将完整的OCR系统分为“特征提取”、“文字定位”、“光学识别”、“语言模型”四个方面,逐步进行解决,最终完成了一个可用的、完整的、用于印刷文字的OCR系统. 该系统可以初步用于电商、微信等平台的图片文字识别,以判断上面信息的真伪.
研究假设
在本文中,我们假设图像的文字部分有以下的特征:
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 55744位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
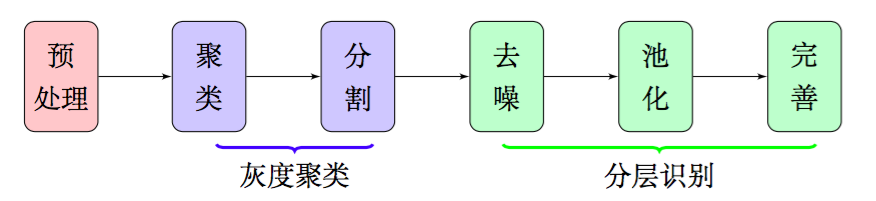
图2:特征提取大概流程

最近评论