






14
Nov
当Batch Size增大时,学习率该如何随之变化?
By 苏剑林 | 2024-11-14 | 3252位读者 | 引用随着算力的飞速进步,有越多越多的场景希望能够实现“算力换时间”,即通过堆砌算力来缩短模型训练时间。理想情况下,我们希望投入$n$倍的算力,那么达到同样效果的时间则缩短为$1/n$,此时总的算力成本是一致的。这个“希望”看上去很合理和自然,但实际上并不平凡,即便我们不考虑通信之类的瓶颈,当算力超过一定规模或者模型小于一定规模时,增加算力往往只能增大Batch Size。然而,增大Batch Size一定可以缩短训练时间并保持效果不变吗?
这就是接下来我们要讨论的话题:当Batch Size增大时,各种超参数尤其是学习率该如何调整,才能保持原本的训练效果并最大化训练效率?我们也可以称之为Batch Size与学习率之间的Scaling Law。
方差视角
直觉上,当Batch Size增大时,每个Batch的梯度将会更准,所以步子就可以迈大一点,也就是增大学习率,以求更快达到终点,缩短训练时间,这一点大体上都能想到。问题就是,增大多少才是最合适的呢?
6
Nov
VQ的又一技巧:给编码表加一个线性变换
By 苏剑林 | 2024-11-06 | 5175位读者 | 引用在《VQ的旋转技巧:梯度直通估计的一般推广》中,我们介绍了VQ(Vector Quantization)的Rotation Trick,它的思想是通过推广VQ的STE(Straight-Through Estimator)来为VQ设计更好的梯度,从而缓解VQ的编码表坍缩、编码表利用率低等问题。
无独有偶,昨天发布在arXiv上的论文《Addressing Representation Collapse in Vector Quantized Models with One Linear Layer》提出了改善VQ的另一个技巧:给编码表加一个线性变换。这个技巧单纯改变了编码表的参数化方式,不改变VQ背后的理论框架,但实测效果非常优异,称得上是简单有效的经典案例。
29
Jul
R136a1,300倍太阳质量的怪兽星
By 苏剑林 | 2010-07-29 | 27544位读者 | 引用原文链接:http://www.eso.org/public/news/eso1030/
译文来自:http://www.astronomy.com.cn/bbs/thread-141201-1-1.html
Stars Just Got Bigger 超大质量的巨星 A 300 Solar Mass Star Uncovered 发现超过300太阳质量的蓝超巨星
Using a combination of instruments on ESO’s Very Large Telescope, astronomers have discovered the most massive stars to date, one weighing at birth more than 300 times the mass of the Sun, or twice as much as the currently accepted limit of 150 solar masses. The existence of these monsters — millions of times more luminous than the Sun, losing weight through very powerful winds — may provide an answer to the question “how massive can stars be?”
借助于ESO的甚大望远镜(VLT),天文学家发现了创质量纪录的巨星——达300个太阳质量以上,是我们此前公认的(星族II)恒星质量上限——150个太阳的2倍。发现如此怪兽级恒星:光度是太阳的数百万倍,以极速恒星风迅速损失质量——由此产生了一个问题:恒星质量上限到底是多少?
23
Oct
科学空间:2010年11月重要天象
By 苏剑林 | 2010-10-23 | 21373位读者 | 引用
最近的很多篇文章都是数论内容,属于纯数学的范畴了,对于很多只爱好物理或应用数学的读者可能会看得头晕了。今天我们来谈些不那么抽象的东西,我们来谈谈风筝,并来分析一下风筝的飞行力学。
爱情就像放风筝,线不能来得太紧,也不能拉得太松,你只会给对方飞翔的空间,他/她始终会回到你身边,因为有一条线系着双方。

放风筝(来自互联网)
风筝,在我们这个地方叫做纸鸢,相信大家童年时一定会放过。笔者小时候放风筝时,已经是小学五年级之前的事了。这个暑假突然童心一起,凭着小时候的回忆,简单做了个风筝来玩,居然真的飞起来了!兴奋之余,与大家分享一下。如今再来放风筝,真心感觉到放风筝也有很多技巧,让风筝飞,还不是件容易的事情呢,真可谓人生处处皆学问呀。上面关于风筝的比喻,正是放风筝的真实写照吧。
风筝可以说是人类摆脱地球重力的最原始尝试吧,跟发射宇宙飞船的火箭不同,风筝是借助风力来抵抗重力,严格来讲,即便是现在的飞机,也离不开这个原理(我们最后会谈到)。简单来讲,风筝就是用轻的支架撑开一个轻盈的平面,然后系上一个线圈。我们简单做一个风筝,只需要一张报纸,两条竹篾和一点透明胶,十分钟内就可以完成一个。当然,现在已经有各种各样的好看的风筝,甚至还有龙形的风筝,但是,自己动手简单做一个风筝,还是相当好玩的。
风筝自然是借助风力飞起来的,可是为什么风筝得用绳子牵着才能飞得更高、绳断了反而掉下来?风大多时,才适合放风筝?飞机又是怎么飞起来的?下面我们试着分析这些问题。
18
Jun
OCR技术浅探:3. 特征提取(1)
By 苏剑林 | 2016-06-18 | 55269位读者 | 引用作为OCR系统的第一步,特征提取是希望找出图像中候选的文字区域特征,以便我们在第二步进行文字定位和第三步进行识别. 在这部分内容中,我们集中精力模仿肉眼对图像与汉字的处理过程,在图像的处理和汉字的定位方面走了一条创新的道路. 这部分工作是整个OCR系统最核心的部分,也是我们工作中最核心的部分.
传统的文本分割思路大多数是“边缘检测 + 腐蚀膨胀 + 联通区域检测”,如论文[1]. 然而,在复杂背景的图像下进行边缘检测会导致背景部分的边缘过多(即噪音增加),同时文字部分的边缘信息则容易被忽略,从而导致效果变差. 如果在此时进行腐蚀或膨胀,那么将会使得背景区域跟文字区域粘合,效果进一步恶化.(事实上,我们在这条路上已经走得足够远了,我们甚至自己写过边缘检测函数来做这个事情,经过很多测试,最终我们决定放弃这种思路。)
因此,在本文中,我们放弃了边缘检测和腐蚀膨胀,通过聚类、分割、去噪、池化等步骤,得到了比较良好的文字部分的特征,整个流程大致如图2,这些特征甚至可以直接输入到文字识别模型中进行识别,而不用做额外的处理.由于我们每一部分结果都有相应的理论基础作为支撑,因此能够模型的可靠性得到保证.
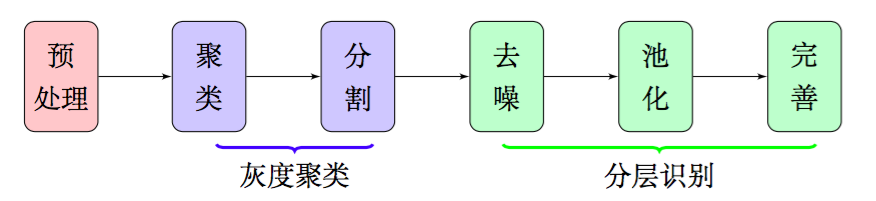
图2:特征提取大概流程
26
Jun

最近评论