






12
Dec
注意力机制真的可以“集中注意力”吗?
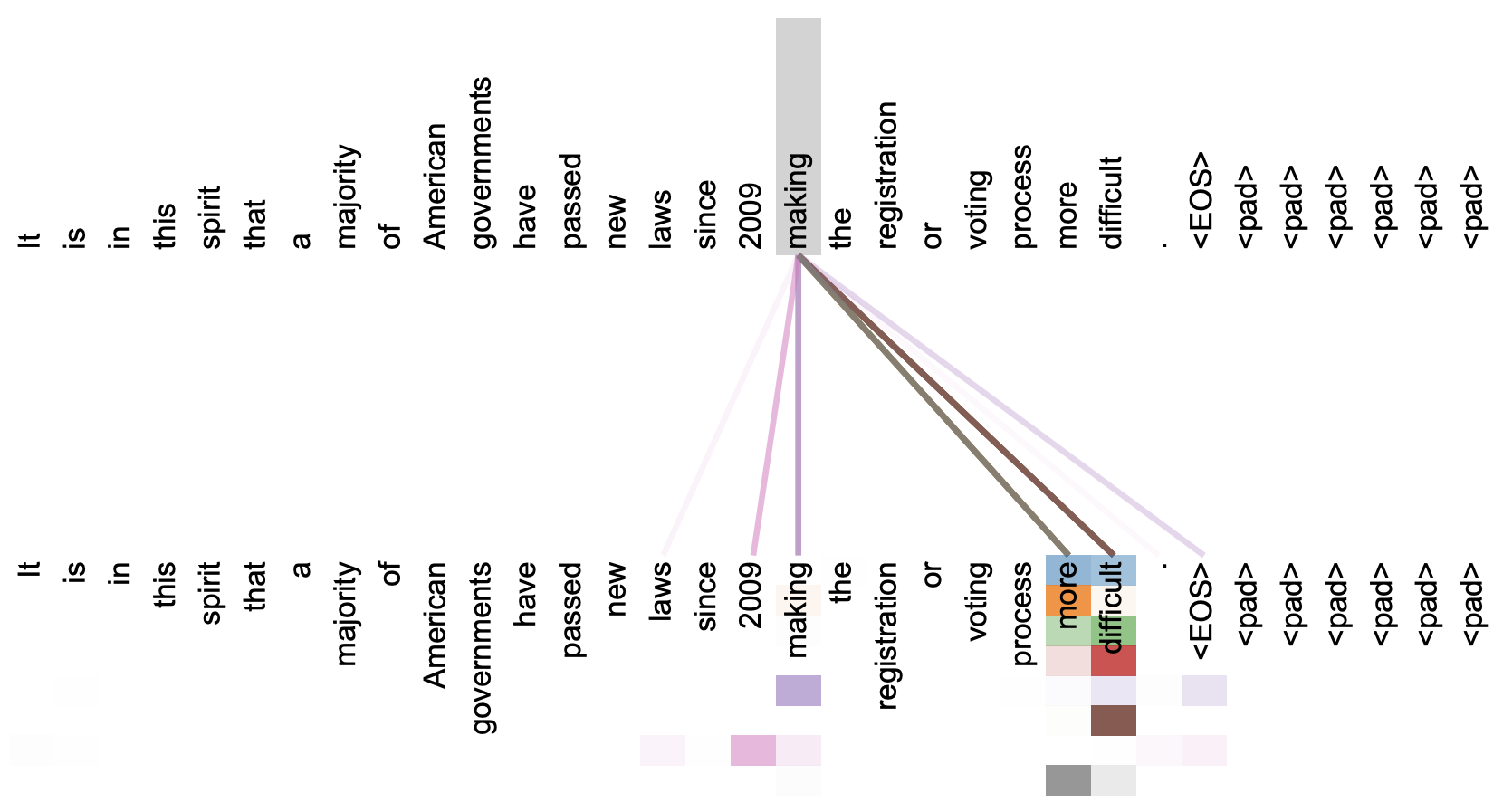
By 苏剑林 | 2023-12-12 | 43706位读者 | 引用之前在《Transformer升级之路:3、从Performer到线性Attention》、《为什么现在的LLM都是Decoder-only的架构?》等文章中,我们从Attention矩阵的“秩”的角度探讨了Attention机制,并曾经判断线性Attention不如标准Attention的关键原因正是“低秩瓶颈”。然而,这一解释对于双向的Encoder模型或许成立,但却难以适用于单向的Decoder模型,因为Decoder的Attention矩阵的上三角部分是被mask掉的,留下的下三角矩阵必然是满秩的,而既然都是满秩了,那么低秩瓶颈问题似乎就不复存在了。
所以,“低秩瓶颈”并不能完全解释线性Attention的能力缺陷。在这篇文章中,笔者试图寻求另一个角度的解释。简单来说,与标准Attention相比,线性Attention更难“集中注意力”,从而难以准确地定位到关键token,这大概是它效果稍逊一筹的主要原因。
25
May
Google新作Synthesizer:我们还不够了解自注意力
By 苏剑林 | 2020-05-25 | 88153位读者 | 引用深度学习这个箱子,远比我们想象的要黑。
写在开头
据说物理学家费曼说过一句话[来源]:“谁要是说他懂得量子力学,那他就是真的不懂量子力学。”我现在越来越觉得,这句话中的“量子力学”也可以替换为“深度学习”。尽管深度学习已经在越来越多的领域证明了其有效性,但我们对它的解释性依然相当无力。当然,这几年来已经有不少工作致力于打开深度学习这个黑箱,但是很无奈,这些工作基本都是“马后炮”式的,也就是在已有的实验结果基础上提出一些勉强能说服自己的解释,无法做到自上而下的构建和理解模型的原理,更不用说提出一些前瞻性的预测。
本文关注的是自注意力机制。直观上来看,自注意力机制算是解释性比较强的模型之一了,它通过自己与自己的Attention来自动捕捉了token与token之间的关联,事实上在《Attention is All You Need》那篇论文中,就给出了如下的看上去挺合理的可视化效果:
《Attention is All You Need》一文中对Attention的可视化例子
但自注意力机制真的是这样生效的吗?这种“token对token”的注意力是必须的吗?前不久Google的新论文《Synthesizer: Rethinking Self-Attention in Transformer Models》对自注意力机制做了一些“异想天开”的探索,里边的结果也许会颠覆我们对自注意力的认知。
12
Jan
Transformer升级之路:7、长度外推性与局部注意力
By 苏剑林 | 2023-01-12 | 86469位读者 | 引用对于Transformer模型来说,其长度的外推性是我们一直在追求的良好性质,它是指我们在短序列上训练的模型,能否不用微调地用到长序列上并依然保持不错的效果。之所以追求长度外推性,一方面是理论的完备性,觉得这是一个理想模型应当具备的性质,另一方面也是训练的实用性,允许我们以较低成本(在较短序列上)训练出一个长序列可用的模型。
下面我们来分析一下加强Transformer长度外推性的关键思路,并由此给出一个“超强基线”方案,然后我们带着这个“超强基线”来分析一些相关的研究工作。
思维误区
第一篇明确研究Transformer长度外推性的工作应该是ALIBI,出自2021年中期,距今也不算太久。为什么这么晚(相比Transformer首次发表的2017年)才有人专门做这个课题呢?估计是因为我们长期以来,都想当然地认为Transformer的长度外推性是位置编码的问题,找到更好的位置编码就行了。
25
Apr
注意力和Softmax的两点有趣发现:鲁棒性和信息量
By 苏剑林 | 2023-04-25 | 29016位读者 | 引用最近几周笔者一直都在思考注意力机制的相关性质,在这个过程中对注意力及Softmax有了更深刻的理解。在这篇文章中,笔者简单分享其中的两点:
1、Softmax注意力天然能够抵御一定的噪声扰动;
2、从信息熵角度也可以对初始化问题形成直观理解。
鲁棒性
基于Softmax归一化的注意力机制,可以写为
\begin{equation}o = \frac{\sum\limits_{i=1}^n e^{s_i} v_i}{\sum\limits_{i=1}^n e^{s_i}}\end{equation}
有一天笔者突然想到一个问题:如果往$s_i$中加入独立同分布的噪声会怎样?
6
Jan
《Attention is All You Need》浅读(简介+代码)
By 苏剑林 | 2018-01-06 | 867151位读者 | 引用2017年中,有两篇类似同时也是笔者非常欣赏的论文,分别是FaceBook的《Convolutional Sequence to Sequence Learning》和Google的《Attention is All You Need》,它们都算是Seq2Seq上的创新,本质上来说,都是抛弃了RNN结构来做Seq2Seq任务。
这篇博文中,笔者对《Attention is All You Need》做一点简单的分析。当然,这两篇论文本身就比较火,因此网上已经有很多解读了(不过很多解读都是直接翻译论文的,鲜有自己的理解),因此这里尽可能多自己的文字,尽量不重复网上各位大佬已经说过的内容。
序列编码
深度学习做NLP的方法,基本上都是先将句子分词,然后每个词转化为对应的词向量序列。这样一来,每个句子都对应的是一个矩阵$\boldsymbol{X}=(\boldsymbol{x}_1,\boldsymbol{x}_2,\dots,\boldsymbol{x}_t)$,其中$\boldsymbol{x}_i$都代表着第$i$个词的词向量(行向量),维度为$d$维,故$\boldsymbol{X}\in \mathbb{R}^{n\times d}$。这样的话,问题就变成了编码这些序列了。
第一个基本的思路是RNN层,RNN的方案很简单,递归式进行:
\begin{equation}\boldsymbol{y}_t = f(\boldsymbol{y}_{t-1},\boldsymbol{x}_t)\end{equation}
不管是已经被广泛使用的LSTM、GRU还是最近的SRU,都并未脱离这个递归框架。RNN结构本身比较简单,也很适合序列建模,但RNN的明显缺点之一就是无法并行,因此速度较慢,这是递归的天然缺陷。另外我个人觉得RNN无法很好地学习到全局的结构信息,因为它本质是一个马尔科夫决策过程。
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 130403位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
22
Apr
Transformer升级之路:3、从Performer到线性Attention
By 苏剑林 | 2021-04-22 | 54334位读者 | 引用看过笔者之前的文章《线性Attention的探索:Attention必须有个Softmax吗?》和《Performer:用随机投影将Attention的复杂度线性化》的读者,可能会觉得本文的标题有点不自然,因为是先有线性Attention然后才有Performer的,它们的关系为“Performer是线性Attention的一种实现,在保证线性复杂度的同时保持了对标准Attention的近似”,所以正常来说是“从线性Attention到Performer”才对。
然而,本文并不是打算梳理线性Attention的发展史,而是打算反过来思考Performer给线性Attention所带来的启示,所以是“从Performer到线性Attention”。
激活函数
线性Attention的常见形式是
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V})_i = \frac{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j)} = \frac{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)\boldsymbol{v}_j}{\sum\limits_{j=1}^n \phi(\boldsymbol{q}_i)^{\top} \varphi(\boldsymbol{k}_j)}\end{equation}
27
Sep
关于维度公式“n > 8.33 log N”的可用性分析
By 苏剑林 | 2021-09-27 | 39404位读者 | 引用在之前的文章《最小熵原理(六):词向量的维度应该怎么选择?》中,我们基于最小熵思想推导出了一个词向量维度公式“$n > 8.33\log N$”,然后在《让人惊叹的Johnson-Lindenstrauss引理:应用篇》中我们进一步指出,该结果与JL引理所给出的$\mathcal{O}(\log N)$是吻合的。
既然理论上看上去很完美,那么自然就有读者发问了:实验结果如何呢?8.33这个系数是最优的吗?本文就对此问题的相关内容做一个简单汇总。
词向量
首先,我们可以直接,当$N$为10万时,$8.33\log N\approx 96$,当$N$为500万时,$8.33\log N\approx 128$。这说明,至少在数量级上,该公式给出的结果是很符合我们实际所用维度的,因为在词向量时代,我们自行训练的词向量维度也就是100维左右。可能有读者会质疑,目前开源的词向量多数是300维的,像BERT的Embedding层都达到了768维,这不是明显偏离了你的结果了?

最近评论