






1
May
以蒸馏的名义:“从去噪自编码器到生成模型”重现江湖
By 苏剑林 | 2024-05-01 | 37879位读者 | 引用今天我们分享一下论文《Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation》,顾名思义,这是一篇探讨如何更快更好地蒸馏扩散模型的新论文。
即便没有做过蒸馏,大家应该也能猜到蒸馏的常规步骤:随机采样大量输入,然后用扩散模型生成相应结果作为输出,用这些输入输出作为训练数据对,来监督训练一个新模型。然而,众所周知作为教师的原始扩散模型通常需要多步(比如1000步)迭代才能生成高质量输出,所以且不论中间训练细节如何,该方案的一个显著缺点是生成训练数据太费时费力。此外,蒸馏之后的学生模型通常或多或少都有效果损失。
有没有方法能一次性解决这两个缺点呢?这就是上述论文试图要解决的问题。
5
Jun
重温SSM(二):HiPPO的一些遗留问题
By 苏剑林 | 2024-06-05 | 19462位读者 | 引用书接上文,在上一篇文章《重温SSM(一):线性系统和HiPPO矩阵》中,我们详细讨论了HiPPO逼近框架其HiPPO矩阵的推导,其原理是通过正交函数基来动态地逼近一个实时更新的函数,其投影系数的动力学正好是一个线性系统,而如果以正交多项式为基,那么线性系统的核心矩阵我们可以解析地求解出来,该矩阵就称为HiPPO矩阵。
当然,上一篇文章侧重于HiPPO矩阵的推导,并没有对它的性质做进一步分析,此外诸如“如何离散化以应用于实际数据”、“除了多项式基外其他基是否也可以解析求解”等问题也没有详细讨论到。接下来我们将补充探讨相关问题。
离散格式
假设读者已经阅读并理解上一篇文章的内容,那么这里我们就不再进行过多的铺垫。在上一篇文章中,我们推导出了两类线性ODE系统,分别是:
\begin{align}
&\text{HiPPO-LegT:}\quad x'(t) = Ax(t) + Bu(t) \label{eq:legt-ode}\\[5pt]
&\text{HiPPO-LegS:}\quad x'(t) = \frac{A}{t}x(t) + \frac{B}{t}u(t) \label{eq:legs-ode}\end{align}
其中$A,B$是与时间$t$无关的常数矩阵,HiPPO矩阵主要指矩阵$A$。在这一节中,我们讨论这两个ODE的离散化。
20
Jun
重温SSM(三):HiPPO的高效计算(S4)
By 苏剑林 | 2024-06-20 | 22487位读者 | 引用前面我们用两篇文章《重温SSM(一):线性系统和HiPPO矩阵》和《重温SSM(二):HiPPO的一些遗留问题》介绍了HiPPO的思想和推导——通过正交函数基对持续更新的函数进行实时逼近,其拟合系数的动力学正好可以表示为一个线性ODE系统,并且对于特定的基底以及逼近方式,我们可以将线性系统的关键矩阵精确地算出来。此外,我们还讨论了HiPPO的离散化和相关性质等问题,这些内容奠定了后续的SSM工作的理论基础。
接下来,我们将介绍HiPPO的后续应用篇《Efficiently Modeling Long Sequences with Structured State Spaces》(简称S4),它利用HiPPO的推导结果作为序列建模的基本工具,并从新的视角探讨了高效的计算和训练方式,最后在不少长序列建模任务上验证了它的有效性,可谓SSM乃至RNN复兴的代表作之一。
基本框架
S4使用的序列建模框架,是如下的线性ODE系统:
\begin{equation}\begin{aligned}
x'(t) =&\, A x(t) + B u(t) \\
y(t) =&\, C^* x(t) + D u(t)
\end{aligned}\end{equation}
27
Jun
重温SSM(四):有理生成函数的新视角
By 苏剑林 | 2024-06-27 | 15971位读者 | 引用在前三篇文章中,我们较为详细地讨论了HiPPO和S4的大部分数学细节。那么,对于接下来的第四篇文章,大家预期我们会讨论什么工作呢?S5、Mamba乃至Mamba2?都不是。本系列文章主要关心SSM的数学基础,旨在了解SSM的同时也补充自己的数学能力。而在上一篇文章我们简单提过S5和Mamba,S5是S4的简化版,相比S4基本上没有引入新的数学技巧,而Mamba系列虽然表现优异,但它已经将$A$简化为对角矩阵,所用到的数学技巧就更少了,它更多的是体现了工程方面的能力。
这篇文章我们来学习一篇暂时还声名不显的新工作《State-Free Inference of State-Space Models: The Transfer Function Approach》(简称RFT),它提出了一个新方案,将SSM的训练、推理乃至参数化,都彻底转到了生成函数空间中,为SSM的理解和应用开辟了新的视角
基础回顾
首先我们简单回顾一下上一篇文章关于S4的探讨结果。S4基于如下线性RNN
\begin{equation}\begin{aligned}
x_{k+1} =&\, \bar{A} x_k + \bar{B} u_k \\
y_{k+1} =&\, \bar{C}^* x_{k+1} \\
\end{aligned}\label{eq:linear}\end{equation}
8
Jul
“闭门造车”之多模态思路浅谈(二):自回归
By 苏剑林 | 2024-07-08 | 38078位读者 | 引用这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。
在前文《“闭门造车”之多模态思路浅谈(一):无损输入》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重的信息损失,所以更有前景或者说更长远的方案应该是输入连续型特征,比如直接将图像的原始像素特征Patchify后输入到模型中。
然而,连续型输入对于图像理解自然简单,但对图像生成来说则引入了额外的困难,因为非离散化无法直接套用文本的自回归框架,多少都要加入一些新内容如扩散,这就引出了本文的主题——如何进行多模态的自回归学习与生成。当然,非离散化只是表面的困难,更艰巨的部份还在后头...
无损含义
首先我们再来明确一下无损的含义。无损并不是指整个计算过程中一丁点损失都不能有,这不现实,也不符合我们所理解的深度学习的要义——在2015年的文章《闲聊:神经网络与深度学习》我们就提到过,深度学习成功的关键是信息损失。所以,这里无损的含义很简单,单纯是希望作为模型的输入来说尽可能无损。
12
Jul
对齐全量微调!这是我看过最精彩的LoRA改进(一)
By 苏剑林 | 2024-07-12 | 38461位读者 | 引用众所周知,LoRA是一种常见的参数高效的微调方法,我们在《梯度视角下的LoRA:简介、分析、猜测及推广》做过简单介绍。LoRA利用低秩分解来降低微调参数量,节省微调显存,同时训练好的权重可以合并到原始权重上,推理架构不需要作出改变,是一种训练和推理都比较友好的微调方案。此外,我们在《配置不同的学习率,LoRA还能再涨一点?》还讨论过LoRA的不对称性,指出给$A,B$设置不同的学习率能取得更好的效果,该结论被称为“LoRA+”。
为了进一步提升效果,研究人员还提出了不少其他LoRA变体,如AdaLoRA、rsLoRA、DoRA、PiSSA等,这些改动都有一定道理,但没有特别让人深刻的地方觉。然而,前两天的《LoRA-GA: Low-Rank Adaptation with Gradient Approximation》,却让笔者眼前一亮,仅扫了摘要就有种必然有效的感觉,仔细阅读后更觉得它是至今最精彩的LoRA改进。
究竟怎么个精彩法?LoRA-GA的实际含金量如何?我们一起来学习一下。
24
Jul
Monarch矩阵:计算高效的稀疏型矩阵分解
By 苏剑林 | 2024-07-24 | 19514位读者 | 引用在矩阵压缩这个问题上,我们通常有两个策略可以选择,分别是低秩化和稀疏化。低秩化通过寻找矩阵的低秩近似来减少矩阵尺寸,而稀疏化则是通过减少矩阵中的非零元素来降低矩阵的复杂性。如果说SVD是奔着矩阵的低秩近似去的,那么相应地寻找矩阵稀疏近似的算法又是什么呢?
接下来我们要学习的是论文《Monarch: Expressive Structured Matrices for Efficient and Accurate Training》,它为上述问题给出了一个答案——“Monarch矩阵”,这是一簇能够分解为若干置换矩阵与稀疏矩阵乘积的矩阵,同时具备计算高效且表达能力强的特点,论文还讨论了如何求一般矩阵的Monarch近似,以及利用Monarch矩阵参数化LLM来提高LLM速度等内容。
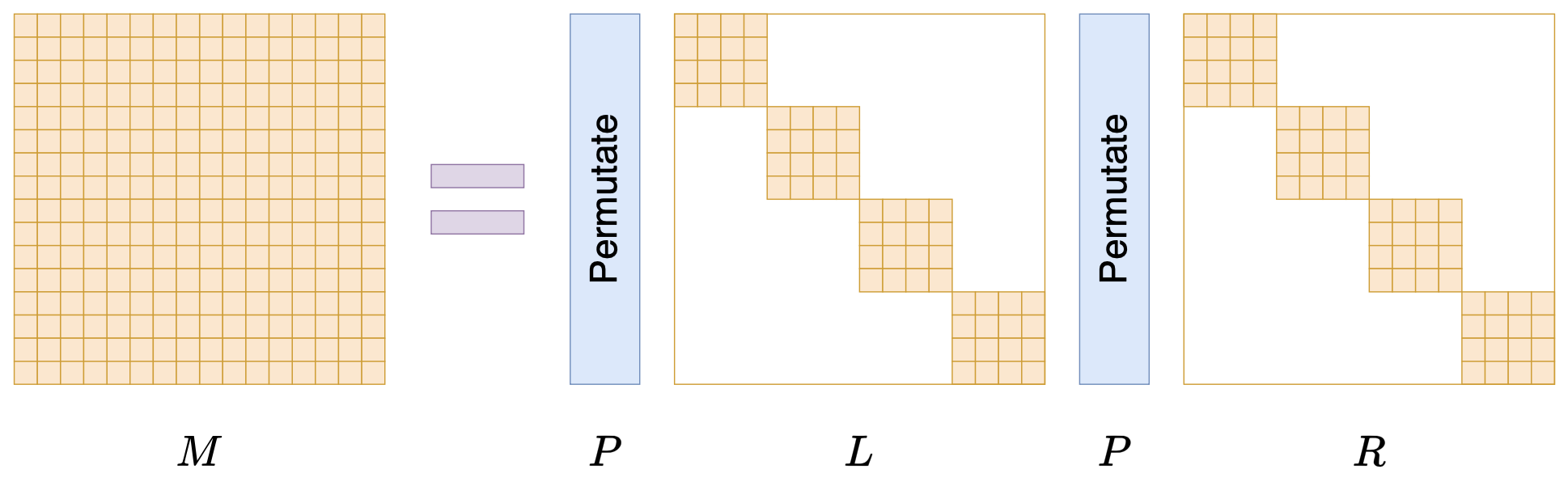
Monarch矩阵形式M=PLPR
值得指出的是,该论文的作者也正是著名的Flash Attention的作者Tri Dao,其工作几乎都在致力于改进LLM的性能,这篇Monarch也是他主页上特意展示的几篇论文之一,单从这一点看就非常值得学习一番。
6
Aug
通向最优分布之路:概率空间的最小化
By 苏剑林 | 2024-08-06 | 16239位读者 | 引用当要求函数的最小值时,我们通常会先求导函数然后寻找其零点,比较幸运的情况下,这些零点之一正好是原函数的最小值点。如果是向量函数,则将导数改为梯度并求其零点。当梯度零点不易求得时,我们可以使用梯度下降来逐渐逼近最小值点。
以上这些都是无约束优化的基础结果,相信不少读者都有所了解。然而,本文的主题是概率空间中的优化,即目标函数的输入是一个概率分布,这类目标的优化更为复杂,因为它的搜索空间不再是无约束的,如果我们依旧去求解梯度零点或者执行梯度下降,所得结果未必能保证是一个概率分布。因此,我们需要寻找一种新的分析和计算方法,以确保优化结果能够符合概率分布的特性。
对此,笔者一直以来也感到颇为头疼,所以近来决定”痛定思痛“,针对概率分布的优化问题系统学习了一番,最后将学习所得整理在此,供大家参考。

最近评论