






9
Mar
训练1000层的Transformer究竟有什么困难?
By 苏剑林 | 2022-03-09 | 135072位读者 | 引用众所周知,现在的Transformer越做越大,但这个“大”通常是“宽”而不是“深”,像GPT-3虽然参数有上千亿,但也只是一个96层的Transformer模型,与我们能想象的深度相差甚远。是什么限制了Transformer往“深”发展呢?可能有的读者认为是算力,但“宽而浅”的模型所需的算力不会比“窄而深”的模型少多少,所以算力并非主要限制,归根结底还是Transformer固有的训练困难。一般的观点是,深模型的训练困难源于梯度消失或者梯度爆炸,然而实践显示,哪怕通过各种手段改良了梯度,深模型依然不容易训练。
近来的一些工作(如Admin)指出,深模型训练的根本困难在于“增量爆炸”,即模型越深对输出的扰动就越大。上周的论文《DeepNet: Scaling Transformers to 1,000 Layers》则沿着这个思路进行尺度分析,根据分析结果调整了模型的归一化和初始化方案,最终成功训练出了1000层的Transformer模型。整个分析过程颇有参考价值,我们不妨来学习一下。
增量爆炸
原论文的完整分析比较长,而且有些假设或者描述细酌之下是不够合理的。所以在本文的分享中,笔者会尽量修正这些问题,试图以一个更合理的方式来得到类似结果。
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 297953位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
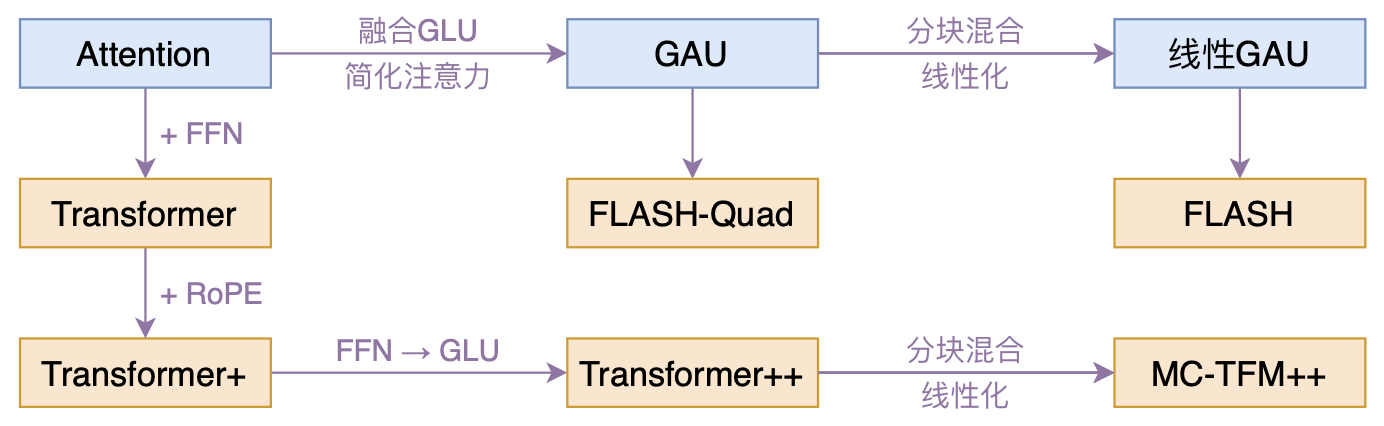
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
21
Dec
从熵不变性看Attention的Scale操作
By 苏剑林 | 2021-12-21 | 207288位读者 | 引用当前Transformer架构用的最多的注意力机制,全称为“Scaled Dot-Product Attention”,其中“Scaled”是因为在$Q,K$转置相乘之后还要除以一个$\sqrt{d}$再做Softmax(下面均不失一般性地假设$Q,K,V\in\mathbb{R}^{n\times d}$):
\begin{equation}Attention(Q,K,V) = softmax\left(\frac{QK^{\top}}{\sqrt{d}}\right)V\label{eq:std}\end{equation}
在《浅谈Transformer的初始化、参数化与标准化》中,我们已经初步解释了除以$\sqrt{d}$的缘由。而在这篇文章中,笔者将从“熵不变性”的角度来理解这个缩放操作,并且得到一个新的缩放因子。在MLM的实验显示,新的缩放因子具有更好的长度外推性能。
熵不变性
我们将一般的Scaled Dot-Product Attention改写成
\begin{equation}\boldsymbol{o}_i = \sum_{j=1}^n a_{i,j}\boldsymbol{v}_j,\quad a_{i,j}=\frac{e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_{j=1}^n e^{\lambda \boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
其中$\lambda$是缩放因子,它跟$\boldsymbol{q}_i,\boldsymbol{k}_j$无关,但原则上可以跟长度$n$、维度$d$等参数有关,目前主流的就是$\lambda=1/\sqrt{d}$。
17
Aug
浅谈Transformer的初始化、参数化与标准化
By 苏剑林 | 2021-08-17 | 288155位读者 | 引用前几天在训练一个新的Transformer模型的时候,发现怎么训都不收敛了。经过一番debug,发现是在做Self Attention的时候$\boldsymbol{Q}\boldsymbol{K}^{\top}$之后忘记除以$\sqrt{d}$了,于是重新温习了一下为什么除以$\sqrt{d}$如此重要的原因。当然,Google的T5确实是没有除以$\sqrt{d}$的,但它依然能够正常收敛,那是因为它在初始化策略上做了些调整,所以这个事情还跟初始化有关。
藉着这个机会,本文跟大家一起梳理一下模型的初始化、参数化和标准化等内容,相关讨论将主要以Transformer为心中展开。
采样分布
初始化自然是随机采样的的,所以这里先介绍一下常用的采样分布。一般情况下,我们都是从指定均值和方差的随机分布中进行采样来初始化。其中常用的随机分布有三个:正态分布(Normal)、均匀分布(Uniform)和截尾正态分布(Truncated Normal)。
9
Aug
线性Transformer应该不是你要等的那个模型
By 苏剑林 | 2021-08-09 | 166007位读者 | 引用在本博客中,我们已经多次讨论过线性Attention的相关内容。介绍线性Attention的逻辑大体上都是:标准Attention具有$\mathcal{O}(n^2)$的平方复杂度,是其主要的“硬伤”之一,于是我们$\mathcal{O}(n)$复杂度的改进模型,也就是线性Attention。有些读者看到线性Attention的介绍后,就一直很期待我们发布基于线性Attention的预训练模型,以缓解他们被BERT的算力消耗所折腾的“死去活来”之苦。
然而,本文要说的是:抱有这种念头的读者可能要失望了,标准Attention到线性Attention的转换应该远远达不到你的预期,而BERT那么慢的原因也并不是因为标准Attention的平方复杂度。
BERT之反思
按照直观理解,平方复杂度换成线性复杂度不应该要“突飞猛进”才对嘛?怎么反而“远远达不到预期”?出现这个疑惑的主要原因,是我们一直以来都没有仔细评估一下常规的Transformer模型(如BERT)的整体计算量。
6
Aug
Transformer升级之路:5、作为无限维的线性Attention
By 苏剑林 | 2021-08-06 | 37866位读者 | 引用在《Performer:用随机投影将Attention的复杂度线性化》中我们了解到Google提出的Performer模型,它提出了一种随机投影方案,可以将标准Attention转化为线性Attention,并保持一定的近似。理论上来说,只要投影的维度足够大,那么可以足够近似标准Attention。换句话说,标准Attention可以视作一个无限维的线性Attention。
本文将介绍笔者构思的另外两种将标准Attention转换为无限维线性Attention的思路,不同于Performer的随机投影,笔者构思的这两种方案都是确定性的,并且能比较方便地感知近似程度。
简要介绍
关于标准Attention和线性Attention,这里就不多做介绍了,还不了解的读者可以参考笔者之前的文章《线性Attention的探索:Attention必须有个Softmax吗?》和《Transformer升级之路:3、从Performer到线性Attention》。简单来说,标准Attention的计算方式为
\begin{equation}a_{i,j}=\frac{e^{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}}{\sum\limits_j e^{\boldsymbol{q}_i\cdot \boldsymbol{k}_j}}\end{equation}
29
Jun
UniVAE:基于Transformer的单模型、多尺度的VAE模型
By 苏剑林 | 2021-06-29 | 109026位读者 | 引用
2
Jun
我们可以无损放大一个Transformer模型吗(一)
By 苏剑林 | 2021-06-02 | 88355位读者 | 引用看了标题,可能读者会有疑惑,大家不都想着将大模型缩小吗?怎么你想着将小模型放大了?其实背景是这样的:通常来说更大的模型加更多的数据确实能起得更好的效果,然而算力有限的情况下,从零预训练一个大的模型时间成本太大了,如果还要调试几次参数,那么可能几个月就过去了。
这时候“穷人思维”就冒出来了(土豪可以无视):能否先训练一个同样层数的小模型,然后放大后继续训练?这样一来,预训练后的小模型权重经过放大后,就是大模型一个起点很高的初始化权重,那么大模型阶段的训练步数就可以减少了,从而缩短整体的训练时间。
那么,小模型可以无损地放大为一个大模型吗?本文就来从理论上分析这个问题。
含义
有的读者可能想到:这肯定可以呀,大模型的拟合能力肯定大于小模型呀。的确,从拟合能力角度来看,这件事肯定是可以办到的,但这还不是本文关心的“无损放大”的全部。

最近评论