






3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 404130位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
16
Feb
Google新搜出的优化器Lion:效率与效果兼得的“训练狮”
By 苏剑林 | 2023-02-16 | 48604位读者 | 引用昨天在Arixv上发现了Google新发的一篇论文《Symbolic Discovery of Optimization Algorithms》,主要是讲自动搜索优化器的,咋看上去没啥意思,因为类似的工作也有不少,大多数结果都索然无味。然而,细读之下才发现别有洞天,原来作者们通过数千TPU小时的算力搜索并结合人工干预,得到了一个速度更快、显存更省的优化器Lion(EvoLved Sign Momentum,不得不吐槽这名字起得真勉强),并在图像分类、图文匹配、扩散模型、语言模型预训练和微调等诸多任务上做了充分的实验,多数任务都显示Lion比目前主流的AdamW等优化器有着更好的效果。
更省显存还更好效果,真可谓是鱼与熊掌都兼得了,什么样的优化器能有这么强悍的性能?本文一起来欣赏一下论文的成果。
先说结果
本文主要关心搜索出来的优化器本身,所以关于搜索过程的细节就不讨论了,对此有兴趣读者自行看原论文就好。Lion优化器的更新过程为
\begin{equation}\text{Lion}:=\left\{\begin{aligned}
&\boldsymbol{u}_t = \text{sign}\big(\beta_1 \boldsymbol{m}_{t-1} + \left(1 - \beta_1\right) \boldsymbol{g}_t\big) \\
&\boldsymbol{\theta}_t = \boldsymbol{\theta}_{t-1} - \eta_t (\boldsymbol{u}_t \color{skyblue}{ + \lambda_t \boldsymbol{\theta}_{t-1}}) \\
&\boldsymbol{m}_t = \beta_2 \boldsymbol{m}_{t-1} + \left(1 - \beta_2\right) \boldsymbol{g}_t
\end{aligned}\right.\end{equation}
26
Dec
【学习清单】最近比较重要的GAN进展论文
By 苏剑林 | 2018-12-26 | 65017位读者 | 引用这篇文章简单列举一下我认为最近这段时间中比较重要的GAN进展论文,这基本也是我在学习GAN的过程中主要去研究的论文清单。
生成模型之味
GAN是一个大坑,尤其像我这样的业余玩家,一头扎进去很久也很难有什么产出,尤其是各个大公司拼算力搞出来一个个大模型,个人几乎都没法玩了。但我总觉得,真的去碰了生成模型,才觉得自己碰到了真正的机器学习。这一点,不管在图像中还是文本中都是如此。所以,我还是愿意去关注生成模型。
当然,GAN不是生成模型的唯一选择,却是一个非常有趣的选择。在图像中至少有GAN、flow、pixelrnn/pixelcnn这几种选择,但要说潜力,我还是觉得GAN才是最具前景的,不单是因为效果,主要是因为它那对抗的思想。而在文本中,事实上seq2seq机制就是一个概率生成模型了,而pixelrnn这类模型,实际上就是模仿着seq2seq来做的,当然也有用GAN做文本生成的研究(不过基本上都涉及到了强化学习)。也就是说,其实在NLP中,生成模型也有很多成果,哪怕你主要是研究NLP的,也终将碰到生成模型。
好了,话不多说,还是赶紧把清单列一列,供大家参考,也作为自己的备忘。
26
Jul
FlatNCE:小批次对比学习效果差的原因竟是浮点误差?
By 苏剑林 | 2021-07-26 | 45269位读者 | 引用自SimCLR在视觉无监督学习大放异彩以来,对比学习逐渐在CV乃至NLP中流行了起来,相关研究和工作越来越多。标准的对比学习的一个广为人知的缺点是需要比较大的batch_size(SimCLR在batch_size=4096时效果最佳),小batch_size的时候效果会明显降低,为此,后续工作的改进方向之一就是降低对大batch_size的依赖。那么,一个很自然的问题是:标准的对比学习在小batch_size时效果差的原因究竟是什么呢?
近日,一篇名为《Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE》对此问题作出了回答:因为浮点误差。看起来真的很让人难以置信,但论文的分析确实颇有道理,并且所提出的改进FlatNCE确实也工作得更好,让人不得不信服。
细微之处
接下来,笔者将按照自己的理解和记号来介绍原论文的主要内容。对比学习(Contrastive Learning)就不帮大家详细复习了,大体上来说,对于某个样本$x$,我们需要构建$K$个配对样本$y_1,y_2,\cdots,y_K$,其中$y_t$是正样本而其余都是负样本,然后分别给每个样本对$(x, y_i)$打分,分别记为$s_1,s_2,\cdots,s_K$,对比学习希望拉大正负样本对的得分差,通常直接用交叉熵作为损失:
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_i e^{s_i}} = \log \left(\sum_i e^{s_i}\right) - s_t = \log \left(1 + \sum_{i\neq t} e^{s_i - s_t}\right)\end{equation}
8
Feb
多任务学习漫谈(二):行梯度之事
By 苏剑林 | 2022-02-08 | 51187位读者 | 引用在《多任务学习漫谈(一):以损失之名》中,我们从损失函数的角度初步探讨了多任务学习问题,最终发现如果想要结果同时具有缩放不变性和平移不变性,那么用梯度的模长倒数作为任务的权重是一个比较简单的选择。我们继而分析了,该设计等价于将每个任务的梯度单独进行归一化后再相加,这意味着多任务的“战场”从损失函数转移到了梯度之上:看似在设计损失函数,实则在设计更好的梯度,所谓“以损失之名,行梯度之事”。
那么,更好的梯度有什么标准呢?如何设计出更好的梯度呢?本文我们就从梯度的视角来理解多任务学习,试图直接从设计梯度的思路出发构建多任务学习算法。
整体思路
我们知道,对于单任务学习,常用的优化方法就是梯度下降,那么它是怎么推导的呢?同样的思路能不能直接用于多任务学习呢?这便是这一节要回答的问题。
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 417559位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
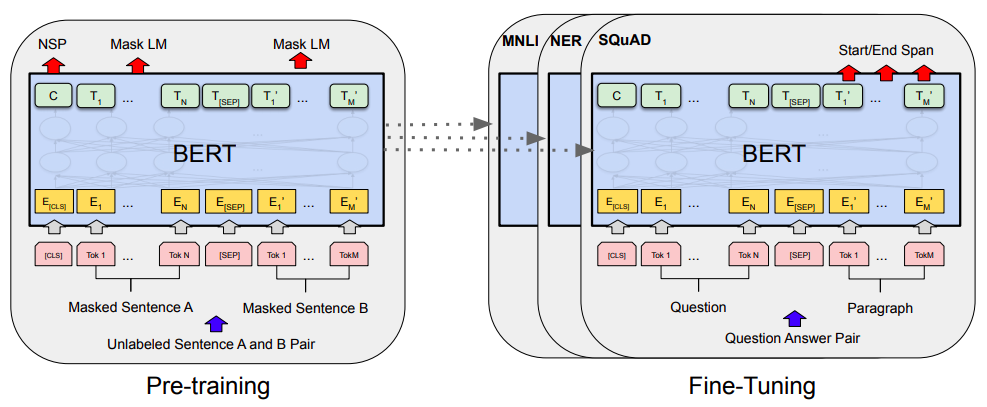
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
14
Dec
端到端的腾讯验证码识别(46%正确率)
By 苏剑林 | 2016-12-14 | 74996位读者 | 引用最新结果请参考:http://kexue.fm/archives/4503/
前段时间有幸得到了一个网友提供的一批带标签的腾讯验证码样本(验证码样板:http://captcha.qq.com/getimage),于是抽了点时间,测试了一下验证码识别的模型。

腾讯验证码
样本
这批验证码比较简单,4位的英文字母,有大小写,但输入的时候不区分大小写,图案有一定的混淆,传统的基于分割的方案估计比较难办。端到端的方案是,直接将验证码输入,做几个卷积层,然后连接几个分类器(26分类),然后就直接输出四个字母标签了。其实还真没有什么好说的,有样本就能做了,而且这个框架是通用的,可以用到区分大小写的情形(52分类),也可以用到英文数字混合的情形(再加10个类别而已)。
14
Mar


最近评论