






7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 100517位读者 | 引用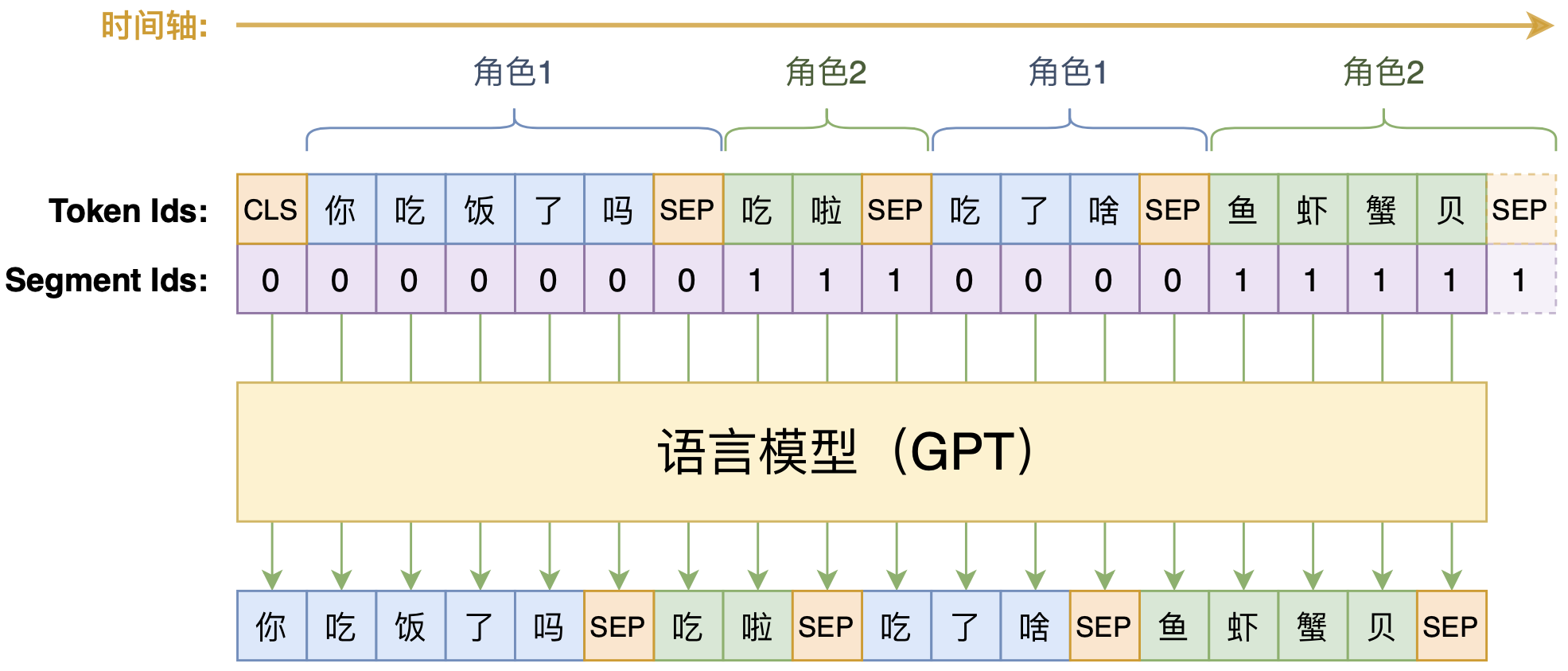
25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 110128位读者 | 引用机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
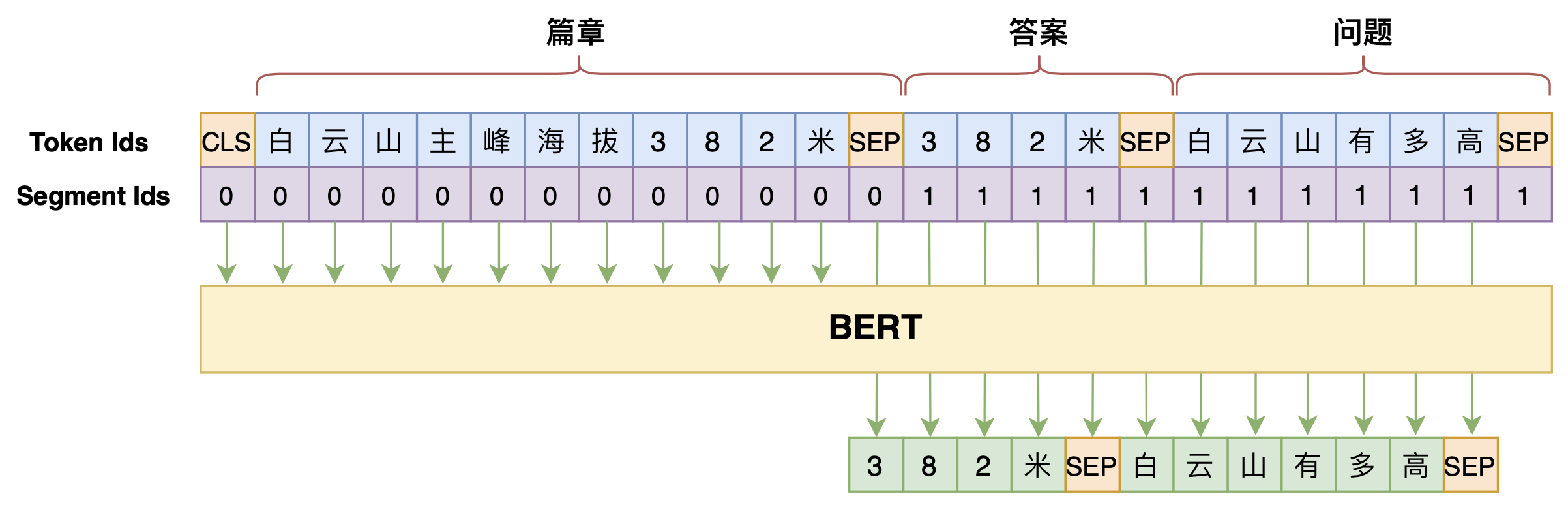
本文的问答生成模型示意图
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 66483位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。
7
Dec
【龟鱼记】全陶粒的同程底滤生态缸
By 苏剑林 | 2020-12-07 | 55199位读者 | 引用
22
Jan
【搜出来的文本】⋅(三)基于BERT的文本采样
By 苏剑林 | 2021-01-22 | 82220位读者 | 引用从这一篇开始,我们就将前面所介绍的采样算法应用到具体的文本生成例子中。而作为第一个例子,我们将介绍如何利用BERT来进行文本随机采样。所谓文本随机采样,就是从模型中随机地产生一些自然语言句子出来,通常的观点是这种随机采样是GPT2、GPT3这种单向自回归语言模型专有的功能,而像BERT这样的双向掩码语言模型(MLM)是做不到的。
事实真的如此吗?当然不是。利用BERT的MLM模型其实也可以完成文本采样,事实上它就是上一篇文章所介绍的Gibbs采样。这一事实首先由论文《BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model》明确指出。论文的标题也颇为有趣:“BERT也有嘴巴,所以它得说点什么。”现在就让我们看看BERT究竟能说出什么来~
5
Jun
从一个单位向量变换到另一个单位向量的正交矩阵
By 苏剑林 | 2021-06-05 | 41869位读者 | 引用这篇文章我们来讨论一个比较实用的线性代数问题:
给定两个$d$维单位(列)向量$\boldsymbol{a},\boldsymbol{b}$,求一个正交矩阵$\boldsymbol{T}$,使得$\boldsymbol{b}=\boldsymbol{T}\boldsymbol{a}$。
由于两个向量模长相同,所以很显然这样的正交矩阵必然存在,那么,我们怎么把它找出来呢?
二维
不难想象,这本质上就是$\boldsymbol{a},\boldsymbol{b}$构成的二维子平面下的向量变换(比如旋转或者镜面反射)问题,所以我们先考虑$d=2$的情形。

正交分解示意图
8
Sep
有限内存下全局打乱几百G文件(Python)
By 苏剑林 | 2021-09-08 | 69255位读者 | 引用这篇文章我们来做一道编程题:
如何在有限内存下全局随机打乱(Shuffle)几百G的文本文件?
题目背景其实很明朗,现在预训练模型动辄就几十甚至几百G语料了,为了让模型能更好地进行预训练,对训练语料进行一次全局的随机打乱是很有必要的。但对于很多人来说,几百G的语料往往比内存还要大,所以如何能在有限内存下做到全局的随机打乱,便是一个很值得研究的问题了。
已有工具
假设我们的文件是按行存储的,也就是一行代表一个样本,我们要做的就是按行随机打乱文件。假设我们只有一个文件,并且这个文件大小明显小于内存,那么我们可以用linux自带的shuf命令:
shuf input.txt -o output.txt
4
Dec
开局一段扯,数据全靠编?真被一篇“神论文”气到了
By 苏剑林 | 2021-12-04 | 53698位读者 | 引用这篇文章谈一下笔者被昨天出来的一篇“神论文”气到了的经历。
这篇“神论文”是《How not to Lie with a Benchmark: Rearranging NLP Leaderboards》,论文的大致内容是说目前很多排行榜算平均都用算术平均,而它认为几何平均与调和平均更加合理。最关键是它还对GLUE、SuperGLUE等榜单上的模型用几何平均和调和平均重新算了一下排名,结果发现那些超过人类的模型在新的平均方案下都没超过人类了。
看上去是不是觉得挺有意思的?我也觉得挺有意思的,所以打算写一篇博客介绍一下它。结果博客快写完了,然后在对数据的时候,发现里边表格的数据全是乱来的!!!真实的结果完全不支撑它的结论!!!所以,这篇博客就从“表扬大会”变成了“批评大会”...

最近评论