






30
Oct
缅怀金庸 | 愿你登上10930小行星继续翱翔
By 苏剑林 | 2018-10-30 | 19495位读者 | 引用
金庸大师
金庸走了,享年94岁。
虽然说这些高龄大师们,不管是科学家还是文学家,他们在晚年基本上都不会有什么产出,过于理性的话会有“去了就去了,好像也没有什么损失”的感觉。然而,事实是大师的逝去总让我们有一种悲伤的震撼感,总让我们觉得似乎一个时代又逝去了。霍金是这样,金庸也是这样。
对于金老爷子来说,是一个武侠时代过去了,是一个江湖过去了。
飞雪连天射白鹿,笑书神侠倚碧鸳。
这个对联描述了金庸的14部作品,加上《越女剑》,就构成了他的15部武侠小说。金庸用这15部小说,描述了一个个活灵活现的江湖,不,说江湖好象都太小了,读完这15部作品,你会感觉他描述了整个中国几千年的历史、整个社会。
1
Dec
级联抑制:提升GAN表现的一种简单有效的方法
By 苏剑林 | 2019-12-01 | 28731位读者 | 引用昨天刷arxiv时发现了一篇来自星星韩国的论文,名字很直白,就叫做《A Simple yet Effective Way for Improving the Performance of GANs》。打开一看,发现内容也很简练,就是提出了一种加强GAN的判别器的方法,能让GAN的生成指标有一定的提升。
作者把这个方法叫做Cascading Rejection,我不知道咋翻译,扔到百度翻译里边显示“级联抑制”,想想看好像是有这么点味道,就暂时这样叫着了。介绍这个方法倒不是因为它有多强大,而是觉得它的几何意义很有趣,而且似乎有一定的启发性。
正交分解
GAN的判别器一般是经过多层卷积后,通过flatten或pool得到一个固定长度的向量$\boldsymbol{v}$,然后再与一个权重向量$\boldsymbol{w}$做内积,得到一个标量打分(先不考虑偏置项和激活函数等末节):
\begin{equation}D(\boldsymbol{x})=\langle \boldsymbol{v},\boldsymbol{w}\rangle\end{equation}
也就是说,用$\boldsymbol{v}$作为输入图片的表征,然后通过$\boldsymbol{v}$和$\boldsymbol{w}$的内积大小来判断出这个图片的“真”的程度。
29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 117557位读者 | 引用在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
29
Jan
抛开约束,增强模型:一行代码提升albert表现
By 苏剑林 | 2020-01-29 | 64296位读者 | 引用
26
Mar
GELU的两个初等函数近似是怎么来的
By 苏剑林 | 2020-03-26 | 39406位读者 | 引用GELU,全称为Gaussian Error Linear Unit,也算是RELU的变种,是一个非初等函数形式的激活函数。它由论文《Gaussian Error Linear Units (GELUs)》提出,后来被用到了GPT中,再后来被用在了BERT中,再再后来的不少预训练语言模型也跟着用到了它。随着BERT等预训练语言模型的兴起,GELU也跟着水涨船高,莫名其妙地就成了热门的激活函数了。
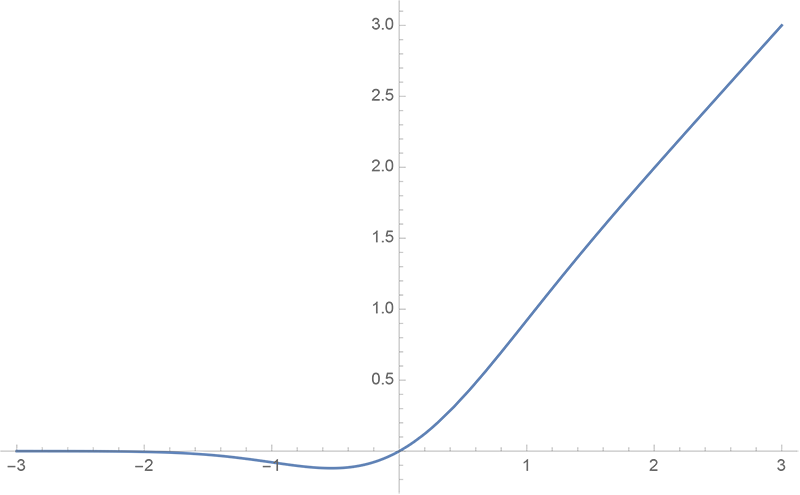
gelu函数图像
在GELU的原始论文中,作者不仅提出了GELU的精确形式,还给出了两个初等函数的近似形式,本文来讨论它们是怎么得到的。
18
Jul
也来扯几句“全国青少年科技创新大赛”
By 苏剑林 | 2020-07-18 | 26582位读者 | 引用
25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 83440位读者 | 引用机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
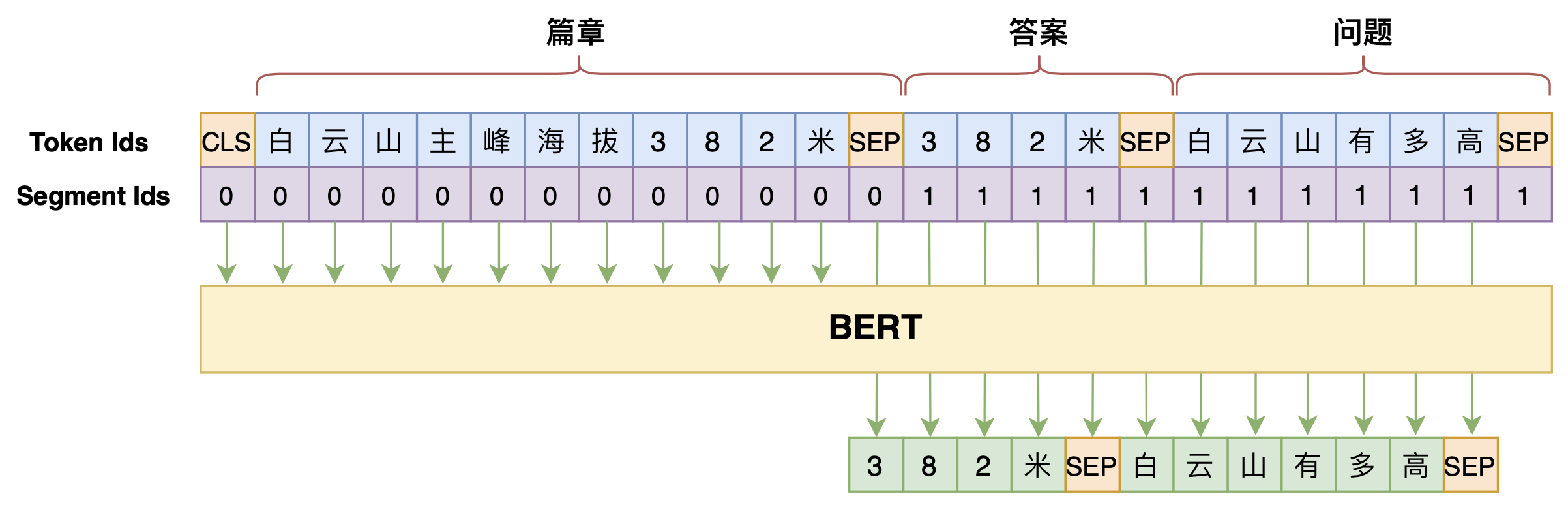
本文的问答生成模型示意图
9
Oct

最近评论