






11
Dec
“熵”不起:从熵、最大熵原理到最大熵模型(二)
By 苏剑林 | 2015-12-11 | 85272位读者 | 引用上集回顾
在第一篇中,笔者介绍了“熵”这个概念,以及它的一些来龙去脉。熵的公式为
$$S=-\sum_x p(x)\log p(x)\tag{1}$$
或
$$S=-\int p(x)\log p(x) dx\tag{2}$$
并且在第一篇中,我们知道熵既代表了不确定性,又代表了信息量,事实上它们是同一个概念。
说完了熵这个概念,接下来要说的是“最大熵原理”。最大熵原理告诉我们,当我们想要得到一个随机事件的概率分布时,如果没有足够的信息能够完全确定这个概率分布(可能是不能确定什么分布,也可能是知道分布的类型,但是还有若干个参数没确定),那么最为“保险”的方案是选择使得熵最大的分布。
最大熵原理
承认我们的无知
很多文章在介绍最大熵原理的时候,会引用一句著名的句子——“不要把鸡蛋放在同一个篮子里”——来通俗地解释这个原理。然而,笔者窃以为这句话并没有抓住要点,并不能很好地体现最大熵原理的要义。笔者认为,对最大熵原理更恰当的解释是:承认我们的无知!
6
Jun
闲聊:神经网络与深度学习
By 苏剑林 | 2015-06-06 | 70154位读者 | 引用
神经网络
在所有机器学习模型之中,也许最有趣、最深刻的便是神经网络模型了。笔者也想献丑一番,说一次神经网络。当然,本文并不打算从头开始介绍神经网络,只是谈谈我对神经网络的个人理解。如果希望进一步了解神经网络与深度学习的朋友,请移步阅读下面的教程:
http://deeplearning.stanford.edu/wiki/index.php/UFLDL教程
http://blog.csdn.net/zouxy09/article/details/8775360
机器分类
这里以分类工作为例,数据挖掘或机器学习中,有很多分类的问题,比如讲一句话的情况进行分类,粗略点可以分类为“积极”或“消极”,精细点分为开心、生气、忧伤等;另外一个典型的分类问题是手写数字识别,也就是将图片分为10类(0,1,2,3,4,5,6,7,8,9)。因此,也产生了很多分类的模型。
13
Nov
ARXIV数学论文分布:偏微分方程最热门!
By 苏剑林 | 2015-11-13 | 31990位读者 | 引用笔者成功地保研到了中山大学的基础数学专业,这个专业自然是比较理论性的,虽然如此,我还会保持着我对数据分析、计算机等方面的兴趣。这几天兴致来了,想做一下结合我的专业跟数据挖掘相结合的研究,所以就爬取了ARXIV上面近五年(2010年到2014年)的数学论文(包含的数据有:标题、分类、年份、月份),想对这几年来数学的“行情”做一下简单的分析。个人认为,ARVIX作为目前全球最大的论文预印本的电子数据库,对它的数据进行分析,所得到的结论是能够具有一定的代表性的。
当然,本文只是用来练手爬虫和基本数据分析的文章,并没有挖掘出特别有价值的信息。文末附录了笔者爬取到的数据,供有兴趣的读者进一步分析研究。
整体情况
这五年来,ARXIV的数学论文总数为135009篇,平均每年27000篇,或者每天74篇。
26
Dec
费曼路径积分思想的发展(一)
By 苏剑林 | 2012-12-26 | 28824位读者 | 引用注:这是郝刘祥前辈的一篇论文,98年的时候发表在《自然辩证法通讯》上,里边讲述了费曼以及路径积分的相关故事。我从网上下载下来,原文是很粗糙的pdf文件,我特意将它转化为网页文件,供大家欣赏。有些公式很模糊,所以我已经到图书馆查找了原文,但是由于作者非理论物理专业人员,还不确定部分公式是否正确,请读者慎读。原文较长,将分开几篇来发。如果涉及到版权问题,请作者告之(bojone@spaces.ac.cn),我将会尽快处理掉。
自然辩证法通讯(JOURNAL OF DIALECTICS OF NATURE)
第二十卷总115期,1998第3期
郝刘祥
摘要:该文首先阐述了 Richard Feynman为解决经典电动力学的发散问题而做的艰苦努力,进而论述了这种努力的副产品何以使他偏爱作用量表述,以及他是如何在Dirac文章的启发下得到非相对论量子力学的第三种形式--作用量量子化方案的。文章的第三部分叙述了费曼将其方案推广到相对论情形的尝试和费曼图的由来。最后,该文试图就路径积分方法在量子场论等领域中的广泛应用以及费曼对量子场论的重大疑惑作一简要的说明。
关键词:费曼,作用量,几率幅,路径积分
很早以前我就对这个问题感兴趣了,但是一直搁置着,没有怎么研究。最近在阅读《引力与时空》的“潮汐力”那一节时重新回到了这个问题上,决定写点什么东西。在这里不深究流体静力平衡的定义,顾名思义地理解,它就是流体在某个特定的力场下所达到的平衡状态。流体静力学告诉我们:
达到流体静力平衡时,流体的面必定是一个等势面。
这是为什么呢?我们从数学的角度来简单分析一下:只考虑二维情况,假如等势面方程是$U(x,y)=C$,那么两边微分就有
$$0=dU=\frac{\partial U}{\partial x}dx+\frac{\partial U}{\partial y}dy=(\frac{\partial U}{\partial x},\frac{\partial U}{\partial y})\cdot (dx,dy)$$
这意味着向量$(\frac{\partial U}{\partial x},\frac{\partial U}{\partial y})$和向量$(dx,dy)$是垂直的,前者便是力的函数,后者就是一个切向量(三维就是一个切平面)。也就是说合外力必然和流体面垂直,这样才能提供一个相等的方向相反的内力让整个结构体系处于平衡状态!
1
May
【不可思议的Word2Vec】 4.不一样的“相似”
By 苏剑林 | 2017-05-01 | 143579位读者 | 引用相似度的定义
当用Word2Vec得到词向量后,一般我们会用余弦相似度来比较两个词的相似程度,定义为
$$\cos (\boldsymbol{x}, \boldsymbol{y}) = \frac{\boldsymbol{x}\cdot\boldsymbol{y}}{|\boldsymbol{x}|\times|\boldsymbol{y}|}$$
有了这个相似度概念,我们既可以比较任意两个词之间的相似度,也可以找出跟给定词最相近的词语。这在gensim的Word2Vec中,由most_similar函数实现。
等等!我们很快给出了相似度的计算公式,可是我们居然还没有“定义”相似!连相似都没有定义,怎么就得到了评估相似度的数学公式了呢?
要注意,这不是一个可以随意忽略的问题。很多时候我们都不知道我们干的是什么,就直接去干了。好比上一篇文章说到提取关键词,相信很多人都未曾想过,什么是关键词,难道就仅仅说关键词就是很“关键”的词?而如果想到,关键词就是用来估计文章大概讲什么的,这样我们就得到一种很自然的关键词定义
$$keywords = \mathop{\text{argmax}}_{w\in s}p(s|w)$$
进而可以用各种方法对它建模。
回到本文的主题来,相似度怎么定义呢?答案是:看场景定义所需要的相似。
2
May
基于Conv1D的光谱分类模型(一维序列分类)
By 苏剑林 | 2018-05-02 | 119310位读者 | 引用前段时间天池出了个天文数据挖掘竞赛——LAMOST光谱分类(将对应的光谱识别为4类中的一类),虽然没有奖金,但还是觉得挺有意思,所以就报名参加了。做了一段时间,成绩自我感觉还可以,然而最后我却忘记了(或者说根本就没留意到)初赛最后两天还有一步是提交新的测试集结果,然后就没有然后了,留下了一个未竟的模型,可谓“出师未捷身先死”,还是被自己弄死的~

天文数据挖掘大赛——天体光谱智能分类
后来跟其他参赛选手讨论了一下,发现其实我的这个模型还是不错的。当时我记得初赛第一名的成绩是0.83+,而我当时的成绩是0.82+,排名大概是第4、5左右,而且据说很多分数在0.8+的队伍都已经使用了融合模型,而我这0.82+的成绩仅仅是单模型的结果~在平时的群聊中发现也有不少朋友在做一维序列分类模型,而光谱分类本质上也就是一个一维的序列分类,所以分享一下模型,估计对相关朋友会有一定的参考价值。
模型
事实上也不是什么特别的模型,就是普通的一维卷积加残差,对于熟悉图像处理的朋友,这实在是再普通不过的结构了。
24
Mar
基于CNN和VAE的作诗机器人:随机成诗
By 苏剑林 | 2018-03-24 | 126429位读者 | 引用前几日写了一篇VAE的通俗解读,也得到了一些读者的认可。然而,你是否厌倦了每次介绍都只有一个MNIST级别的demo?不要急,这就给大家带来一个更经典的VAE玩具:机器人作诗。
为什么说“更经典”呢?前一篇文章我们说过用VAE生成的图像相比GAN生成的图像会偏模糊,也就是在图像这一“仗”上,VAE是劣势。然而,在文本生成这一块上,VAE却漂亮地胜出了。这是因为GAN希望把判别器(度量)也直接训练出来,然而对于文本来说,这个度量很可能是离散的、不可导的,因此纯GAN就很难训练了。而VAE中没有这个步骤,它是通过重构输入来完成的,这个重构过程对于图像还是文本都可以进行。所以,文本生成这件事情,对于VAE来说它就跟图像生成一样,都是一个基本的、直接的应用;对于(目前的)GAN来说,却是艰难的象征,是它挥之不去的“心病”。
嗯,古有曹植七步作诗,今有VAE随机成诗,让我们开始吧~
模型
对于很多人来说,诗是一个很美妙的玩意,美妙之处在于大多数人都不真正懂得诗,但大家对诗的模样又有一知半解的认识。因此,只要生成的“诗”稍微像模像样一点,我们通常都会认为机器人可以作诗了。因此,所谓作诗机器人,是一个纯粹的玩具了,能作几句诗,也不意味着普通语言的生成能力有多好,也不意味着我们对NLP的理解有多深。
CNN + VAE
就本文的玩具而言,其实是一个比较简单的模型,主要是把一维CNN和VAE结合了起来。因为生成的诗长度是固定的,所以不管是encoder还是decoder,我都只是用了纯CNN来做。模型的结构图大概是:
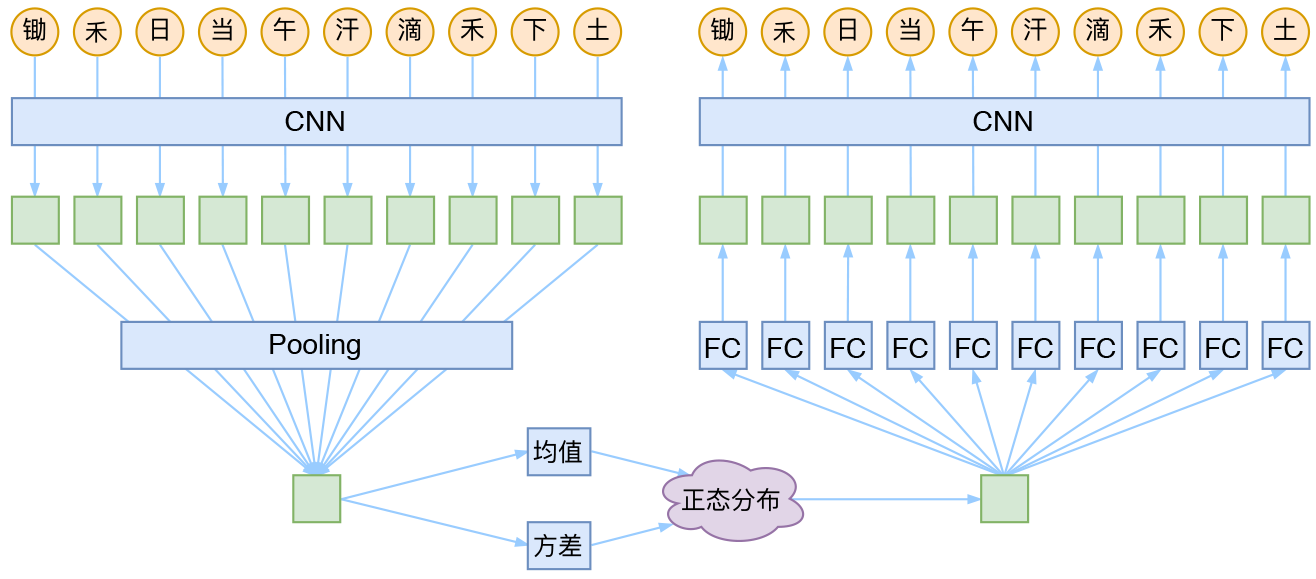
cnn + vae 诗歌生成模型

最近评论