






7
Jan
【搜出来的文本】⋅(一)从文本生成到搜索采样
By 苏剑林 | 2021-01-07 | 60254位读者 | 引用最近,笔者入了一个新坑:基于离散优化的思想做一些文本生成任务。简单来说,就是把我们要生成文本的目标量化地写下来,构建一个分布,然后搜索这个分布的最大值点或者从这个分布中进行采样,这个过程通常不需要标签数据的训练。由于语言是离散的,因此梯度下降之类的连续函数优化方法不可用,并且由于这个分布通常没有容易采样的形式,直接采样也不可行,因此需要一些特别设计的采样算法,比如拒绝采样(Rejection Sampling)、MCMC(Markov Chain Monte Carlo)、MH采样(Metropolis-Hastings Sampling)、吉布斯采样(Gibbs Sampling),等等。
有些读者可能会觉得有些眼熟,似乎回到了让人头大的学习LDA(Latent Dirichlet Allocation)的那些年?没错,上述采样算法其实也是理解LDA模型的必备基础。本文我们就来回顾这些形形色色的采样算法,它们将会出现在后面要介绍的丰富的文本生成应用中。
3
Feb
让研究人员绞尽脑汁的Transformer位置编码
By 苏剑林 | 2021-02-03 | 189595位读者 | 引用不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择:1、想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法;2、想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。
虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。
绝对位置编码
形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第$k$个向量$\boldsymbol{x}_k$中加入位置向量$\boldsymbol{p}_k$变为$\boldsymbol{x}_k + \boldsymbol{p}_k$,其中$\boldsymbol{p}_k$只依赖于位置编号$k$。
23
Mar
Transformer升级之路:2、博采众长的旋转式位置编码
By 苏剑林 | 2021-03-23 | 276488位读者 | 引用上一篇文章中,我们对原始的Sinusoidal位置编码做了较为详细的推导和理解,总的感觉是Sinusoidal位置编码是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。
本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。
22
Jul
概率视角下的线性模型:逻辑回归有解析解吗?
By 苏剑林 | 2021-07-22 | 74537位读者 | 引用我们知道,线性回归是比较简单的问题,它存在解析解,而它的变体逻辑回归(Logistic Regression)却没有解析解,这不能不说是一个遗憾。因为逻辑回归虽然也叫“回归”,但它实际上是用于分类问题的,而对于很多读者来说分类比回归更加常见。准确来说,我们说逻辑回归没有解析解,说的是“最大似然估计下逻辑回归没有解析解”。那么,这是否意味着,如果我们不用最大似然估计,是否能找到一个可用的解析解呢?
逻辑回归示意图
本文将会从非最大似然的角度,推导逻辑回归的一个解析解,简单的实验表明它效果不逊色于梯度下降求出来的最大似然解。此外,这个解析解还易于推广到单层Softmax多分类模型。
6
Jan
CoSENT(一):比Sentence-BERT更有效的句向量方案
By 苏剑林 | 2022-01-06 | 215497位读者 | 引用学习句向量的方案大致上可以分为无监督和有监督两大类,其中有监督句向量比较主流的方案是Facebook提出的“InferSent”,而后的“Sentence-BERT”进一步在BERT上肯定了它的有效性。然而,不管是InferSent还是Sentence-BERT,它们在理论上依然相当令人迷惑,因为它们虽然有效,但存在训练和预测不一致的问题,而如果直接优化预测目标cos值,效果往往特别差。
最近,笔者再次思考了这个问题,经过近一周的分析和实验,大致上确定了InferSent有效以及直接优化cos值无效的原因,并提出了一个优化cos值的新方案CoSENT(Cosine Sentence)。实验显示,CoSENT在收敛速度和最终效果上普遍都比InferSent和Sentence-BERT要好。
朴素思路
本文的场景是利用文本匹配的标注数据来构建句向量模型,其中所利用到的标注数据是常见的句子对样本,即每条样本是“(句子1, 句子2, 标签)”的格式,它们又大致上可以分类“是非类型”、“NLI类型”、“打分类型”三种,参考《用开源的人工标注数据来增强RoFormer-Sim》中的“分门别类”一节。
失效的Cos
简单起见,我们可以先只考虑“是非类型”的数据,即“(句子1, 句子2, 是否相似)”的样本。假设两个句子经过编码模型后分别得到向量$u,v$,由于检索阶段计算的是余弦相似度$\cos(u,v)=\frac{\langle u,v\rangle}{\Vert u\Vert \Vert v\Vert}$,所以比较自然的想法是设计基于$\cos(u,v)$的损失函数,比如
\begin{align}t\cdot (1 - \cos(u, v)) + (1 - t) \cdot (1 + \cos(u,v))\label{eq:cos-1}\\
t\cdot (1 - \cos(u, v))^2 + (1 - t) \cdot \cos^2(u,v)\label{eq:cos-2}
\end{align}
18
Jan
多任务学习漫谈(一):以损失之名
By 苏剑林 | 2022-01-18 | 147013位读者 | 引用能提升模型性能的方法有很多,多任务学习(Multi-Task Learning)也是其中一种。简单来说,多任务学习是希望将多个相关的任务共同训练,希望不同任务之间能够相互补充和促进,从而获得单任务上更好的效果(准确率、鲁棒性等)。然而,多任务学习并不是所有任务堆起来就能生效那么简单,如何平衡每个任务的训练,使得各个任务都尽量获得有益的提升,依然是值得研究的课题。
最近,笔者机缘巧合之下,也进行了一些多任务学习的尝试,借机也学习了相关内容,在此挑部分结果与大家交流和讨论。
加权求和
从损失函数的层面看,多任务学习就是有多个损失函数$\mathcal{L}_1,\mathcal{L}_2,\cdots,\mathcal{L}_n$,一般情况下它们有大量的共享参数、少量的独立参数,而我们的目标是让每个损失函数都尽可能地小。为此,我们引入权重$\alpha_1,\alpha_2,\cdots,\alpha_n\geq 0$,通过加权求和的方式将它转化为如下损失函数的单任务学习
\begin{equation}\mathcal{L} = \sum_{i=1}^n \alpha_i \mathcal{L}_i\label{eq:w-loss}\end{equation}
在这个视角下,多任务学习的主要难点就是如何确定各个$\alpha_i$了。
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 172818位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
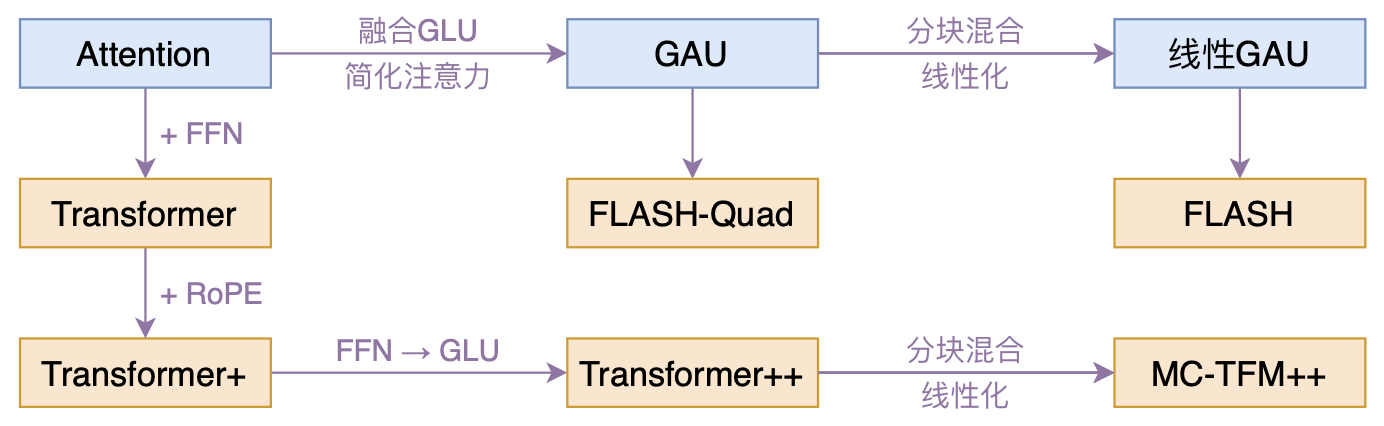
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 30445位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。

最近评论