






1
Jun
泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
By 苏剑林 | 2020-06-01 | 92498位读者 | 引用提高模型的泛化性能是机器学习致力追求的目标之一。常见的提高泛化性的方法主要有两种:第一种是添加噪声,比如往输入添加高斯噪声、中间层增加Dropout以及进来比较热门的对抗训练等,对图像进行随机平移缩放等数据扩增手段某种意义上也属于此列;第二种是往loss里边添加正则项,比如$L_1, L_2$惩罚、梯度惩罚等。本文试图探索几种常见的提高泛化性能的手段的关联。
随机噪声
我们记模型为$f(x)$,$\mathcal{D}$为训练数据集合,$l(f(x), y)$为单个样本的loss,那么我们的优化目标是
\begin{equation}\mathop{\text{argmin}}_{\theta} L(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}}[l(f(x), y)]\end{equation}
$\theta$是$f(x)$里边的可训练参数。假如往模型输入添加噪声$\varepsilon$,其分布为$q(\varepsilon)$,那么优化目标就变为
\begin{equation}\mathop{\text{argmin}}_{\theta} L_{\varepsilon}(\theta)=\mathbb{E}_{(x,y)\sim \mathcal{D}, \varepsilon\sim q(\varepsilon)}[l(f(x + \varepsilon), y)]\end{equation}
当然,可以添加噪声的地方不仅仅是输入,也可以是中间层,也可以是权重$\theta$,甚至可以是输出$y$(等价于标签平滑),噪声也不一定是加上去的,比如Dropout是乘上去的。对于加性噪声来说,$q(\varepsilon)$的常见选择是均值为0、方差固定的高斯分布;而对于乘性噪声来说,常见选择是均匀分布$U([0,1])$或者是伯努利分布。
添加随机噪声的目的很直观,就是希望模型能学会抵御一些随机扰动,从而降低对输入或者参数的敏感性,而降低了这种敏感性,通常意味着所得到的模型不再那么依赖训练集,所以有助于提高模型泛化性能。
16
Jun
如何应对Seq2Seq中的“根本停不下来”问题?
By 苏剑林 | 2020-06-16 | 56472位读者 | 引用在Seq2Seq的解码过程中,我们是逐个token地递归生成的,直到出现<eos>标记为止,这就是所谓的“自回归”生成模型。然而,研究过Seq2Seq的读者应该都能发现,这种自回归的解码偶尔会出现“根本停不下来”的现象,主要是某个片段反复出现,比如“今天天气不错不错不错不错不错...”、“你觉得我说得对不对不对不对不对不对...”等等,但就是死活不出现<eos>标记。ICML 2020的文章《Consistency of a Recurrent Language Model With Respect to Incomplete Decoding》比较系统地讨论了这个现象,并提出了一些对策,本文来简单介绍一下论文的主要内容。
解码算法
对于自回归模型来说,我们建立的是如下的条件语言模型
\begin{equation}p(y_t|y_{\lt t}, x)\label{eq:p}\end{equation}
那么解码算法就是在已知上述模型时,给定$x$来输出对应的$y=(y_1,y_2,\dots,y_T)$来。解码算法大致可以分为两类:确定性解码算法和随机性解码算法,原论文分别针对这两类解码讨论来讨论了“根本停不下来”问题,所以我们需要来了解一下这两类解码算法。
10
Jul
强大的NVAE:以后再也不能说VAE生成的图像模糊了
By 苏剑林 | 2020-07-10 | 98712位读者 | 引用昨天早上,笔者在日常刷arixv的时候,然后被一篇新出来的论文震惊了!论文名字叫做《NVAE: A Deep Hierarchical Variational Autoencoder》,顾名思义是做VAE的改进工作的,提出了一个叫NVAE的新模型。说实话,笔者点进去的时候是不抱什么希望的,因为笔者也算是对VAE有一定的了解,觉得VAE在生成模型方面的能力终究是有限的。结果,论文打开了,呈现出来的画风是这样的:

NVAE的人脸生成效果
然后笔者的第一感觉是这样的:
W!T!F! 这真的是VAE生成的效果?这还是我认识的VAE么?看来我对VAE的认识还是太肤浅了啊,以后再也不能说VAE生成的图像模糊了...
31
Jul
我们真的需要把训练集的损失降低到零吗?
By 苏剑林 | 2020-07-31 | 62832位读者 | 引用在训练模型的时候,我们需要损失函数一直训练到0吗?显然不用。一般来说,我们是用训练集来训练模型,但希望的是验证集的损失越小越好,而正常来说训练集的损失降低到一定值后,验证集的损失就会开始上升,因此没必要把训练集的损失降低到0。
既然如此,在已经达到了某个阈值之后,我们可不可以做点别的事情来提升模型性能呢?ICML 2020的论文《Do We Need Zero Training Loss After Achieving Zero Training Error?》回答了这个问题。不过论文的回答也仅局限在“是什么”这个层面上,并没很好地描述“为什么”,另外看了知乎上kid丶大佬的解读,也没找到自己想要的答案。因此自己分析了一下,记录在此。
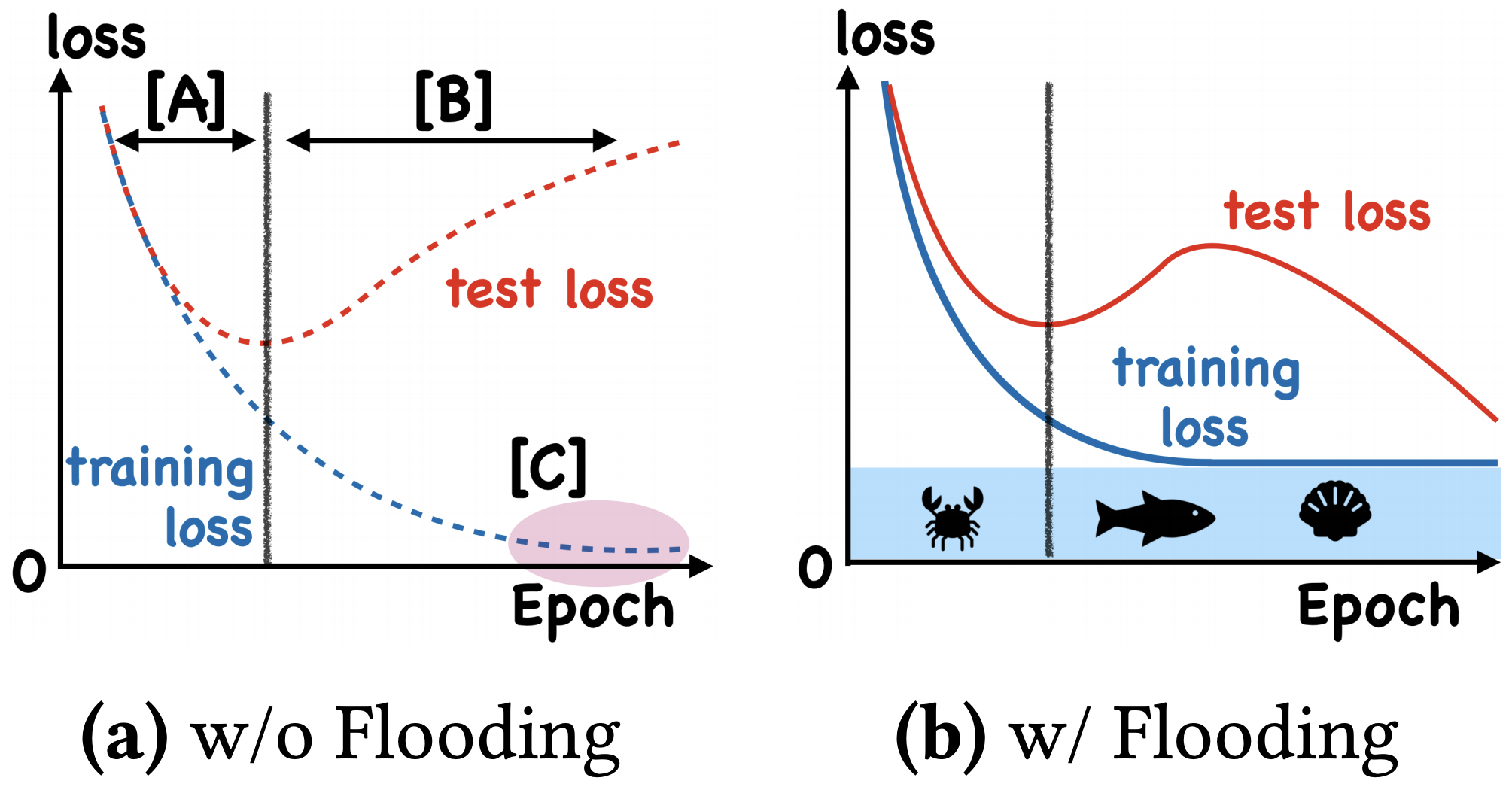
左图:不加Flooding的训练示意图;右图:加了Flooding的训练示意图
14
Aug
L2正则没有想象那么好?可能是“权重尺度偏移”惹的祸
By 苏剑林 | 2020-08-14 | 32899位读者 | 引用L2正则是机器学习常用的一种防止过拟合的方法(应该也是一道经常遇到的面试题)。简单来说,它就是希望权重的模长尽可能小一点,从而能抵御的扰动多一点,最终提高模型的泛化性能。但是读者可能也会发现,L2正则的表现通常没有理论上说的那么好,很多时候加了可能还有负作用。最近的一篇文章《Improve Generalization and Robustness of Neural Networks via Weight Scale Shifting Invariant Regularizations》从“权重尺度偏移”这个角度分析了L2正则的弊端,并提出了新的WEISSI正则项。整个分析过程颇有意思,在这里与大家分享一下。
相关内容
这一节中我们先简单回顾一下L2正则,然后介绍它与权重衰减的联系以及与之相关的AdamW优化器。
L2正则的理解
为什么要添加L2正则?这个问题可能有多个答案。有从Ridge回归角度回答的,有从贝叶斯推断角度回答的,这里给出从扰动敏感性的角度的理解。
20
Aug
最小熵原理(六):词向量的维度应该怎么选择?
By 苏剑林 | 2020-08-20 | 93072位读者 | 引用随着NLP的发展,像Word2Vec、Glove这样的词向量模型,正逐渐地被基于Transformer的BERT等模型代替,不过经典始终是经典,词向量模型依然在不少场景发光发热,并且仍有不少值得我们去研究的地方。本文我们来关心一个词向量模型可能有的疑惑:词向量的维度大概多少才够?
先说结论,笔者给出的估算结果是
\begin{equation}n > 8.33\log N\label{eq:final}\end{equation}
更简约的话可以直接记$n > 8\log N$,其中$N$是词表大小,$n$就是词向量维度,$\log$是自然对数。当$n$超过这个阈值时,就说明模型有足够的容量容纳这$N$个词语(当然$n$越大过拟合风险也越大)。这样一来,当$N=100000$时,得到的$n$大约是96,所以对于10万个词的词向量模型来说,维度选择96就足够了;如果要容纳500万个词,那么$n$大概就是128。
31
Aug
再谈类别不平衡问题:调节权重与魔改Loss的对比联系
By 苏剑林 | 2020-08-31 | 69560位读者 | 引用类别不平衡问题,也称为长尾分布问题,在本博客里已经有好几次相关讨论了,比如《从loss的硬截断、软化到focal loss》、《将“Softmax+交叉熵”推广到多标签分类问题》、《通过互信息思想来缓解类别不平衡问题》。对于缓解类别不平衡,比较基本的方法就是调节样本权重,看起来“高端”一点的方法则是各种魔改loss了(比如Focal Loss、Dice Loss、Logits Adjustment等),本文希望比较系统地理解一下它们之间的联系。
长尾分布:少数类别的样本数目非常多,多数类别的样本数目非常少。
从光滑准确率到交叉熵
这里的分析主要以sigmoid的2分类为主,但多数结论可以平行推广到softmax的多分类。设$x$为输入,$y\in\{0,1\}$为目标,$p_{\theta}(x) \in [0, 1]$为模型。理想情况下,当然是要评测什么指标,我们就去优化那个指标。对于分类问题来说,最朴素的指标当然就是准确率,但准确率并没有办法提供有效的梯度,所以不能直接来训练。
15
Sep
殊途同归的策略梯度与零阶优化
By 苏剑林 | 2020-09-15 | 51482位读者 | 引用深度学习如此成功的一个巨大原因就是基于梯度的优化算法(SGD、Adam等)能有效地求解大多数神经网络模型。然而,既然是基于梯度,那么就要求模型是可导的,但随着研究的深入,我们时常会有求解不可导模型的需求,典型的例子就是直接优化准确率、F1、BLEU等评测指标,或者在神经网络里边加入了不可导模块(比如“跳读”操作)。

Gradient
本文将简单介绍两种求解不可导的模型的有效方法:强化学习的重要方法之一策略梯度(Policy Gradient),以及干脆不需要梯度的零阶优化(Zeroth Order Optimization)。表面上来看,这是两种思路完全不一样的优化方法,但本文将进一步证明,在一大类优化问题中,其实两者基本上是等价的。

最近评论