






17
Aug
【中文分词系列】 1. 基于AC自动机的快速分词
By 苏剑林 | 2016-08-17 | 97352位读者 | 引用前言:这个暑假花了不少时间在中文分词和语言模型上面,碰了无数次壁,也得到了零星收获。打算写一个专题,分享一下心得体会。虽说是专题,但仅仅是一些笔记式的集合,并非系统的教程,请读者见谅。
中文分词
关于中文分词的介绍和重要性,我就不多说了,matrix67这里有一篇关于分词和分词算法很清晰的介绍,值得一读。在文本挖掘中,虽然已经有不少文章探索了不分词的处理方法,如本博客的《文本情感分类(三):分词 OR 不分词》,但在一般场合都会将分词作为文本挖掘的第一步,因此,一个有效的分词算法是很重要的。当然,中文分词作为第一步,已经被探索很久了,目前做的很多工作,都是总结性质的,最多是微弱的改进,并不会有很大的变化了。
目前中文分词主要有两种思路:查词典和字标注。首先,查词典的方法有:机械的最大匹配法、最少词数法,以及基于有向无环图的最大概率组合,还有基于语言模型的最大概率组合,等等。查词典的方法简单高效(得益于动态规划的思想),尤其是结合了语言模型的最大概率法,能够很好地解决歧义问题,但对于中文分词一大难度——未登录词(中文分词有两大难度:歧义和未登录词),则无法解决;为此,人们也提出了基于字标注的思路,所谓字标注,就是通过几个标记(比如4标注的是:single,单字成词;begin,多字词的开头;middle,三字以上词语的中间部分;end,多字词的结尾),把句子的正确分词法表示出来。这是一个序列(输入句子)到序列(标记序列)的过程,能够较好地解决未登录词的问题,但速度较慢,而且对于已经有了完备词典的场景下,字标注的分词效果可能也不如查词典方法。总之,各有优缺点(似乎是废话~),实际使用可能会结合两者,像结巴分词,用的是有向无环图的最大概率组合,而对于连续的单字,则使用字标注的HMM模型来识别。
18
Aug
【中文分词系列】 2. 基于切分的新词发现
By 苏剑林 | 2016-08-18 | 123441位读者 | 引用上一篇文章讲的是基于词典和AC自动机的快速分词。基于词典的分词有一个明显的优点,就是便于维护,容易适应领域。如果迁移到新的领域,那么只需要添加对应的领域新词,就可以实现较好地分词。当然,好的、适应领域的词典是否容易获得,这还得具体情况具体分析。本文要讨论的就是新词发现这一部分的内容。
这部分内容在去年的文章《新词发现的信息熵方法与实现》已经讨论过了,算法是来源于matrix67的文章《互联网时代的社会语言学:基于SNS的文本数据挖掘》。在那篇文章中,主要利用了三个指标——频数、凝固度(取对数之后就是我们所说的互信息熵)、自由度(边界熵)——来判断一个片段是否成词。如果真的动手去实现过这个算法的话,那么会发现有一系列的难度。首先,为了得到$n$字词,就需要找出$1\sim n$字的切片,然后分别做计算,这对于$n$比较大时,是件痛苦的时间;其次,最最痛苦的事情是边界熵的计算,边界熵要对每一个片段就行分组统计,然后再计算,这个工作量的很大的。本文提供了一种方案,可以使得新词发现的计算量大大降低。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 81170位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
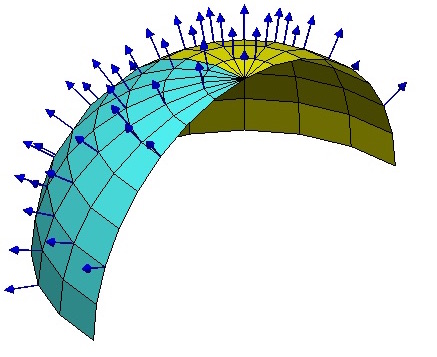
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
2
Nov
【理解黎曼几何】8. 处处皆几何 (力学几何化)
By 苏剑林 | 2016-11-02 | 58570位读者 | 引用黎曼几何在广义相对论中的体现和应用,虽然不能说家喻户晓,但想必大部分读者都有所听闻。一谈到黎曼几何在物理学中的应用,估计大家的第一反应就是广义相对论。常见的观点是,广义相对论的发现大大推动了黎曼几何的发展。诚然,这是事实,然而,大多数人不知道的事,哪怕经典的牛顿力学中,也有黎曼几何的身影。
本文要谈及的内容,就是如何将力学几何化,从而使用黎曼几何的概念来描述它们。整个过程事实上是提供了一种框架,它可以将不少其他领域的理论纳入到黎曼几何体系中。
黎曼几何的出发点就是黎曼度量,通过黎曼度量可以通过变分得到测地线。从这个意义上来看,黎曼度量提供了一个变分原理。那反过来,一个变分原理,能不能提供一个黎曼度量呢?众所周知,不少学科的基础原理都可以归结为一个极值原理,而有了极值原理就不难导出变分原理(泛函极值),如物理中就有最小作用量原理、最小势能原理,概率论中有最大熵原理,等等。如果有一个将变分原理导出黎曼度量的方法,那么就可以用几何的方式来描述它。幸运的是,对于二次型的变分原理,是可以做到的。
21
Oct
【理解黎曼几何】7. 高斯-博内公式
By 苏剑林 | 2016-10-21 | 38627位读者 | 引用令人兴奋的是,我们导出黎曼曲率的途径,还能够让我们一瞥高斯-博内公式( Gauss–Bonnet formula)的风采,真正体验一番研究内蕴几何的味道。
高斯-博内公式是大范围微分几何学的一个经典的公式,它建立了空间的局部性质和整体性质之间的联系。而我们从一条几何的路径出发,结合一些矩阵变换和数学分析的内容,逐步导出了测地线、协变导数、曲率张量,现在可以还可以得到经典的高斯-博内公式,可见我们在这条路上已经走得足够远了。虽然过程不尽善尽美,然而并没有脱离这个系列的核心:几何直观。本文的目的,正是分享黎曼几何的一种直观思路,既然是思路,以思想交流为主,不以严格证明为目的。因此,对于大家来说,这个系列权当黎曼几何的补充材料吧。
形式改写
首先,我们可以将式$(48)$重写为更有几何意义的形式。从
11
Nov
【外微分浅谈】7. 有力的计算
By 苏剑林 | 2016-11-11 | 27434位读者 | 引用这里我们将展示上面一节的方法对于计算黎曼曲率张量的计算是多少的有力!我们再次列出我们得到的所有公式。首先是概念式的
$$\begin{aligned}&\omega^{\mu}=h_{\alpha}^{\mu}dx^{\alpha}\\
&d\boldsymbol{r}=\hat{\boldsymbol{e}}_{\mu} \omega^{\mu}\\
&ds^2 = \eta_{\mu\nu} \omega^{\mu}\omega^{\nu}\\
&\langle \hat{\boldsymbol{e}}_{\mu}, \hat{\boldsymbol{e}}_{\nu}\rangle = \eta_{\mu\nu}\end{aligned} \tag{65} $$
然后是
$$\begin{aligned}&d\eta_{\mu\nu}=\omega_{\nu\mu}+\omega_{\mu\nu}=\eta_{\nu\alpha}\omega_{\mu}^{\alpha}+\eta_{\mu \alpha}\omega_{\nu}^{\alpha}\\
&d\omega^{\mu}+\omega_{\nu}^{\mu}\land \omega^{\nu}=0\end{aligned} \tag{66} $$
这两个可以帮助我们确定$\omega_{\nu}^{\mu}$;接着就是
$$\mathscr{R}_{\nu}^{\mu} = d\omega_{\nu}^{\mu}+\omega_{\alpha}^{\mu} \land \omega_{\nu}^{\alpha} \tag{67} $$
最后你要正交标架下的$\hat{R}^{\mu}_{\nu\beta\gamma}$,就要写出:
$$\mathscr{R}_{\nu}^{\mu}=\sum_{\beta < \gamma} \hat{R}^{\mu}_{\nu\beta\gamma}\omega^{\beta}\land \omega^{\gamma} \tag{68} $$
如果你要原始标架下的$R^{\mu}_{\nu\beta\gamma}$,就要写出
$$(h^{-1})_{\mu'}^{\mu}\mathscr{R}^{\mu'}_{\nu'}h_{\nu}^{\nu'} = \sum_{\beta < \gamma} R^{\mu}_{\nu\beta\gamma}dx^{\beta}\land dx^{\gamma} \tag{69} $$
然后依次读出$R^{\mu}_{\nu\beta\gamma}$,就像制表一样。
31
Dec
2017年快乐!Responsive Geekg for Typecho
By 苏剑林 | 2016-12-31 | 34089位读者 | 引用
7
Jan
基于遗忘假设的平滑公式
By 苏剑林 | 2017-01-07 | 21355位读者 | 引用统计是通过大量样本来估计真实分布的过程,通常与统计相伴出现的一个词是“平滑”,即对统计结果打折扣的处理过程。平滑的思想来源于:如果样本空间非常大,那么统计的结果是稀疏的,这样由于各种偶然因素的存在,导致了小的统计结果不可靠,如频数为1的结果可能只是偶然的结果,其频率并不一定近似于$1/N$,频数为0的不一定就不会出现。这样我们就需要对统计结果进行平滑,使得结论更为可靠。
平滑的方法有很多,这里介绍一种基于遗忘假设的平滑公式。假设的任务为:我们要从一批语料中,统计每个字的字频。我们模仿人脑遗忘的过程,假设这个字出现一次,我们脑里的记忆量就增加1,但是如果一个周期内(先不管这个周期多大),这个字都没有出现,那么脑里的记忆量就变为原来的$\beta$比例。假设字是周期性出现的,那么记忆量$A_n$就满足如下递推公式
$$A_{n+1} = \beta A_n + 1$$

最近评论