






19
Dec
让炼丹更科学一些(一):SGD的平均损失收敛
By 苏剑林 | 2023-12-19 | 33307位读者 | 引用很多时候我们将深度学习模型的训练过程戏称为“炼丹”,因为整个过程跟古代的炼丹术一样,看上去有一定的科学依据,但整体却给人一种“玄之又玄”的感觉。尽管本站之前也关注过一些优化器相关的工作,甚至也写过《从动力学角度看优化算法》系列,但都是比较表面的介绍,并没有涉及到更深入的理论。为了让以后的炼丹更科学一些,笔者决定去补习一些优化相关的理论结果,争取让炼丹之路多点理论支撑。
在本文中,我们将学习随机梯度下降(SGD)的一个非常基础的收敛结论。虽然现在看来,该结论显得很粗糙且不实用,但它是优化器收敛性证明的一次非常重要的尝试,特别是它考虑了我们实际使用的是随机梯度下降(SGD)而不是全量梯度下降(GD)这一特性,使得结论更加具有参考意义。
问题设置
设损失函数是$L(\boldsymbol{x},\boldsymbol{\theta})$,其实$\boldsymbol{x}$是训练集,而$\boldsymbol{\theta}\in\mathbb{R}^d$是训练参数。受限于算力,我们通常只能执行随机梯度下降(SGD),即每步只能采样一个训练子集来计算损失函数并更新参数,假设采样是独立同分布的,第$t$步采样到的子集为$\boldsymbol{x}_t$,那么我们可以合理地认为实际优化的最终目标是
\begin{equation}L(\boldsymbol{\theta}) = \lim_{T\to\infty}\frac{1}{T}\sum_{t=1}^T L(\boldsymbol{x}_t,\boldsymbol{\theta})\label{eq:loss}\end{equation}
27
Feb
配置不同的学习率,LoRA还能再涨一点?
By 苏剑林 | 2024-02-27 | 38317位读者 | 引用LoRA(Low-Rank Adaptation)是当前LLM的参数高效微调手段之一,此前我们在《梯度视角下的LoRA:简介、分析、猜测及推广》也有过简单讨论。这篇文章我们来学习LoRA的一个新结论:
给LoRA的两个矩阵分配不同的学习率,LoRA的效果还能进一步提升。
该结论出自最近的论文《LoRA+: Efficient Low Rank Adaptation of Large Models》(下称“LoRA+”)。咋看之下,该结论似乎没有什么特别的,因为配置不同的学习率相当于引入了新的超参数,通常来说只要引入并精调超参数都会有提升。“LoRA+”的特别之处在于,它从理论角度肯定了这个必要性,并且断定最优解必然是右矩阵的学习率大于左矩阵的学习率。简而言之,“LoRA+”称得上是理论指导训练并且在实践中确实有效的经典例子,值得仔细学习一番。
结论简析
假设预训练参数为$W_0 \in \mathbb{R}^{n\times m}$,如果使用全量参数微调,那么增量也是一个$n\times m$矩阵。为了降低参数量,LoRA将更新量约束为低秩矩阵,即设$W=W_0 + AB$,其中$A\in\mathbb{R}^{n\times r},B\in\mathbb{R}^{r\times m}$以及有$r\ll \min(n,m)$,用新的$W$替换模型原有参数,然后固定$W_0$不变,训练的时候只更新$A,B$,如下图所示:
$$\style{display: inline-block; width: 24ex; padding: 10ex 0; border: 1px solid #6C8EBF; background-color: #DAE8FC}{W_0\in\mathbb{R}^{n\times m}} \quad + \quad \style{display: inline-block; width: 8ex; padding: 10ex 0; border: 1px solid #D79B00; background-color: #FFE6CC}{A\in\mathbb{R}^{n\times r}}\quad\times\quad \style{display: inline-block; width: 24ex; padding: 3ex 0; border: 1px solid #D79B00; background-color: #FFE6CC}{B\in\mathbb{R}^{r\times m}}$$
24
May
重温SSM(一):线性系统和HiPPO矩阵
By 苏剑林 | 2024-05-24 | 28659位读者 | 引用前几天,笔者看了几篇介绍SSM(State Space Model)的文章,才发现原来自己从未认真了解过SSM,于是打算认真去学习一下SSM的相关内容,顺便开了这个新坑,记录一下学习所得。
SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的S4,不算太老,而SSM最新最火的变体大概是去年的Mamba。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样RWKV、RetNet还有此前我们在《Google新作试图“复活”RNN:RNN能否再次辉煌?》介绍过的LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。
尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作《HiPPO: Recurrent Memory with Optimal Polynomial Projections》(简称HiPPO),所以本文从HiPPO开始说起。
29
May
Transformer升级之路:18、RoPE的底数选择原则
By 苏剑林 | 2024-05-29 | 136449位读者 | 引用我们知道,在RoPE中频率的计算公式为$\theta_i = b^{-2i/d}$,底数$b$默认值为10000。目前Long Context的主流做法之一是,先在$b=10000$上用短文本预训练,然后调大$b$并在长文本微调,其出发点是《Transformer升级之路:10、RoPE是一种β进制编码》里介绍的NTK-RoPE,它本身有较好长度外推性,换用更大的$b$再微调相比不加改动的微调,起始损失更小,收敛也更快。该过程给人的感觉是:调大$b$完全是因为“先短后长”的训练策略,如果一直都用长文本训练似乎就没必要调大$b$了?
上周的论文《Base of RoPE Bounds Context Length》试图回答这个问题,它基于一个期望性质研究了$b$的下界,由此指出更大的训练长度本身就应该选择更大的底数,与训练策略无关。整个分析思路颇有启发性,接下来我们一起来品鉴一番。
12
Jul
对齐全量微调!这是我看过最精彩的LoRA改进(一)
By 苏剑林 | 2024-07-12 | 30904位读者 | 引用众所周知,LoRA是一种常见的参数高效的微调方法,我们在《梯度视角下的LoRA:简介、分析、猜测及推广》做过简单介绍。LoRA利用低秩分解来降低微调参数量,节省微调显存,同时训练好的权重可以合并到原始权重上,推理架构不需要作出改变,是一种训练和推理都比较友好的微调方案。此外,我们在《配置不同的学习率,LoRA还能再涨一点?》还讨论过LoRA的不对称性,指出给$A,B$设置不同的学习率能取得更好的效果,该结论被称为“LoRA+”。
为了进一步提升效果,研究人员还提出了不少其他LoRA变体,如AdaLoRA、rsLoRA、DoRA、PiSSA等,这些改动都有一定道理,但没有特别让人深刻的地方觉。然而,前两天的《LoRA-GA: Low-Rank Adaptation with Gradient Approximation》,却让笔者眼前一亮,仅扫了摘要就有种必然有效的感觉,仔细阅读后更觉得它是至今最精彩的LoRA改进。
究竟怎么个精彩法?LoRA-GA的实际含金量如何?我们一起来学习一下。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 14651位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
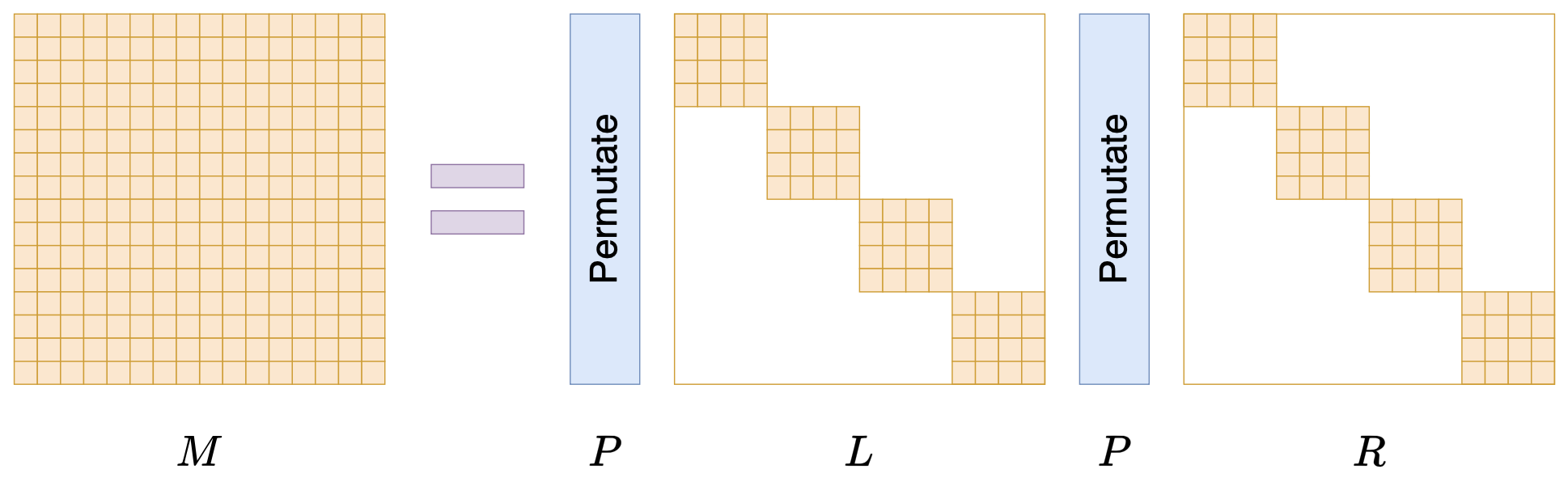
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
29
Jul
对齐全量微调!这是我看过最精彩的LoRA改进(二)
By 苏剑林 | 2024-07-29 | 14848位读者 | 引用前两周笔者写了《对齐全量微调!这是我看过最精彩的LoRA(一)》(当时还没有编号“一”),里边介绍了一个名为“LoRA-GA”的LoRA变体,它通过梯度SVD来改进LoRA的初始化,从而实现LoRA与全量微调的对齐。当然,从理论上来讲,这样做也只能尽量对齐第一步更新后的$W_1$,所以当时就有读者提出了“后面的$W_2,W_3,\cdots$不管了吗?”的疑问,当时笔者也没想太深入,就单纯觉得对齐了第一步后,后面的优化也会严格一条较优的轨迹走。
有趣的是,LoRA-GA才出来没多久,arXiv上就新出了《LoRA-Pro: Are Low-Rank Adapters Properly Optimized?》,其所提的LoRA-Pro正好能回答这个问题!LoRA-Pro同样是想着对齐全量微调,但它对齐的是每一步梯度,从而对齐整条优化轨迹,这正好是跟LoRA-GA互补的改进点。
对齐全量
本文接着上一篇文章的记号和内容进行讲述,所以这里仅对上一节的内容做一个简单回顾,不再详细重复介绍。LoRA的参数化方式是
\begin{equation}W = (W_0 - A_0 B_0) + AB\end{equation}
19
Sep
Softmax后传:寻找Top-K的光滑近似
By 苏剑林 | 2024-09-19 | 1937位读者 | 引用Softmax,顾名思义是“soft的max”,是$\max$算子(准确来说是$\text{argmax}$)的光滑近似,它通过指数归一化将任意向量$\boldsymbol{x}\in\mathbb{R}^n$转化为分量非负且和为1的新向量,并允许我们通过温度参数来调节它与$\text{argmax}$(的one hot形式)的近似程度。除了指数归一化外,我们此前在《通向概率分布之路:盘点Softmax及其替代品》也介绍过其他一些能实现相同效果的方案。
我们知道,最大值通常又称Top-1,它的光滑近似方案看起来已经相当成熟,那读者有没有思考过,一般的Top-$k$的光滑近似又是怎么样的呢?下面让我们一起来探讨一下这个问题。
问题描述
设向量$\boldsymbol{x}=(x_1,x_2,\cdots,x_n)\in\mathbb{R}^n$,简单起见我们假设它们两两不相等,即$i\neq j \Leftrightarrow x_i\neq x_j$。记$\Omega_k(\boldsymbol{x})$为$\boldsymbol{x}$最大的$k$个分量的下标集合,即$|\Omega_k(\boldsymbol{x})|=k$以及$\forall i\in \Omega_k(\boldsymbol{x}), j \not\in \Omega_k(\boldsymbol{x})\Rightarrow x_i > x_j$。我们定义Top-$k$算子$\mathcal{T}_k$为$\mathbb{R}^n\mapsto\{0,1\}^n$的映射:
\begin{equation}
[\mathcal{T}_k(\boldsymbol{x})]_i = \left\{\begin{aligned}1,\,\, i\in \Omega_k(\boldsymbol{x}) \\ 0,\,\, i \not\in \Omega_k(\boldsymbol{x})\end{aligned}\right.
\end{equation}
说白了,如果$x_i$属于最大的$k$个元素之一,那么对应的位置变成1,否则变成0,最终结果是一个Multi-Hot向量,比如$\mathcal{T}_2([3,2,1,4]) = [1,0,0,1]$。

最近评论