






17
Jun
OCR技术浅探:1. 全文简述
By 苏剑林 | 2016-06-17 | 44549位读者 | 引用写在前面:前面的博文已经提过,在上个月我参加了第四届泰迪杯数据挖掘竞赛,做的是A题,跟OCR系统有些联系,还承诺过会把最终的结果开源。最近忙于毕业、搬东西,一直没空整理这些内容,现在抽空整理一下。
把结果发出来,并不是因为结果有多厉害、多先进(相反,当我对比了百度的这篇论文《基于深度学习的图像识别进展:百度的若干实践》之后,才发现论文的内容本质上还是传统那一套,远远还跟不上时代的潮流),而是因为虽然OCR技术可以说比较成熟了,但网络上根本就没有对OCR系统进行较为详细讲解的文章,而本文就权当补充这部分内容吧。我一直认为,技术应该要开源才能得到发展(当然,在中国这一点也确实值得商榷,因为开源很容易造成山寨),不管是数学物理研究还是数据挖掘,我大多数都会发表到博客中,与大家交流。
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 56623位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
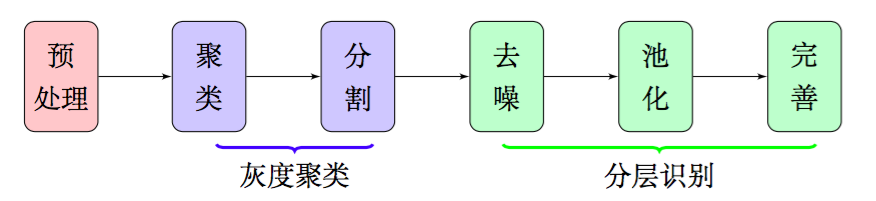
图2:特征提取大概流程
26
Jun
OCR技术浅探:9. 代码共享(完)
By 苏剑林 | 2016-06-26 | 69236位读者 | 引用
26
Jun
OCR技术浅探:8. 综合评估
By 苏剑林 | 2016-06-26 | 29650位读者 | 引用数据验证
尽管在测试环境下模型工作良好,但是实践是检验真理的唯一标准. 在本节中,我们通过自己的模型,与京东的测试数据进行比较验证.
衡量OCR系统的好坏有两部分内容:(1)是否成功地圈出了文字;(2)对于圈出来的文字,有没有成功识别. 我们采用评分的方法,对每一张图片的识别效果进行评分. 评分规则如下:
如果圈出的文字区域能够跟京东提供的检测样本的box文件中匹配,那么加1分,如果正确识别出文字来,另外加1分,最后每张图片的分数是前面总分除以文字总数.
按照这个规则,每张图片的评分最多是2分,最少是0分. 如果评分超过1,说明识别效果比较好了. 经过京东的测试数据比较,我们的模型平均评分大约是0.84,效果差强人意。
12
Sep
【中文分词系列】 5. 基于语言模型的无监督分词
By 苏剑林 | 2016-09-12 | 151687位读者 | 引用迄今为止,前四篇文章已经介绍了分词的若干思路,其中有基于最大概率的查词典方法、基于HMM或LSTM的字标注方法等。这些都是已有的研究方法了,笔者所做的就只是总结工作而已。查词典方法和字标注各有各的好处,我一直在想,能不能给出一种只需要大规模语料来训练的无监督分词模型呢?也就是说,怎么切分,应该是由语料来决定的,跟语言本身没关系。说白了,只要足够多语料,就可以告诉我们怎么分词。
看上去很完美,可是怎么做到呢?《2.基于切分的新词发现》中提供了一种思路,但是不够彻底。那里居于切分的新词发现方法确实可以看成一种无监督分词思路,它就是用一个简单的凝固度来判断某处该不该切分。但从分词的角度来看,这样的分词系统未免太过粗糙了。因此,我一直想着怎么提高这个精度,前期得到了一些有意义的结果,但都没有得到一个完整的理论。而最近正好把这个思路补全了。因为没有查找到类似的工作,所以这算是笔者在分词方面的一点原创工作了。
语言模型
首先简单谈一下语言模型。
11
Mar
【中文分词系列】 8. 更好的新词发现算法
By 苏剑林 | 2017-03-11 | 229641位读者 | 引用如果依次阅读该系列文章的读者,就会发现这个系列共提供了两种从0到1的无监督分词方案,第一种就是《【中文分词系列】 2. 基于切分的新词发现》,利用相邻字凝固度(互信息)来做构建词库(有了词库,就可以用词典法分词);另外一种是《【中文分词系列】 5. 基于语言模型的无监督分词》,后者基本上可以说是提供了一种完整的独立于其它文献的无监督分词方法。
但总的来看,总感觉前面一种很快很爽,却又显得粗糙;后面一种很好很强大,却又显得太过复杂(viterbi是瓶颈之一)。有没有可能在两者之间折中一下?这就导致了本文的结果,达到了速度与效果的平衡。至于为什么说“更好”?因为笔者研究词库构建也有一段时间了,以往构建的词库总不能让人(让自己)满意,生成的词库一眼看上去,都能够扫到不少不合理的地方,真的要用得需要经过较多的人工筛选。而这一次,一次性生成的词库,一眼扫过去,不合理的地方少了很多,如果不细看,可能就发现不了了。
分词的目的
1
May
【不可思议的Word2Vec】 4.不一样的“相似”
By 苏剑林 | 2017-05-01 | 142596位读者 | 引用相似度的定义
当用Word2Vec得到词向量后,一般我们会用余弦相似度来比较两个词的相似程度,定义为
$$\cos (\boldsymbol{x}, \boldsymbol{y}) = \frac{\boldsymbol{x}\cdot\boldsymbol{y}}{|\boldsymbol{x}|\times|\boldsymbol{y}|}$$
有了这个相似度概念,我们既可以比较任意两个词之间的相似度,也可以找出跟给定词最相近的词语。这在gensim的Word2Vec中,由most_similar函数实现。
等等!我们很快给出了相似度的计算公式,可是我们居然还没有“定义”相似!连相似都没有定义,怎么就得到了评估相似度的数学公式了呢?
要注意,这不是一个可以随意忽略的问题。很多时候我们都不知道我们干的是什么,就直接去干了。好比上一篇文章说到提取关键词,相信很多人都未曾想过,什么是关键词,难道就仅仅说关键词就是很“关键”的词?而如果想到,关键词就是用来估计文章大概讲什么的,这样我们就得到一种很自然的关键词定义
$$keywords = \mathop{\text{argmax}}_{w\in s}p(s|w)$$
进而可以用各种方法对它建模。
回到本文的主题来,相似度怎么定义呢?答案是:看场景定义所需要的相似。
22
Jul
Keras中自定义复杂的loss函数
By 苏剑林 | 2017-07-22 | 436660位读者 | 引用Keras是一个搭积木式的深度学习框架,用它可以很方便且直观地搭建一些常见的深度学习模型。在tensorflow出来之前,Keras就已经几乎是当时最火的深度学习框架,以theano为后端,而如今Keras已经同时支持四种后端:theano、tensorflow、cntk、mxnet(前三种官方支持,mxnet还没整合到官方中),由此可见Keras的魅力。
Keras是很方便,然而这种方便不是没有代价的,最为人诟病之一的缺点就是灵活性较低,难以搭建一些复杂的模型。的确,Keras确实不是很适合搭建复杂的模型,但并非没有可能,而是搭建太复杂的模型所用的代码量,跟直接用tensorflow写也差不了多少。但不管怎么说,Keras其友好、方便的特性(比如那可爱的训练进度条),使得我们总有使用它的场景。这样,如何更灵活地定制Keras模型,就成为一个值得研究的课题了。这篇文章我们来关心自定义loss。
输入-输出设计
Keras的模型是函数式的,即有输入,也有输出,而loss即为预测值与真实值的某种误差函数。Keras本身也自带了很多loss函数,如mse、交叉熵等,直接调用即可。而要自定义loss,最自然的方法就是仿照Keras自带的loss进行改写。

最近评论