






18
Jan
当大数据进入厨房:让大数据教你做菜!
By 苏剑林 | 2016-01-18 | 43257位读者 | 引用说在前面

美食(图片来源于互联网)
在空间侧边栏的笔者的自我介绍中,有一行是“厨房爱好者”,虽然笔者不怎么会做菜,但确实,厨房是我的一个爱好。当然,笔者的爱好很多,数学、物理、天文、计算机等,都喜欢,都想学,弄到多而不精。在之前的文章中也已经提到过,数据挖掘也是我的一个爱好,而当数据挖掘跟厨房这两个爱好相遇了,会有什么有趣的结果吗?
笔者正是做了这样一个事情:从美食中国的家常菜目录下面,写了个简单的爬虫,抓取了一批菜谱数据下来,进行简单的数据分析。(在此对美食中国表示衷心感谢。选择美食中国的原因是它的数据比较规范。)数据分析在我目前公司的高性能服务器做,分析起来特别舒服~~
这里共收集了18209个菜谱,共包含了9700种食材(包括主料、辅料、调料,部分可能由于命名不规范等原因会重复)。当然,这个数据量相对于很多领域的大数据标准来说,实在不值一提。但是在大数据极少涉及的厨房,应该算是比较多的了。
6
Mar
Openwrt自动扫描WiFi并连接中继
By 苏剑林 | 2016-03-06 | 55611位读者 | 引用
18
May
调侃:万有引力与爱因斯坦的理论
By 苏剑林 | 2016-05-18 | 49564位读者 | 引用我不是研究引力的,也没有很好地学习过引力。在理论物理方面,我学习经典力学和量子力学比学习广义相对论要多得多。因此,本来我是不应该谈引力的,以免误人子弟。不过,在一次坐车的途中,司机的刹车和加速让我联想到了一些跟引力有关的东西,自我感觉比较有趣,所以发给大家分享一下,也请大家指正。
等效原理

坐汽车
引力,准确来说应该是“万有引力”。所谓“万有”,有两个含义:1、所有物体都能够产生引力;2、所有物体都被引力影响。一个力居然是“万有”的,这让爱因斯坦感觉到非常奇怪,这也是四种基本力之中,引力跟其他力区别最明显的地方。相比之下,电磁相互作用力就只能存在于有“电”的地方,弱相互作用只存在于费米子,等等。
除了引力之外,我们平时还遇到过什么“万有”的力吗?貌似没有。但是我们想象一下,当你坐在一辆长途大巴匀速前进时,突然司机来了一个急刹车,在刹车的那一瞬间,所有人都往前倾了,不仅如此,可能你的行李箱、你的随身物品都往前移的,事实上,车上所有东西都受到了一个往前的力!对于那辆车上的人和物来说,刹车的那一瞬间,就存在着一个“万有”的力!
18
Jun
OCR技术浅探:3. 特征提取(2)
By 苏剑林 | 2016-06-18 | 39442位读者 | 引用
26
Jun
OCR技术浅探:7. 语言模型
By 苏剑林 | 2016-06-26 | 51569位读者 | 引用由于图像质量等原因,性能再好的识别模型,都会有识别错误的可能性,为了减少识别错误率,可以将识别问题跟统计语言模型结合起来,通过动态规划的方法给出最优的识别结果.这是改进OCR识别效果的重要方法之一.
转移概率
在我们分析实验结果的过程中,有出现这一案例.由于图像不清晰等可能的原因,导致“电视”一词被识别为“电柳”,仅用图像模型是不能很好地解决这个问题的,因为从图像模型来看,识别为“电柳”是最优的选择.但是语言模型却可以很巧妙地解决这个问题.原因很简单,基于大量的文本数据我们可以统计“电视”一词和“电柳”一词的概率,可以发现“电视”一词的概率远远大于“电柳”,因此我们会认为这个词是“电视”而不是“电柳”.
从概率的角度来看,就是对于第一个字的区域的识别结果$s_1$,我们前面的卷积神经网络给出了“电”、“宙”两个候选字(仅仅选了前两个,后面的概率太小),每个候选字的概率$W(s_1)$分别为0.99996、0.00004;第二个字的区域的识别结果$s_2$,我们前面的卷积神经网络给出了“柳”、“视”、“规”(仅仅选了前三个,后面的概率太小),每个候选字的概率$W(s_2)$分别为0.87838、0.12148、0.00012,因此,它们事实上有六种组合:“电柳”、“电视”、“电规”、“宙柳”、“宙视”、“宙规”.
1
Jul
从Boosting学习到神经网络:看山是山?
By 苏剑林 | 2016-07-01 | 65945位读者 | 引用前段时间在潮州给韩师的同学讲文本挖掘之余,涉猎到了Boosting学习算法,并且做了一番头脑风暴,最后把Boosting学习算法的一些本质特征思考清楚了,而且得到一些意外的结果,比如说AdaBoost算法的一些理论证明也可以用来解释神经网络模型这么强大。
AdaBoost算法
Boosting学习,属于组合模型的范畴,当然,与其说它是一个算法,倒不如说是一种解决问题的思路。以有监督的分类问题为例,它说的是可以把弱的分类器(只要准确率严格大于随机分类器)通过某种方式组合起来,就可以得到一个很优秀的分类器(理论上准确率可以100%)。AdaBoost算法是Boosting算法的一个例子,由Schapire在1996年提出,它构造了一种Boosting学习的明确的方案,并且从理论上给出了关于错误率的证明。
以二分类问题为例子,假设我们有一批样本$\{x_i,y_i\},i=1,2,\dots,n$,其中$x_i$是样本数据,有可能是多维度的输入,$y_i\in\{1,-1\}$为样本标签,这里用1和-1来描述样本标签而不是之前惯用的1和0,只是为了后面证明上的方便,没有什么特殊的含义。接着假设我们已经有了一个弱分类器$G(x)$,比如逻辑回归、SVM、决策树等,对分类器的唯一要求是它的准确率要严格大于随机(在二分类问题中就是要严格大于0.5),所谓严格大于,就是存在一个大于0的常数$\epsilon$,每次的准确率都不低于$\frac{1}{2}+\epsilon$。
16
Oct
【理解黎曼几何】4. 联络和协变导数
By 苏剑林 | 2016-10-16 | 82926位读者 | 引用向量与联络
当我们在我们的位置建立起自己的坐标系后,我们就可以做很多测量,测量的结果可能是一个标量,比如温度、质量,这些量不管你用什么坐标系,它都是一样的。当然,有时候我们会测量向量,比如速度、加速度、力等,这些量都是客观实体,但因为测量结果是用坐标的分量表示的,所以如果换一个坐标,它的分量就完全不一样了。
假如所有的位置都使用同样的坐标,那自然就没有什么争议了,然而我们前面已经反复强调,不同位置的人可能出于各种原因,使用了不同的坐标系,因此,当我们写出一个向量$A^{\mu}$时,严格来讲应该还要注明是在$\boldsymbol{x}$位置测量的:$A^{\mu}(\boldsymbol{x})$,只有不引起歧义的情况下,我们才能省略它。
到这里,我们已经能够进行一些计算,比如$A^{\mu}$是在$\boldsymbol{x}$处测量的,而$\boldsymbol{x}$处的模长计算公式为$ds^2 = g_{\mu\nu} dx^{\mu} dx^{\nu}$,因此,$A^{\mu}$的模长为$\sqrt{g_{\mu\nu} A^{\mu}A^{\nu}}$,它是一个客观实体。
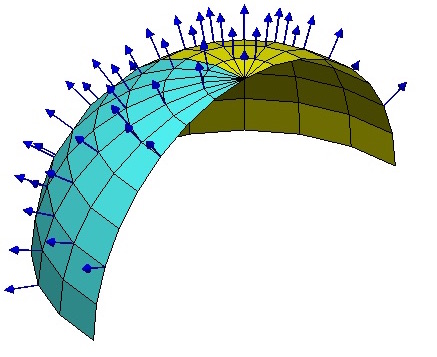
如图,可以在球面上每一点建立不同的局部坐标系,至少这些坐标系的竖直方向的轴指向是不一样的。
4
Nov
【外微分浅谈】2. 反对称的威力
By 苏剑林 | 2016-11-04 | 46585位读者 | 引用内积与外积
向量(这里暂时指的是二维或者三维空间中的向量)的强大之处,在于它定义了内积和外积(更多时候称为叉积、向量积等),它们都是两个向量之间的运算,其中,内积被定义为是对称的,而外积则被定义为反对称的,它们都满足分配律。
沿着书本的传统,我们用$\langle,\rangle$表示内积,用$\land$表示外积,对于外积,更多的时候是用$\times$,但为了不至于出现太多的符号,我们统一使用$\land$。我们将向量用基的形式写出来,比如
$$\boldsymbol{A}=\boldsymbol{e}_{\mu}A^{\mu} \tag{1} $$
其中$\boldsymbol{e}_{\mu}$代表着一组基,而$A^{\mu}$则是向量的分量。我们来计算两个向量$\boldsymbol{A},\boldsymbol{B}$的内积和外积,即
$$\begin{aligned}&\langle \boldsymbol{A}, \boldsymbol{B}\rangle=\langle \boldsymbol{e}_{\mu}A^{\mu}, \boldsymbol{e}_{\nu}B^{\nu}\rangle=\langle\boldsymbol{e}_{\mu},\boldsymbol{e}_{\nu}\rangle A^{\mu}A^{\nu}\\
&\boldsymbol{A}\land \boldsymbol{B}=(\boldsymbol{e}_{\mu}A^{\mu})\land (\boldsymbol{e}_{\nu}B^{\nu})=\boldsymbol{e}_{\mu}\land\boldsymbol{e}_{\nu} A^{\mu}B^{\nu}
\end{aligned} \tag{2} $$

最近评论