






7
Sep
BytePiece:更纯粹、更高压缩率的Tokenizer
By 苏剑林 | 2023-09-07 | 33372位读者 | 引用目前在LLM中最流行的Tokenizer(分词器)应该是Google的SentencePiece了,因为它符合Tokenizer的一些理想特性,比如语言无关、数据驱动等,并且由于它是C++写的,所以Tokenize(分词)的速度很快,非常适合追求效率的场景。然而,它也有一些明显的缺点,比如训练速度慢(BPE算法)、占用内存大等,同时也正因为它是C++写的,对于多数用户来说它就是黑箱,也不方便研究和二次开发。
事实上,Tokenizer的训练就相当于以往的“新词发现”,而笔者之前也写过中文分词和最小熵系列文章,对新词发现也有一定的积累,所以很早之前就有自己写一版Tokenizer的想法。这几天总算腾出了时间初步完成了这件事情,东施效颦SentencePiece,命名为“BytePiece”。
22
Jul
《虚拟的实在(4)》——质量是什么
By 苏剑林 | 2013-07-22 | 48969位读者 | 引用笔者很少会谈到定义性的东西,原因很简单,因为我也不见得会比大家清楚,或者说也未必比大家所知道的准确。不过,刚刚与同好讨论过与质量相关的问题,就跟大家分享一下。
最初的问题是能量能不能转化为物质,我觉得根据$E=mc^2$,是显然可以的,例子嘛,我首先想到在量子场论中的真空是会不断产生和湮灭正负电子对的,因此这可以作为一个证据。但是这个感觉上太遥远了,所以我在互联网搜索了一下,不过搜到的内容大同小异:
当辐射光子能量足够高时,在它从原子核旁边经过时,在核库仑场作用下,辐射光子可能转化成一个正电子和一个负电子,这种过程称作电子对效应。
(正负电子对效应)
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 193256位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
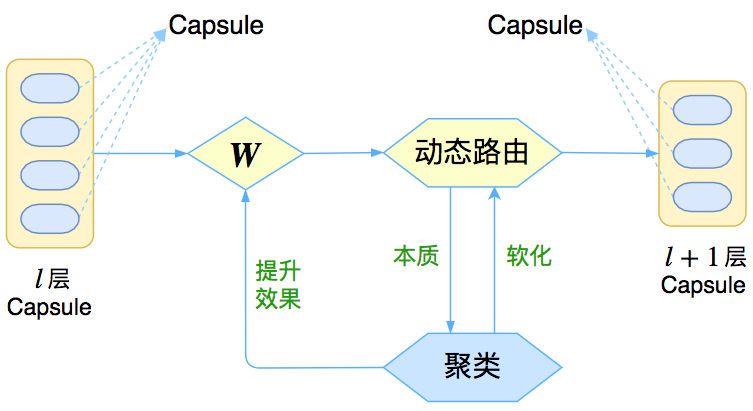
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
10
Mar
“让Keras更酷一些!”:分层的学习率和自由的梯度
By 苏剑林 | 2019-03-10 | 85973位读者 | 引用高举“让Keras更酷一些!”大旗,让Keras无限可能~
今天我们会用Keras做到两件很重要的事情:分层设置学习率和灵活操作梯度。
首先是分层设置学习率,这个用途很明显,比如我们在fine tune已有模型的时候,有些时候我们会固定一些层,但有时候我们又不想固定它,而是想要它以比其他层更低的学习率去更新,这个需求就是分层设置学习率了。对于在Keras中分层设置学习率,网上也有一定的探讨,结论都是要通过重写优化器来实现。显然这种方法不论在实现上还是使用上都不友好。
然后是操作梯度。操作梯度一个最直接的例子是梯度裁剪,也就是把梯度控制在某个范围内,Keras内置了这个方法。但是Keras内置的是全局的梯度裁剪,假如我要给每个梯度设置不同的裁剪方式呢?甚至我有其他的操作梯度的思路,那要怎么实施呢?不会又是重写优化器吧?
本文就来为上述问题给出尽可能简单的解决方案。
6
Jul
生成扩散模型漫谈(二):DDPM = 自回归式VAE
By 苏剑林 | 2022-07-06 | 88535位读者 | 引用在文章《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》中,我们为生成扩散模型DDPM构建了“拆楼-建楼”的通俗类比,并且借助该类比完整地推导了生成扩散模型DDPM的理论形式。在该文章中,我们还指出DDPM本质上已经不是传统的扩散模型了,它更多的是一个变分自编码器VAE,实际上DDPM的原论文中也是将它按照VAE的思路进行推导的。
所以,本文就从VAE的角度来重新介绍一版DDPM,同时分享一下自己的Keras实现代码和实践经验。
Github地址:https://github.com/bojone/Keras-DDPM
多步突破
在传统的VAE中,编码过程和生成过程都是一步到位的:
\begin{equation}\text{编码:}\,\,x\to z\,,\quad \text{生成:}\,\,z\to x\end{equation}
 2009年5月22日,对于很多人来说并不是什么特别的日志,不过数学界这边又传来了一个“喜讯”:我们已经找到了第47个梅森素数,即$2^{42643801}-1$是一个素数!新的素数已于6月12日通过法国的Tony Reix的验证,这是目前的第二大素数,有12,837,064位数字!这是通过参加一个名为“因特网梅森素数大搜索”(GIMPS)的国际合作项目而发现的。让我们来共同回顾这一素数之旅!
2009年5月22日,对于很多人来说并不是什么特别的日志,不过数学界这边又传来了一个“喜讯”:我们已经找到了第47个梅森素数,即$2^{42643801}-1$是一个素数!新的素数已于6月12日通过法国的Tony Reix的验证,这是目前的第二大素数,有12,837,064位数字!这是通过参加一个名为“因特网梅森素数大搜索”(GIMPS)的国际合作项目而发现的。让我们来共同回顾这一素数之旅!
素数/梅森素数
素数,现在课本上都已经成为“质数”了,不过目前很多数学家、爱好者都还是将其称为素数(也许这个名字好听)。这是指一些不可分解成两个比它本身小的两个整数相乘的形式的数,如2、3、5、7等。除了2外,所有的素数都是奇数。
12
Sep
微积分学习(二):导数
By 苏剑林 | 2009-09-12 | 17073位读者 | 引用自从上次写了关于微积分中的极限学习后,就很长的时间没有与大家探讨微积分的学习了(估计有20多天了吧)。启事,我自己也是从今年的9月下旬才开始系统地学习微积分的,到现在也就一个月的时间吧。学习的内容有:集合、函数、极限、导数、微分、积分。不过都是一元微积分,多元的微积分正在紧张地进修中......
现在不妨和大家探讨一下关于微积分中的最基本内容——“导数”的学习。
其实,用最简单的说法,如果存在函数$f(x)$,那么它的导数(一阶导数)为
$$\lim_{\Delta x->0} f'(x)=\frac{f(x+\Delta x)-f(x)}{\Delta x}$$
3
Aug
生成扩散模型漫谈(五):一般框架之SDE篇
By 苏剑林 | 2022-08-03 | 113119位读者 | 引用在写生成扩散模型的第一篇文章时,就有读者在评论区推荐了宋飏博士的论文《Score-Based Generative Modeling through Stochastic Differential Equations》,可以说该论文构建了一个相当一般化的生成扩散模型理论框架,将DDPM、SDE、ODE等诸多结果联系了起来。诚然,这是一篇好论文,但并不是一篇适合初学者的论文,里边直接用到了随机微分方程(SDE)、Fokker-Planck方程、得分匹配等大量结果,上手难度还是颇大的。
不过,在经过了前四篇文章的积累后,现在我们可以尝试去学习一下这篇论文了。在接下来的文章中,笔者将尝试从尽可能少的理论基础出发,尽量复现原论文中的推导结果。
随机微分
在DDPM中,扩散过程被划分为了固定的$T$步,还是用《生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼》的类比来说,就是“拆楼”和“建楼”都被事先划分为了$T$步,这个划分有着相当大的人为性。事实上,真实的“拆”、“建”过程应该是没有刻意划分的步骤的,我们可以将它们理解为一个在时间上连续的变换过程,可以用随机微分方程(Stochastic Differential Equation,SDE)来描述。

最近评论