






18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 600161位读者 |Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
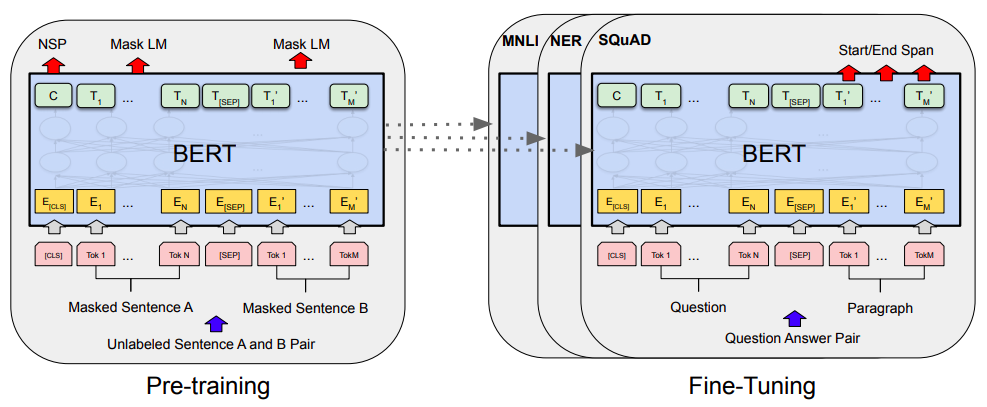
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
当Bert遇上Keras #
很幸运的是,已经有大佬封装好了Keras版的Bert,可以直接调用官方发布的预训练权重,对于已经有一定Keras基础的读者来说,这可能是最简单的调用Bert的方式了。所谓“站在巨人的肩膀上”,就是形容我们这些Keras爱好者此刻的心情了。
keras-bert #
个人认为,目前在Keras下对Bert最好的封装是:
keras-bert:https://github.com/CyberZHG/keras-bert
本文也是以此为基础的。
顺便一提的是,除了keras-bert之外,CyberZHG大佬还封装了很多有价值的keras模块,比如keras-gpt-2(你可以用像用bert一样用gpt2模型了)、keras-lr-multiplier(分层设置学习率)、keras-ordered-neurons(就是前不久介绍的ON-LSTM)等等,汇总可以看这里。看来也是一位Keras铁杆粉丝啊~致敬大佬。
事实上,有了keras-bert之后,再加上一点点keras基础知识,而且keras-bert所给的demo已经足够完善,调用、微调Bert都已经变成了意见没有什么技术含量的事情了。所以后面笔者只是给出几个中文的例子,来让读者上手keras-bert的基本用法。
Tokenizer #
正式讲例子之前,还有必要先讲一下Tokenizer相关内容。我们导入Bert的Tokenizer并重构一下它:
from keras_bert import load_trained_model_from_checkpoint, Tokenizer
import codecs
config_path = '../bert/chinese_L-12_H-768_A-12/bert_config.json'
checkpoint_path = '../bert/chinese_L-12_H-768_A-12/bert_model.ckpt'
dict_path = '../bert/chinese_L-12_H-768_A-12/vocab.txt'
token_dict = {}
with codecs.open(dict_path, 'r', 'utf8') as reader:
for line in reader:
token = line.strip()
token_dict[token] = len(token_dict)
class OurTokenizer(Tokenizer):
def _tokenize(self, text):
R = []
for c in text:
if c in self._token_dict:
R.append(c)
elif self._is_space(c):
R.append('[unused1]') # space类用未经训练的[unused1]表示
else:
R.append('[UNK]') # 剩余的字符是[UNK]
return R
tokenizer = OurTokenizer(token_dict)
tokenizer.tokenize(u'今天天气不错')
# 输出是 ['[CLS]', u'今', u'天', u'天', u'气', u'不', u'错', '[SEP]']
这里简单解释一下Tokenizer的输出结果。首先,默认情况下,分词后句子首位会分别加上[CLS]和[SEP]标记,其中[CLS]位置对应的输出向量是能代表整句的句向量(反正Bert是这样设计的),而[SEP]则是句间的分隔符,其余部分则是单字输出(对于中文来说)。
本来Tokenizer有自己的_tokenize方法,我这里重写了这个方法,是要保证tokenize之后的结果,跟原来的字符串长度等长(如果算上两个标记,那么就是等长再加2)。Tokenizer自带的_tokenize会自动去掉空格,然后有些字符会粘在一块输出,导致tokenize之后的列表不等于原来字符串的长度了,这样如果做序列标注的任务会很麻烦。而为了避免这种麻烦,还是自己重写一遍好了~主要就是用[unused1]来表示空格类字符,而其余的不在列表的字符用[UNK]表示,其中[unused*]这些标记是未经训练的(随即初始化),是Bert预留出来用来增量添加词汇的标记,所以我们可以用它们来指代任何新字符。
三个例子 #
这里包含keras-bert的三个例子,分别是文本分类、关系抽取和主体抽取,都是在官方发布的预训练权重基础上进行微调来做的。
Bert官方Github:https://github.com/google-research/bert
官方的中文预训练权重:chinese_L-12_H-768_A-12.zip
例子所在Github:https://github.com/bojone/bert_in_keras/
根据官方介绍,这份权重是用中文维基百科为语料进行训练的。
(2019年6月20日更新:哈工大讯飞联合实验室发布了一版新权重,也可以用keras_bert加载,详情请看这里。)
文本分类 #
作为第一个例子,我们做一个最基本的文本分类任务,熟悉做这个基本任务之后,剩下的各种任务都会变得相当简单了。这次我们以之前已经讨论过多次的文本感情分类任务为例,所用的标注数据也是以前所整理的。
让我们来看看模型部分全貌(完整代码见这里):
# 注意,尽管可以设置seq_len=None,但是仍要保证序列长度不超过512
bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path, seq_len=None)
for l in bert_model.layers:
l.trainable = True
x1_in = Input(shape=(None,))
x2_in = Input(shape=(None,))
x = bert_model([x1_in, x2_in])
x = Lambda(lambda x: x[:, 0])(x) # 取出[CLS]对应的向量用来做分类
p = Dense(1, activation='sigmoid')(x)
model = Model([x1_in, x2_in], p)
model.compile(
loss='binary_crossentropy',
optimizer=Adam(1e-5), # 用足够小的学习率
metrics=['accuracy']
)
model.summary()在Keras中调用Bert来做情感分类任务就这样写完了~写完了~~
是不是感觉还没有尽兴,模型代码就结束了?Keras调用Bert就这么简短。事实上,真正调用Bert的也就只有load_trained_model_from_checkpoint那一行代码,剩下的只是普通的Keras操作(再次感谢CyberZHG大佬)。所以,如果你已经入门了Keras,那么调用Bert是无往不利啊。
如此简单的调用,能达到什么精度?经过5个epoch的fine tune后,验证集的最好准确率是95.5%+!之前我们在《文本情感分类(三):分词 OR 不分词》中死调烂调,也就只有90%上下的准确率;而用了Bert之后,寥寥几行,就提升了5个百分点多的准确率!也难怪Bert能在NLP界掀起一阵热潮...
在这里,用笔者的个人经历先回答读者可能关心的两个问题。
第一个问题应该是大家都很关心的,那就是“要多少显存才够?”。事实上,这没有一个标准答案,显存的使用取决于三个因素:句子长度、batch size、模型复杂度。像上面的情感分析例子,在笔者的GTX1060 6G显存上也能跑起来,只需要将batch size调到24即可。所以,如果你的显存不够大,将句子的maxlen和batch size都调小一点试试。当然,如果你的任务太复杂,再小的maxlen和batch size也可能OOM,那就只有升级显卡了。
第二个问题是“有什么原则来指导Bert后面应该要接哪些层?”。答案是:用尽可能少的层来完成你的任务。比如上述情感分析只是一个二分类任务,你就取出第一个向量然后加个Dense(1)就好了,不要想着多加几层Dense,更加不要想着接个LSTM再接Dense;如果你要做序列标注(比如NER),那你就接个Dense+CRF就好,也不要多加其他东西。总之,额外加的东西尽可能少。一是因为Bert本身就足够复杂,它有足够能力应对你要做的很多任务;二来你自己加的层都是随机初始化的,加太多会对Bert的预训练权重造成剧烈扰动,容易降低效果甚至造成模型不收敛~
关系抽取 #
假如读者已经有了一定的Keras基础,那么经过第一个例子的学习,其实我们应该已经完全掌握了Bert的fine tune了,因为实在是简单到没有什么好讲了。所以,后面两个例子主要是提供一些参考模式,让读者能体会到如何“用尽可能少的层来完成你的任务”。
在第二个例子中,我们介绍基于Bert实现的一个极简的关系抽取模型,其标注原理跟《基于DGCNN和概率图的轻量级信息抽取模型》介绍的一样,但是得益于Bert强大的编码能力,我们所写的部分可以大大简化。在笔者所给出的一种参考实现中,模型部分如下(完整模型见这里):
t = bert_model([t1, t2])
ps1 = Dense(1, activation='sigmoid')(t)
ps2 = Dense(1, activation='sigmoid')(t)
subject_model = Model([t1_in, t2_in], [ps1, ps2]) # 预测subject的模型
k1v = Lambda(seq_gather)([t, k1])
k2v = Lambda(seq_gather)([t, k2])
kv = Average()([k1v, k2v])
t = Add()([t, kv])
po1 = Dense(num_classes, activation='sigmoid')(t)
po2 = Dense(num_classes, activation='sigmoid')(t)
object_model = Model([t1_in, t2_in, k1_in, k2_in], [po1, po2]) # 输入text和subject,预测object及其关系
train_model = Model([t1_in, t2_in, s1_in, s2_in, k1_in, k2_in, o1_in, o2_in],
[ps1, ps2, po1, po2])如果读者已经读过《基于DGCNN和概率图的轻量级信息抽取模型》一文,了解到不用Bert时的模型架构,那么就会理解到上述实现是多么的简介明了。
可以看到,我们引入了Bert作为编码器,然后得到了编码序列$t$,然后直接接两个Dense(1),这就完成了subject的标注模型;接着,我们把传入的s的首尾对应的编码向量拿出来,直接加到编码向量序列$t$中去,然后再接两个Dense(num_classes),就完成object的标注模型(同时标注出了关系)。
这样简单的设计,最终F1能到多少?答案是:线下dev能接近82%,线上我提交过一次,结果是85%+(都是单模型)!相比之下,《基于DGCNN和概率图的轻量级信息抽取模型》中的模型,需要接CNN,需要搞全局特征,需要将s传入到LSTM进行编码,还需要相对位置向量,各种拍脑袋的模块融合在一起,单模型也只比它好一点点(大约82.5%)。要知道,这个基于Bert的简单模型我只写了一个小时就写出来了,而各种技巧和模型融合在一起的DGCNN模型,我前前后后调试了差不多两个月!Bert的强悍之处可见一斑。
(注:这个模型的fine tune最好有8G以上的显存。另外,因为我在比赛即将结束的前几天才接触的Bert,才把这个基于Bert的模型写出来,没有花心思好好调试,所以最终的提交结果并没有包含Bert。)
用Bert做关系抽取的这个例子,跟前面情感分析的简单例子,有一个明显的差别是学习率的变化。
情感分析的例子中,只是用了恒定的学习率($10^{-5}$)训练了几个epoch,效果就还不错了。在关系抽取这个例子中,第一个epoch的学习率慢慢从$0$增加到$5\times 10^{-5}$(这样称为warmup),第二个epoch再从$5\times 10^{-5}$降到$10^{-5}$,总的来说就是先增后减,Bert本身也是用类似的学习率曲线来训练的,这样的训练方式比较稳定,不容易崩溃,而且效果也比较好。
事件主体抽取 #
最后一个例子来自CCKS 2019 面向金融领域的事件主体抽取,这个比赛目前还在进行,不过我也已经没有什么动力和兴趣做下去了,所以放出我现在的模型(准确率为89%+)供大家参考,祝继续参赛的选手取得更好的成绩。
简单介绍一下这个比赛的数据,大概是这样的
输入:“公司A产品出现添加剂,其下属子公司B和公司C遭到了调查”, “产品出现问题”
输出: “公司A”
也就是说,这是个双输入、单输出的模型,输入是一个query和一个事件类型,输出一个实体(有且只有一个,并且是query的一个片段)。其实这个任务可以看成是SQUAD 1.0的简化版,根据这个输出特性,输出应该用指针结构比较好(两个softmax分别预测首尾)。剩下的问题是:双输入怎么搞?
前面两个例子虽然复杂度不同,但它们都是单一输入的,双输入怎么办呢?当然,这里的实体类型只有有限个,直接Embedding也行,只不过我使用一种更能体现Bert的简单粗暴和强悍的方案:直接用连接符将两个输入连接成一个句子,然后就变成单输入了!比如上述示例样本处理成:
输入:“___产品出现问题___公司A产品出现添加剂,其下属子公司B和公司C遭到了调查”
输出: “公司A”
然后就变成了普通的单输入抽取问题了。说到这个,这个模型的代码也就没有什么好说的了,就简单几行(完整代码请看这里):
x = bert_model([x1, x2])
ps1 = Dense(1, use_bias=False)(x)
ps1 = Lambda(lambda x: x[0][..., 0] - (1 - x[1][..., 0]) * 1e10)([ps1, x_mask])
ps2 = Dense(1, use_bias=False)(x)
ps2 = Lambda(lambda x: x[0][..., 0] - (1 - x[1][..., 0]) * 1e10)([ps2, x_mask])
model = Model([x1_in, x2_in], [ps1, ps2])另外加上一些解码的trick,还有模型融合,提交上去,就可以做到89%+了。在看看目前排行榜,发现最好的结果也就是90%多一点点,所以估计大家都差不多是这样做的了...(这个代码重复实验时波动比较大,大家可以多跑几次,取最优结果。)
这个例子主要告诉我们,用Bert实现自己的任务时,最好能整理成单输入的模式,这样一来比较简单,二来也更加高效。
比如做句子相似度模型,输入两个句子,输出一个相似度,有两个可以想到的做法,第一种是两个句子分别过同一个Bert,然后取出各自的[CLS]特征来做分类;第二种就是像上面一样,用个记号把两个句子连接在一起,变成一个句子,然后过一个Bert,然后将输出特征做分类,后者显然会更快一些,而且能够做到特征之间更全面的交互。
文章小结 #
本文介绍了Keras下Bert的基本调用方法,其中主要是提供三个参考例子,供大家逐步熟悉Bert的fine tune步骤和原理。其中有不少是笔者自己闭门造车的经验之谈,如果有所偏颇,还望读者指正。
事实上有了CyberZHG大佬实现的keras-bert,在Keras下使用Bert也就是小菜一碟,大家折腾个半天,也就上手了。最后祝大家用得痛快~
转载到请包括本文地址:https://spaces.ac.cn/archives/6736
更详细的转载事宜请参考:《科学空间FAQ》
如果您还有什么疑惑或建议,欢迎在下方评论区继续讨论。
如果您觉得本文还不错,欢迎分享/打赏本文。打赏并非要从中获得收益,而是希望知道科学空间获得了多少读者的真心关注。当然,如果你无视它,也不会影响你的阅读。再次表示欢迎和感谢!


如果您需要引用本文,请参考:
苏剑林. (Jun. 18, 2019). 《当Bert遇上Keras:这可能是Bert最简单的打开姿势 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6736
@online{kexuefm-6736,
title={当Bert遇上Keras:这可能是Bert最简单的打开姿势},
author={苏剑林},
year={2019},
month={Jun},
url={\url{https://spaces.ac.cn/archives/6736}},
}

July 11th, 2020
新手想问一句,如果我想使用其他数据集(有句子,以及每一句的标签)复现您的文本分类代码,x1_in和x2_in分别应该是什么呢?
新手请先系统学习BERT的相关内容,以及逐行运行、理解参考代码。
keras-bert和bert4keras的目的是帮助在keras中加载bert模型,以及提供一些相应的demo,并不是入门培训班。
好的。国内的大佬脾气就是重,新手问个问题有用的话一句不回复,我不是这个方向的,我是搞强化学习的,现在只是有个任务需要借用这个模型一下,你给我扣个培训班的帽子就让我滚蛋。因为是大佬所以能随便怼人,有点封建余孽那味儿了。
1、大佬不敢当,更加没资格代表国内。脾气可能不是很好,但很明显,我没有任何不尊重新手的意思,而且我说的是事实。
2、最有用的话就是“逐行运行、理解参考代码”,只要你观察过,知道它们的含义,就不会有这个问题,因为这个太基础了。而既然你坚持要问这个问题,我只能当你想找人手把手教学,所以这不是培训班是什么?
3、既然你问到的是NLP问题,或者是说BERT的问题,那自然就要按照NLP、BERT的学习流程来进行,你原来是搞什么的,我想每一个被提问到的人都不会关心。而既然你想用到BERT模型,我认为至少对BERT的一些基本常识要了解,这不是一句“我不是搞NLP的”就可以略过的。
好的,原来是我的问题太基础,那么问题还是在我这儿,谢谢指出。如果大佬一开始就这么说就好了。
August 10th, 2020
非常感谢
September 6th, 2020
苏神,加了[unused1]应该会影响embedding的结果吧?没有其他解决方案了吗?
理论上不会。
September 22nd, 2020
能了解一下怎么设置[unused*]字符吗,直接改dict path好像不行?
什么叫做“设置[unused*]字符”?能先下个定义吗?
September 24th, 2020
苏神,在关系抽取那个模型中,看到直接将预训练模型的权重设置为可训练:
for l in bert_model.layers: l.trainable = True然后看到keras文档中提到:
It is critical to only do this step after the model with frozen layers has been trained to convergence. If you mix randomly-initialized trainable layers with trainable layers that hold pre-trained features, the randomly-initialized layers will cause very large gradient updates during training, which will destroy your pre-trained features.
是不是应该先用预训练模型的固定权重参数训练出一个收敛之后的模型然后再考虑将预训练模型的权重设为可训练的比较好?
请问为什么我一定要按照keras文档提到的做法去做呢?
September 25th, 2020
苏老师您好,想请教一下您这个问题。我在运行keras-bert时一直出现这个错误,请问是预训练模型出问题了么?我在网上搜索了好久都没找到相应的答案,所以想麻烦一下您。谢谢!
Traceback (most recent call last):
File "G:/PycharmProjects/bert/bert-keras.py", line 15, in
model = load_trained_model_from_checkpoint(paths.config, paths.checkpoint, training=True, seq_len=None)
File "G:\Anaconda3\envs\bert\lib\site-packages\keras_bert\loader.py", line 169, in load_trained_model_from_checkpoint
**kwargs)
File "G:\Anaconda3\envs\bert\lib\site-packages\keras_bert\loader.py", line 58, in build_model_from_config
**kwargs)
File "G:\Anaconda3\envs\bert\lib\site-packages\keras_bert\bert.py", line 84, in get_model
dropout_rate=dropout_rate,
File "G:\Anaconda3\envs\bert\lib\site-packages\keras_bert\layers\embedding.py", line 37, in get_embedding
)(inputs[0]),
File "G:\Anaconda3\envs\bert\lib\site-packages\keras\backend\tensorflow_backend.py", line 75, in symbolic_fn_wrapper
return func(*args, **kwargs)
File "G:\Anaconda3\envs\bert\lib\site-packages\keras\engine\base_layer.py", line 529, in __call__
arguments=user_kwargs)
File "G:\Anaconda3\envs\bert\lib\site-packages\keras\engine\base_layer.py", line 597, in _add_inbound_node
output_tensors[i]._keras_shape = output_shapes[i]
IndexError: list index out of range
不知道。
苏老师按照您的经验可能是哪里出了问题?学生想参考一下您的宝贵经验。
keras版本不对吧。
我看了一下keras版本和他要求的一样的...哎或者我再自己排查一下吧...谢谢苏老师您了
控制变量法检查呗 不是py的问题就是keras的问题再不就是tensorflow的问题 其实直接在linux下花上半天到一天的时间统一下环境就好了
October 24th, 2020
感谢苏老师的分享和各种教程,真的学到很多。从此有个梦想,成为苏老师这样的大神!!!
有个问题像请教一下苏老师:
在预训练的时候,并没有加入validation的操作,是没有必要?还是其他的什么原因?
期待您的回复谢谢
# 模型训练
train_model.fit(
dataset,
steps_per_epoch=steps_per_epoch,
epochs=epochs,
callbacks=[checkpoint, csv_logger],
)
预训练没有什么必要。
那不就不知道 预训练过程有没有学到东西吗?
比如,没有validation的loss曲线就没办法判断过拟合了,或者别的一些问题。
因为是这样的,我用比较少的数据训练robert的时候,mlm_acc达到了0.9以上,但是fintune做分类的时候,正确率一直是0.02左右。然后我用没有预训练的robert模型直接进行分类,就可以达到不错的效果。
才疏学浅,可能问题比较呆萌,还请苏老师见谅
......
预训练本身就是希望通过大量语料的预训练,提前把尽可能多的句子都学过了。因为足够多,加上神经网络的泛化能力,可以认为几乎一切句子都遇到过,甚至包括你接下来要做的任务的验证集和测试集,虽然任务只是无监督的,但特征是通用的,因此最终提升了很多下游任务的性能。
所以,预训练默认的就是大语料,没有几十G好歹也应该有几G吧。难道你几M的语料也想做预训练吗?图啥呢?
数据部分是其他小伙伴在做, 最后的大语料还没有处理好,所以我先拿一小部分数据尝试了一下预训练,所以出现了这个问题。
谢谢苏老师的指导,接下来我会用大量预料尝试一下
December 31st, 2020
x = Lambda(lambda x: x[:, 0])(x),您好,这个地方是拿到CLS的embedding,bert的输出是(batch_size, seq_len, embedding_dim)。Lambda括号中的x的形状是(seq_len, embedding_dim)CLS是第一个字符,不应该是x[0, :]吗? 为什么是 x[:, 0]呢?
x.shape = [batch_size, seq_len, hidden_size]
January 26th, 2021
终于到bert了 打个卡^-^
February 24th, 2021
“tokenize之后的列表不等于原来字符串的长度”这个问题在博主的bert4keras中没有实现吧?
没有。后来发现这个需求是个不成立的需求(不需要它也能做,加上它反而损害模型效果)。
不需要它怎么做呢?我用keras4bert的tokenizer测试的tokenize之后的列表不等于原来字符串的长度,比如文本中含有“1.23%”类似字符
不等于就不等于地做,这是很简单的事情,以前还是用分词后的结果来做呢,难道以前就做不了中文了吗?
实在不行的话,你就想象着要是做不出来会要命的,那肯定就能逼自己想到了~
博主还是有很多粉丝的,大家会学习、借鉴博主的代码等,如果“加上它反而损害模型效果”,还是请博主说明一下,不然很多人还跟着这篇博文做
预训练怎么做,下游任务应尽量对齐做法,这是适用于训练模型的一个原则。既然预训练任务不是直接切分为字的,那么下游任务也不应该切分为字。
至于所谓的“不等于怎么做”的问题,因为没有哪条法律规定必须要等于,所以我们可以修改人工标注结果,使得它跟tokenize之后的结果对应,而不是跟字一一对应。早期我们以词为单位做序列标注,同样也是这样做的。
至于这篇文章本身,属于历史遗留问题,不属于什么大错误,因此就保留着原样(总不能我每次更新都得把所有历史文章都更新一遍吧?)。而不切分为字的序列标注做法,我的bert4keras中已经给出了例子了(分词和NER都有)。
感谢博主