






20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 66264位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
27
Jul
生成扩散模型漫谈(四):DDIM = 高观点DDPM
By 苏剑林 | 2022-07-27 | 195763位读者 | 引用相信很多读者都听说过甚至读过克莱因的《高观点下的初等数学》这套书,顾名思义,这是在学到了更深入、更完备的数学知识后,从更高的视角重新审视过往学过的初等数学,以得到更全面的认知,甚至达到温故而知新的效果。类似的书籍还有很多,比如《重温微积分》、《复分析:可视化方法》等。
回到扩散模型,目前我们已经通过三篇文章从不同视角去解读了DDPM,那么它是否也存在一个更高的理解视角,让我们能从中得到新的收获呢?当然有,《Denoising Diffusion Implicit Models》介绍的DDIM模型就是经典的案例,本文一起来欣赏它。
思路分析
在《生成扩散模型漫谈(三):DDPM = 贝叶斯 + 去噪》中,我们提到过该文章所介绍的推导跟DDIM紧密相关。具体来说,文章的推导路线可以简单归纳如下:
\begin{equation}p(\boldsymbol{x}_t|\boldsymbol{x}_{t-1})\xrightarrow{\text{推导}}p(\boldsymbol{x}_t|\boldsymbol{x}_0)\xrightarrow{\text{推导}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0)\xrightarrow{\text{近似}}p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)\end{equation}
22
Nov
基于Amos优化器思想推导出来的一些“炼丹策略”
By 苏剑林 | 2022-11-22 | 30546位读者 | 引用如果将训练模型比喻为“炼丹”,那么“炼丹炉”显然就是优化器了。据传AdamW优化器是当前训练神经网络最快的方案,这一点笔者也没有一一对比过,具体情况如何不得而知,不过目前做预训练时多数都用AdamW或其变种LAMB倒是真的。然而,正如有了炼丹炉也未必能炼出好丹,即便我们确定了选择AdamW优化器,依然有很多问题还没有确定的答案,比如:
1、学习率如何适应不同初始化和参数化?
2、权重衰减率该怎么调?
3、学习率应该用什么变化策略?
4、能不能降低优化器的显存占用?
尽管在实际应用时,我们大多数情况下都可以直接套用前人已经调好的参数和策略,但缺乏比较系统的调参指引,始终会让我们在“炼丹”之时感觉没有底气。在这篇文章中,我们基于Google最近提出的Amos优化器的思路,给出一些参考结果。
14
Sep
生成扩散模型漫谈(十):统一扩散模型(理论篇)
By 苏剑林 | 2022-09-14 | 68580位读者 | 引用老读者也许会发现,相比之前的更新频率,这篇文章可谓是“姗姗来迟”,因为这篇文章“想得太多”了。
通过前面九篇文章,我们已经对生成扩散模型做了一个相对全面的介绍。虽然理论内容很多,但我们可以发现,前面介绍的扩散模型处理的都是连续型对象,并且都是基于正态噪声来构建前向过程。而“想得太多”的本文,则希望能够构建一个能突破以上限制的扩散模型统一框架(Unified Diffusion Model,UDM):
1、不限对象类型(可以是连续型$\boldsymbol{x}$,也可以是离散型的$\boldsymbol{x}$);
2、不限前向过程(可以用加噪、模糊、遮掩、删减等各种变换构建前向过程);
3、不限时间类型(可以是离散型的$t$,也可以是连续型的$t$);
4、包含已有结果(可以推出前面的DDPM、DDIM、SDE、ODE等结果)。
这是不是太过“异想天开”了?有没有那么理想的框架?本文就来尝试一下。
21
Sep
生成扩散模型漫谈(十一):统一扩散模型(应用篇)
By 苏剑林 | 2022-09-21 | 42057位读者 | 引用在《生成扩散模型漫谈(十):统一扩散模型(理论篇)》中,笔者自称构建了一个统一的模型框架(Unified Diffusion Model,UDM),它允许更一般的扩散方式和数据类型。那么UDM框架究竟能否实现如期目的呢?本文通过一些具体例子来演示其一般性。
框架回顾
首先,UDM通过选择噪声分布$q(\boldsymbol{\varepsilon})$和变换$\boldsymbol{\mathcal{F}}$来构建前向过程
\begin{equation}\boldsymbol{x}_t = \boldsymbol{\mathcal{F}}_t(\boldsymbol{x}_0,\boldsymbol{\varepsilon}),\quad \boldsymbol{\varepsilon}\sim q(\boldsymbol{\varepsilon})\end{equation}
然后,通过如下的分解来实现反向过程$\boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t)$的采样
\begin{equation}\hat{\boldsymbol{x}}_0\sim p(\boldsymbol{x}_0|\boldsymbol{x}_t)\quad \& \quad \boldsymbol{x}_{t-1}\sim p(\boldsymbol{x}_{t-1}|\boldsymbol{x}_t, \boldsymbol{x}_0=\hat{\boldsymbol{x}}_0)\end{equation}
其中$p(\boldsymbol{x}_0|\boldsymbol{x}_t)$就是用$\boldsymbol{x}_t$预估$\boldsymbol{x}_0$的概率,一般用简单分布$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$来近似建模,训练目标基本上就是$-\log q(\boldsymbol{x}_0|\boldsymbol{x}_t)$或其简单变体。当$\boldsymbol{x}_0$是连续型数据时,$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$一般就取条件正态分布;当$\boldsymbol{x}_0$是离散型数据时,$q(\boldsymbol{x}_0|\boldsymbol{x}_t)$可以选择自回归模型或者非自回归模型。
25
Oct
圆内随机n点在同一个圆心角为θ的扇形的概率
By 苏剑林 | 2022-10-25 | 35627位读者 | 引用
4
Jan
智能家居之热水器零冷水技术原理浅析
By 苏剑林 | 2023-01-04 | 41650位读者 | 引用如果家庭使用单一的热水器集中供热水,那么当我们想要用热水时,往往需要先放一段时间的冷水,而如果放冷水时间比较长的话,就会比较影响体验。所谓零冷水,实际上就是想办法提前把热水管中的冷水排放掉,以达到(几乎)瞬间出热水的效果。事实上,零冷水并不是什么高大上的技术,但可能由于观念没跟上、理解上有误等原因,零冷水技术还没有在家庭中得到普及,不过随着大家对生活品质的要求越来越高,零冷水确实在慢慢流行起来了。
本文来简单分析一下零冷水技术的实现原理,包括各种方案的优缺点和自省DIY的参考思路。
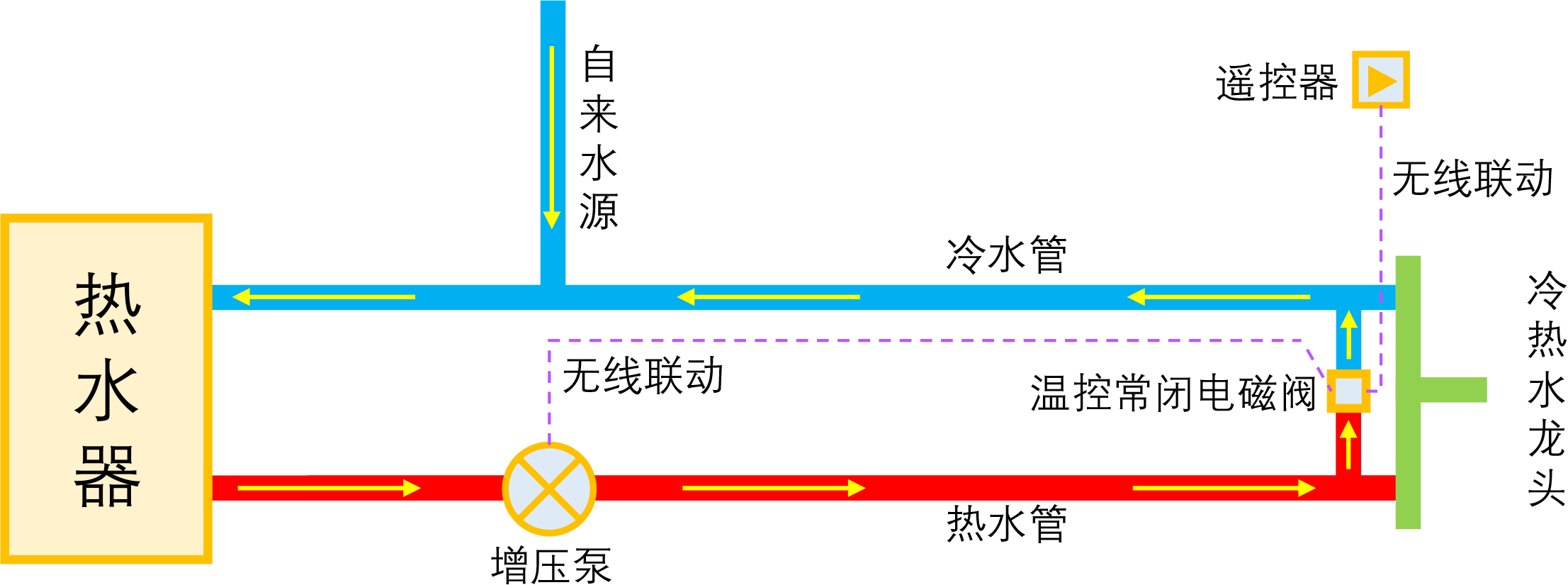
理想的零冷水方案
写在前面
在文章开始,需要纠正很多人的一个错误观念:零冷水不是为了省钱,而是为了提升生活品质。如果你是省钱最大的心态,那么接下来的内容就可以不用看了,零冷水技术对你毫无价值。
12
Jan
Transformer升级之路:7、长度外推性与局部注意力
By 苏剑林 | 2023-01-12 | 85744位读者 | 引用对于Transformer模型来说,其长度的外推性是我们一直在追求的良好性质,它是指我们在短序列上训练的模型,能否不用微调地用到长序列上并依然保持不错的效果。之所以追求长度外推性,一方面是理论的完备性,觉得这是一个理想模型应当具备的性质,另一方面也是训练的实用性,允许我们以较低成本(在较短序列上)训练出一个长序列可用的模型。
下面我们来分析一下加强Transformer长度外推性的关键思路,并由此给出一个“超强基线”方案,然后我们带着这个“超强基线”来分析一些相关的研究工作。
思维误区
第一篇明确研究Transformer长度外推性的工作应该是ALIBI,出自2021年中期,距今也不算太久。为什么这么晚(相比Transformer首次发表的2017年)才有人专门做这个课题呢?估计是因为我们长期以来,都想当然地认为Transformer的长度外推性是位置编码的问题,找到更好的位置编码就行了。

最近评论