






2
May
寻求一个光滑的最大值函数
By 苏剑林 | 2015-05-02 | 129662位读者 | 引用在最优化问题中,求一个函数的最大值或最小值,最直接的方法是求导,然后比较各阶极值的大小。然而,我们所要优化的函数往往不一定可导,比如函数中含有最大值函数$\max(x,y)$的。这时候就得求助于其他思路了。有一个很巧妙的思路是,将这些不可导函数用一个可导的函数来近似它,从而我们用求极值的方法来求出它近似的最优值。本文的任务,就是探究一个简单而有用的函数,它能够作为最大值函数的近似,并且具有多阶导数。下面是笔者给出的一个推导过程。
在数学分析中,笔者已经学习过一个关于最大值函数的公式,即当$x \geq 0, y \geq 0$时,我们有
$$\max(x,y)=\frac{1}{2}\left(|x+y|+|x-y|\right)\tag{1}$$
那么,为了寻求一个最大值的函数,我们首先可以考虑寻找一个能够近似表示绝对值$|x|$的函数,这样我们就把问题从二维降低到一维了。那么,哪个函数可以使用呢?
20
May
函数光滑化杂谈:不可导函数的可导逼近
By 苏剑林 | 2019-05-20 | 123268位读者 | 引用一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。
还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到$\text{argmax}$等操作),所以没法直接用。
这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀鸡”的方案;另外一种是试图给正确率找一个光滑可导的近似公式。本文就来探讨一下常见的不可导函数的光滑近似,有时候我们称之为“光滑化”,有时候我们也称之为“软化”。
max
后面谈到的大部分内容,基础点就是$\max$操作的光滑近似,我们有:
\begin{equation}\max(x_1,x_2,\dots,x_n) = \lim_{K\to +\infty}\frac{1}{K}\log\left(\sum_{i=1}^n e^{K x_i}\right)\end{equation}
10
Oct
用狄拉克函数来构造非光滑函数的光滑近似
By 苏剑林 | 2021-10-10 | 74660位读者 | 引用在机器学习中,我们经常会碰到不光滑的函数,但我们的优化方法通常是基于梯度的,这意味着光滑的模型可能更利于优化(梯度是连续的),所以就有了寻找非光滑函数的光滑近似的需求。事实上,本博客已经多次讨论过相关主题,比如《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等,但以往的讨论在方法上并没有什么通用性。
不过,笔者从最近的一篇论文《SAU: Smooth activation function using convolution with approximate identities》学习到了一种比较通用的思路:用狄拉克函数来构造光滑近似。通用到什么程度呢?理论上有可数个间断点的函数都可以用它来构造光滑近似!个人感觉还是非常有意思的。
23
Mar
梯度下降和EM算法:系出同源,一脉相承
By 苏剑林 | 2017-03-23 | 209895位读者 | 引用PS:本文就是梳理了梯度下降与EM算法的关系,通过同一种思路,推导了普通的梯度下降法、pLSA中的EM算法、K-Means中的EM算法,以此表明它们基本都是同一个东西的不同方面,所谓“横看成岭侧成峰,远近高低各不同”罢了。
在机器学习中,通常都会将我们所要求解的问题表示为一个带有未知参数的损失函数(Loss),如平均平方误差(MSE),然后想办法求解这个函数的最小值,来得到最佳的参数值,从而完成建模。因将函数乘以-1后,最大值也就变成了最小值,因此一律归为最小值来说。如何求函数的最小值,在机器学习领域里,一般会流传两个大的方向:1、梯度下降;2、EM算法,也就是最大期望算法,一般用于复杂的最大似然问题的求解。
在通常的教程中,会将这两个方法描述得迥然不同,就像两大体系在分庭抗礼那样,而EM算法更是被描述得玄乎其玄的感觉。但事实上,这两个方法,都是同一个思路的不同例子而已,所谓“本是同根生”,它们就是一脉相承的东西。
让我们,先从远古的牛顿法谈起。
牛顿迭代法
给定一个复杂的非线性函数$f(x)$,希望求它的最小值,我们一般可以这样做,假定它足够光滑,那么它的最小值也就是它的极小值点,满足$f'(x_0)=0$,然后可以转化为求方程$f'(x)=0$的根了。非线性方程的根我们有个牛顿法,所以
\begin{equation}x_{n+1} = x_{n} - \frac{f'(x_n)}{f''(x_n)}\end{equation}
12
Feb
再来一顿贺岁宴:从K-Means到Capsule
By 苏剑林 | 2018-02-12 | 222654位读者 | 引用在本文中,我们再次对Capsule进行一次分析。
整体上来看,Capsule算法的细节不是很复杂,对照着它的流程把Capsule用框架实现它基本是没问题的。所以,困难的问题是理解Capsule究竟做了什么,以及为什么要这样做,尤其是Dynamic Routing那几步。
为什么我要反复对Capsule进行分析?这并非单纯的“炒冷饭”,而是为了得到对Capsule原理的理解。众所周知,Capsule给人的感觉就是“有太多人为约定的内容”,没有一种“虽然我不懂,但我相信应该就是这样”的直观感受。我希望尽可能将Capsule的来龙去脉思考清楚,使我们能觉得Capsule是一个自然、流畅的模型,甚至对它举一反三。
在《揭开迷雾,来一顿美味的Capsule盛宴》中,笔者先分析了动态路由的结果,然后指出输出是输入的某种聚类,这个“从结果到原因”的过程多多少少有些望文生义的猜测成分;这次则反过来,直接确认输出是输入的聚类,然后反推动态路由应该是怎样的,其中含糊的成分大大减少。两篇文章之间有一定的互补作用。
26
Feb
非对抗式生成模型GLANN的简单介绍
By 苏剑林 | 2019-02-26 | 67728位读者 | 引用前段时间看到facebook发表了一个非对抗的生成模型GLANN(去年12月挂在arxiv上),号称用非对抗的方式也能生成1024的高清人脸,于是饶有兴致地阅读了一番,确实有点收获,但也有点失望。至于为啥失望,大家阅读下去就明白了。
原论文:《Non-Adversarial Image Synthesis with Generative Latent Nearest Neighbors》
机器之心介绍:《为什么让GAN一家独大?Facebook提出非对抗式生成方法GLANN》
效果图:

GLANN效果图
9
Mar
Seq2Seq中Exposure Bias现象的浅析与对策
By 苏剑林 | 2020-03-09 | 95424位读者 | 引用前些天笔者写了《CRF用过了,不妨再了解下更快的MEMM?》,里边提到了MEMM的局部归一化和CRF的全局归一化的优劣。同时,笔者联想到了Seq2Seq模型,因为Seq2Seq模型的典型训练方案Teacher Forcing就是一个局部归一化模型,所以它也存在着局部归一化所带来的毛病——也就是我们经常说的“Exposure Bias”。带着这个想法,笔者继续思考了一翻,将最后的思考结果记录在此文。
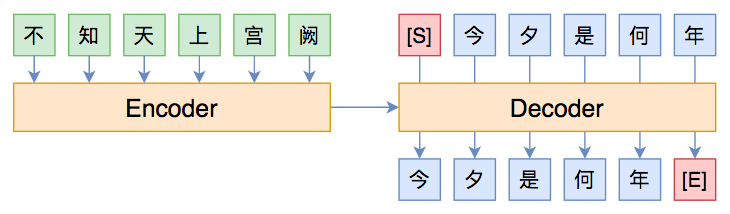
经典的Seq2Seq模型图示
本文算是一篇进阶文章,适合对Seq2Seq模型已经有一定的了解、希望进一步提升模型的理解或表现的读者。关于Seq2Seq的入门文章,可以阅读旧作《玩转Keras之seq2seq自动生成标题》和《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》。
本文的内容大致为:
1、Exposure Bias的成因分析及例子;
2、简单可行的缓解Exposure Bias问题的策略。
25
Apr
将“Softmax+交叉熵”推广到多标签分类问题
By 苏剑林 | 2020-04-25 | 337403位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
一般来说,在处理常规的多分类问题时,我们会在模型的最后用一个全连接层输出每个类的分数,然后用softmax激活并用交叉熵作为损失函数。在这篇文章里,我们尝试将“Softmax+交叉熵”方案推广到多标签分类场景,希望能得到用于多标签分类任务的、不需要特别调整类权重和阈值的loss。

类别不平衡
单标签到多标签
一般来说,多分类问题指的就是单标签分类问题,即从$n$个候选类别中选$1$个目标类别。假设各个类的得分分别为$s_1,s_2,
\dots,s_n$,目标类为$t\in\{1,2,\dots,n\}$,那么所用的loss为
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_{i=1}^n e^{s_i}}= - s_t + \log \sum\limits_{i=1}^n e^{s_i}\label{eq:log-softmax}\end{equation}
这个loss的优化方向是让目标类的得分$s_t$变为$s_1,s_2,\dots,s_t$中的最大值。关于softmax的相关内容,还可以参考《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等文章。

最近评论