






27
Jun
从动力学角度看优化算法(一):从SGD到动量加速
By 苏剑林 | 2018-06-27 | 161922位读者 | 引用在这个系列中,我们来关心优化算法,而本文的主题则是SGD(stochastic gradient descent,随机梯度下降),包括带Momentum和Nesterov版本的。对于SGD,我们通常会关心的几个问题是:
SGD为什么有效?
SGD的batch size是不是越大越好?
SGD的学习率怎么调?
Momentum是怎么加速的?
Nesterov为什么又比Momentum稍好?
...
这里试图从动力学角度分析SGD,给出上述问题的一些启发性理解。
梯度下降
既然要比较谁好谁差,就需要知道最好是什么样的,也就是说我们的终极目标是什么?
训练目标分析
假设全部训练样本的集合为$\boldsymbol{S}$,损失度量为$L(\boldsymbol{x};\boldsymbol{\theta})$,其中$\boldsymbol{x}$代表单个样本,而$\boldsymbol{\theta}$则是优化参数,那么我们可以构建损失函数
$$L(\boldsymbol{\theta}) = \frac{1}{|\boldsymbol{S}|}\sum_{\boldsymbol{x}\in\boldsymbol{S}} L(\boldsymbol{x};\boldsymbol{\theta})\tag{1}$$
而训练的终极目标,则是找到$L(\boldsymbol{\theta})$的一个全局最优点(这里的最优是“最小”的意思)。
20
Jan
从Wasserstein距离、对偶理论到WGAN
By 苏剑林 | 2019-01-20 | 214168位读者 | 引用
推土机哪家强?成本最低找Wasserstein
2017年的时候笔者曾写过博文《互怼的艺术:从零直达WGAN-GP》,从一个相对通俗的角度来介绍了WGAN,在那篇文章中,WGAN更像是一个天马行空的结果,而实际上跟Wasserstein距离没有多大关系。
在本篇文章中,我们再从更数学化的视角来讨论一下WGAN。当然,本文并不是纯粹地讨论GAN,而主要侧重于Wasserstein距离及其对偶理论的理解。本文受启发于著名的国外博文《Wasserstein GAN and the Kantorovich-Rubinstein Duality》,内容跟它大体上相同,但是删除了一些冗余的部分,对不够充分或者含糊不清的地方作了补充。不管怎样,在此先对前辈及前辈的文章表示致敬。
(注:完整理解本文,应该需要多元微积分、概率论以及线性代数等基础知识。还有,本文确实长,数学公式确实多,但是,真的不复杂、不难懂,大家不要看到公式就吓怕了~)
23
Mar
AdaFactor优化器浅析(附开源实现)
By 苏剑林 | 2020-03-23 | 85525位读者 | 引用自从GPT、BERT等预训练模型流行起来后,其中一个明显的趋势是模型越做越大,因为更大的模型配合更充分的预训练通常能更有效地刷榜。不过,理想可以无限远,现实通常很局促,有时候模型太大了,大到哪怕你拥有了大显存的GPU甚至TPU,依然会感到很绝望。比如GPT2最大的版本有15亿参数,最大版本的T5模型参数量甚至去到了110亿,这等规模的模型,哪怕在TPU集群上也没法跑到多大的batch size。
这时候通常要往优化过程着手,比如使用混合精度训练(tensorflow下还可以使用一种叫做bfloat16的新型浮点格式),即省显存又加速训练;又或者使用更省显存的优化器,比如RMSProp就比Adam更省显存。本文则介绍AdaFactor,一个由Google提出来的新型优化器,首发论文为《Adafactor: Adaptive Learning Rates with Sublinear Memory Cost》。AdaFactor具有自适应学习率的特性,但比RMSProp还要省显存,并且还针对性地解决了Adam的一些缺陷。
Adam
首先我们来回顾一下常用的Adam优化器的更新过程。设$t$为迭代步数,$\alpha_t$为当前学习率,$L(\theta)$是损失函数,$\theta$是待优化参数,$\epsilon$则是防止溢出的小正数,那么Adam的更新过程为
27
Oct
TeaForN:让Teacher Forcing更有“远见”一些
By 苏剑林 | 2020-10-27 | 40866位读者 | 引用Teacher Forcing是Seq2Seq模型的经典训练方式,而Exposure Bias则是Teacher Forcing的经典缺陷,这对于搞文本生成的同学来说应该是耳熟能详的事实了。笔者之前也曾写过博文《Seq2Seq中Exposure Bias现象的浅析与对策》,初步地分析过Exposure Bias问题。
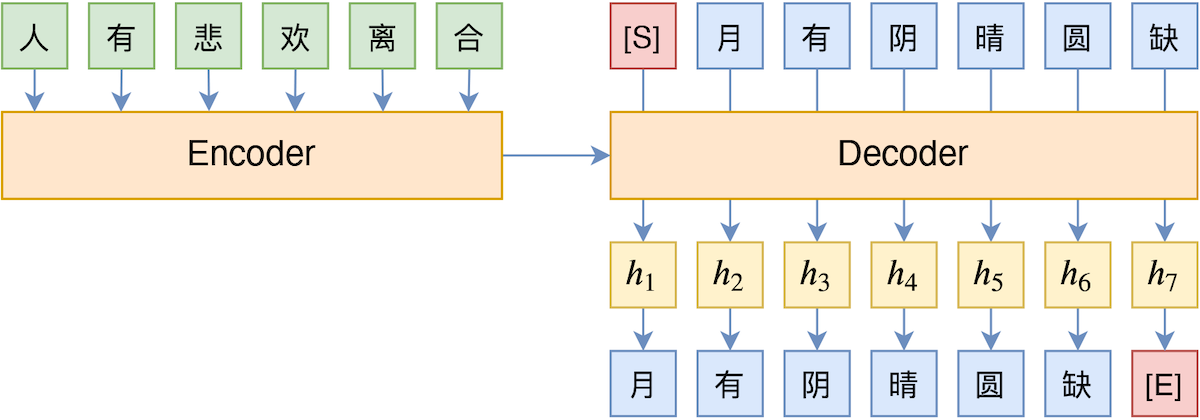
Teacher Forcing示意图
本文则介绍Google新提出的一种名为“TeaForN”的缓解Exposure Bias现象的方案,来自论文《TeaForN: Teacher-Forcing with N-grams》,它通过嵌套迭代的方式,让模型能提前预估到后$N$个token(而不仅仅是当前要预测的token),其处理思路上颇有可圈可点之处,值得我们学习。
(注:为了尽量跟本博客旧文章保持一致,本文的记号与原论文的记号有所不同,请大家以理解符号含义为主,不要强记符号形式。)
22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 66468位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。
12
Jan
CoSENT(二):特征式匹配与交互式匹配有多大差距?
By 苏剑林 | 2022-01-12 | 90560位读者 | 引用一般来说,文本匹配有交互式(Interaction-based)和特征式(Representation-based)两种实现方案,其中交互式是指将两个文本拼接在一起当成单文本进行分类,而特征式则是指两个句子分别由编码器编码为句向量后再做简单的融合处理(算cos值或者接一个浅层网络)。通常的结论是,交互式由于使得两个文本能够进行充分的比较,所以它准确性通常较好,但明显的缺点是在检索场景的效率较差;而特征式则可以提前计算并缓存好句向量,所以它有着较高的效率,但由于句子间的交互程度较浅,所以通常效果不如交互式。
上一篇文章笔者介绍了CoSENT,它本质上也是一种特征式方案,并且相比以往的特征式方案效果有所提高。于是笔者的好胜心就上来了:CoSENT能比得过交互式吗?特征式相比交互式的差距有多远呢?本文就来做个比较。
自动阈值
在文章《CoSENT(一):比Sentence-BERT更有效的句向量方案》中,我们评测CoSENT所用的指标是Spearman系数,它是一个只依赖于预测结果相对顺序的指标,不依赖于阈值,比较适合检索场景的评测。但如果评测指标是accuracy或者F1这些分类指标,则必须确定一个阈值,将预测结果大于这个数的预测结果视为正、小于则为负,然后才能计算指标。在二分类的场景,我们用二分法就可以有效地确定这个阈值。
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 76710位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
12
Aug
生成扩散模型漫谈(七):最优扩散方差估计(上)
By 苏剑林 | 2022-08-12 | 77209位读者 | 引用对于生成扩散模型来说,一个很关键的问题是生成过程的方差应该怎么选择,因为不同的方差会明显影响生成效果。
在《生成扩散模型漫谈(二):DDPM = 自回归式VAE》我们提到,DDPM分别假设数据服从两种特殊分布推出了两个可用的结果;《生成扩散模型漫谈(四):DDIM = 高观点DDPM》中的DDIM则调整了生成过程,将方差变为超参数,甚至允许零方差生成,但方差为0的DDIM的生成效果普遍差于方差非0的DDPM;而《生成扩散模型漫谈(五):一般框架之SDE篇》显示前、反向SDE的方差应该是一致的,但这原则上在$\Delta t\to 0$时才成立;《Improved Denoising Diffusion Probabilistic Models》则提出将它视为可训练参数来学习,但会增加训练难度。
所以,生成过程的方差究竟该怎么设置呢?今年的两篇论文《Analytic-DPM: an Analytic Estimate of the Optimal Reverse Variance in Diffusion Probabilistic Models》和《Estimating the Optimal Covariance with Imperfect Mean in Diffusion Probabilistic Models》算是给这个问题提供了比较完美的答案。接下来我们一起欣赏一下它们的结果。

最近评论