






24
Oct
从费马大定理谈起(十一):有理点与切割线法
By 苏剑林 | 2014-10-24 | 26955位读者 | 引用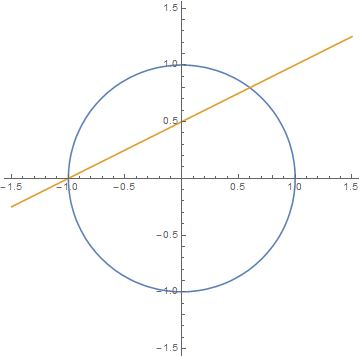
圆上的有理点
我们在这个系列的文章之中,探索了一些有关环和域的基本知识,并用整环以及唯一分解性定理证明了费马大定理在n=3和n=4时的情形。使用高斯整数环或者艾森斯坦整数环的相关知识,相对而言是属于近代的比较“高端”的代数内容(高斯生于1777年,艾森斯坦生于1823年,然而艾森斯坦英年早逝,只活到了1852年,高斯还活到了1855年。)。如果“顺利”的话,我们可以用这些“高端”的工具证明解的不存在性,或者求出通解(如果有解的话)。
然而,对于初等数论来讲,复数环和域的知识的门槛还是有点高了。其次,环和域是一个比较“强”的工具。这里的“强”有点“强势”的意味,是指这样的意思:如果它成功的话,它能够“一举破城”,把通解都求出来(或者证明解的不存在);如果它不成功的话,那么往往就连一点非平凡的解都求不出来。可是,有些问题是求出一部分解都已经很困难了,更不用说求出通解了(我们以后在研究$x^4+y^4 = z^4 + w^4 $的整数解的时候,就能深刻体会这点。)。因此,对于这些问题,单纯用环域的思想,很难给予我们(至少一部分)解。(当然,问题是如何才算是“单纯”,这也很难界定。这里的评论是比较粗糙的。)
28
Oct
在Python中使用GMP(gmpy2)
By 苏剑林 | 2014-10-28 | 68018位读者 | 引用之前笔者曾写过《初试在Python中使用PARI/GP》,简单介绍了一下在Python中调用PARI/GP的方法。PARI/GP是一个比较强大的数论库,“针对数论中的快速计算(大数分解,代数数论,椭圆曲线...)而设计”,它既可以被C/C++或Python之类的编程语言调用,而且它本身又是一种自成一体的脚本语言。而如果仅仅需要高精度的大数运算功能,那么GMP似乎更满足我们的需求。
了解C/C++的读者都会知道GMP(全称是GNU Multiple Precision Arithmetic Library,即GNU高精度算术运算库),它是一个开源的高精度运算库,其中不但有普通的整数、实数、浮点数的高精度运算,还有随机数生成,尤其是提供了非常完备的数论中的运算接口,比如Miller-Rabin素数测试算法、大素数生成、欧几里德算法、求域中元素的逆、Jacobi符号、legendre符号等[来源]。虽然在C/C++中调用GMP并不算复杂,但是如果能在以高开发效率著称的Python中使用GMP,那么无疑是一件快事。这正是本文要说的gmpy2。
思维导图
这学期的数学建模课,对笔者来说,基本上就是一个锻炼论文写作和Python技能的过程。不过是写论文还是写博客,我都致力于写出符合自己审美观的作品,因此我才会选择$\LaTeX$,我才会选择Python。$\LaTeX$写出来的科学论文是公认的标准而好看的格式,而Python,的确可以作出漂亮的图,也可以简洁地完成所需要的数值计算。我越来越发现,在数学建模、写作方面,除了必不可少的符号推导部分(这部分只能用Mathematica),我已经离不开Python了。
为什么还要求漂亮?内容好不就行了吗?的确,内容才是主要的,但是如果能把展示效果美化一下,而且又不耗费更多的功夫,那么何乐而不为呢?
20
Jan
有限素域上的乘法群是循环群
By 苏剑林 | 2015-01-20 | 82478位读者 | 引用对于任意的素数$p$,集合$\mathbb{Z}_p=\{0,1,2,\dots,p-1\}$在模$p$的加法和乘法之下,构成一个域,这是学过抽象代数或者初等数论的读者都会知道的一个事实。其中,根据域的定义,$\mathbb{Z}_p$首先要在模$p$的加法下成为一个交换群,而且由于$\mathbb{Z}_p$的特殊性,它还是一个循环群,这也是比较平凡的事实。但是,考虑乘法呢?
首先,$0$是没有逆元的,我们考虑乘法,是在$\mathbb{Z}^\cdot _p=\mathbb{Z}_p \verb|\| \{0\}=\{1,2,\dots,p-1\}$上考虑的。如果我说,$\mathbb{Z}^\cdot _p$在模$p$之下的乘法也作成一个循环群,这结论就不是很平凡的了!然而这确实是事实,对于所有的素数$p$均成立。而有了这事实,数论中的一些结论就会相当显然了,比如当$d\mid (p-1)$时,$\mathbb{Z}_p$中的$d$次剩余就只有$\frac{p-1}{d}$个了,这是循环群的基本结论。
在《数学天书中的证明》一书中,有该结论的一个证明,但这个证明是存在性的,而我在另外一本书上也看到过类似的存在性证明,也就是说,似乎流行的证明都是存在性的,它告诉我们$\mathbb{Z}^\cdot _p$是一个循环群,但是没告诉我们怎么找到它的生成元。而事实上,高斯在他的《算术探索》中就给出了一个构造性的证明。(在数论中,本文的结论是“原根”那一章的基本知识。)下面笔者正是要重复高斯的证明,供读者参考。
6
May
记录一次爬取淘宝/天猫评论数据的过程
By 苏剑林 | 2015-05-06 | 171416位读者 | 引用笔者最近迷上了数据挖掘和机器学习,要做数据分析首先得有数据才行。对于我等平民来说,最廉价的获取数据的方法,应该是用爬虫在网络上爬取数据了。本文记录一下笔者爬取天猫某商品的全过程,淘宝上面的店铺也是类似的做法,不赘述。主要是分析页面以及用Python实现简单方便的抓取。
笔者使用的工具如下
Python 3——极其方便的编程语言。选择3.x的版本是因为3.x对中文处理更加友好。
Pandas——Python的一个附加库,用于数据整理。
IE 11——分析页面请求过程(其他类似的流量监控工具亦可)。
剩下的还有requests,re,这些都是Python自带的库。
实例页面(美的某热水器):http://detail.tmall.com/item.htm?id=41464129793
7
Feb
年三十折腾极路由之SSH反向代理
By 苏剑林 | 2016-02-07 | 61760位读者 | 引用
猴年快乐!
今天是年三十了,这里简单祝大家除夕快乐,新年快乐!愿大家在新的一年里都晋升为学神。^_^
这两天主要在折腾家里的路由器。平时家里只有爸妈两人,所以为了节省,家里只是通过中继隔壁家的网络来上网。本来家里用小米路由器mini,可是小米mini中继模式下功能限制非常多,我又不想刷第三方固件(因为这样会失去app控制功能,不是很方便),所以干脆换了个极路由3。极路由在中继模式下仍然保留了大部分功能(我觉得这样才是正常的,我不理解小米mini在中继之后就没了那么多功能究竟是什么逻辑)。
作为折腾派,一个新路由到手,总有很多东西要配置,极路由本身是基于openwrt的,因此可玩性也很强。首先要完成中继,然后上网,这个很简单就不多说了。其次是获得ssh权限,在极路由那里叫做“申请开发者模式”,或者叫root(感觉极路由想做路由界的苹果,但是在如今这个时代,苹果当初那种发展模式估计很难发展起来了),这个步骤也不难,不过申请之后就会失去极路由的保修资格(不理解这是什么逻辑)。
本文主要介绍了怎么在openwrt(极路由)上安装python,以及建立SSH反向代理(实现内网穿透)。
18
Aug
【中文分词系列】 2. 基于切分的新词发现
By 苏剑林 | 2016-08-18 | 124968位读者 | 引用上一篇文章讲的是基于词典和AC自动机的快速分词。基于词典的分词有一个明显的优点,就是便于维护,容易适应领域。如果迁移到新的领域,那么只需要添加对应的领域新词,就可以实现较好地分词。当然,好的、适应领域的词典是否容易获得,这还得具体情况具体分析。本文要讨论的就是新词发现这一部分的内容。
这部分内容在去年的文章《新词发现的信息熵方法与实现》已经讨论过了,算法是来源于matrix67的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》。在那篇文章中,主要利用了三个指标——频数、凝固度(取对数之后就是我们所说的互信息熵)、自由度(边界熵)——来判断一个片段是否成词。如果真的动手去实现过这个算法的话,那么会发现有一系列的难度。首先,为了得到$n$字词,就需要找出$1\sim n$字的切片,然后分别做计算,这对于$n$比较大时,是件痛苦的时间;其次,最最痛苦的事情是边界熵的计算,边界熵要对每一个片段就行分组统计,然后再计算,这个工作量的很大的。本文提供了一种方案,可以使得新词发现的计算量大大降低。
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 135440位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}

最近评论