






21
Dec
从动力学角度看优化算法(七):SGD ≈ SVM?
By 苏剑林 | 2020-12-21 | 37035位读者 | 引用众所周知,在深度学习之前,机器学习是SVM(Support Vector Machine,支持向量机)的天下,曾经的它可谓红遍机器学习的大江南北,迷倒万千研究人员,直至今日,“手撕SVM”仍然是大厂流行的面试题之一。然而,时过境迁,当深度学习流行起来之后,第一个革的就是SVM的命,现在只有在某些特别追求效率的场景以及大厂的面试题里边,才能看到SVM的踪迹了。
峰回路转的是,最近Arxiv上的一篇论文《Every Model Learned by Gradient Descent Is Approximately a Kernel Machine》做了一个非常“霸气”的宣言:
任何由梯度下降算法学出来的模型,都是可以近似看成是一个SVM!
这结论真不可谓不“霸气”,因为它已经不只是针对深度学习了,而是只要你用梯度下降优化的,都不过是一个SVM(的近似)。笔者看了一下原论文的分析,感觉确实挺有意思也挺合理的,有助于加深我们对很多模型的理解,遂跟大家分享一下。
24
May
It is time.
By 苏剑林 | 2015-05-24 | 55428位读者 | 引用终于可以缓一缓了~~
有留意科学空间的朋友可能发现这段时间更新比较缓慢,这一切还得从今年寒假说起...
今年一月底,由于各种原因,结合自己的兴趣,我找了一份实习工作,内容是Python编程。工作是在华南理工大学的论坛上发布的,说的比较简洁,我也比较简洁地投了简历过去,想不到收到回复了,也被录用了。二月上班,进去之后,才发现原来公司还是一家国内比较知名的电商企业,我的主要工作是数据挖掘...虽然我有一点Python的经验,但是数据挖掘基本上不在行的,所以只能够边工作边学习,疯狂恶补数据挖掘的知识。在这个过程中,我学会了很多关于数据挖掘的东西,要知道,在这之前,我不知道什么叫“特征”,什么是“逻辑回归”、“SVM”...那时候真是万千无知。
15
Jul
漫话模型|模型与选芒果
By 苏剑林 | 2015-07-15 | 38653位读者 | 引用很多人觉得“模型”、“大数据”、“机器学习”这些字眼很高大很神秘,事实上,它跟我们生活中选水果差不了多少。本文用了几千字,来试图教会大家怎么选芒果...
模型的比喻

芒果
假如我要从一批芒果中,找出好吃的那个来。而我不能直接切开芒果尝尝,所以我只能观察芒果,能观察到的量有颜色、表面的气味、大小等等,这些就是我们能够收集到的信息(特征)。
生活中还要很多这样的例子,比如买火柴(可能年轻的城里人还没见过火柴?),如何判断一盒火柴的质量?难道要每根火柴都划划,看看着不着火?显然不行,我们最多也只能划几根,全部划了,火柴也不成火柴了。当然,我们还能看看火柴的样子,闻闻火柴的气味,这些动作是可以接受的。
6
Dec
人生苦短,我用Python!
By 苏剑林 | 2015-12-06 | 57642位读者 | 引用
1
Jul
从Boosting学习到神经网络:看山是山?
By 苏剑林 | 2016-07-01 | 66348位读者 | 引用前段时间在潮州给韩师的同学讲文本挖掘之余,涉猎到了Boosting学习算法,并且做了一番头脑风暴,最后把Boosting学习算法的一些本质特征思考清楚了,而且得到一些意外的结果,比如说AdaBoost算法的一些理论证明也可以用来解释神经网络模型这么强大。
AdaBoost算法
Boosting学习,属于组合模型的范畴,当然,与其说它是一个算法,倒不如说是一种解决问题的思路。以有监督的分类问题为例,它说的是可以把弱的分类器(只要准确率严格大于随机分类器)通过某种方式组合起来,就可以得到一个很优秀的分类器(理论上准确率可以100%)。AdaBoost算法是Boosting算法的一个例子,由Schapire在1996年提出,它构造了一种Boosting学习的明确的方案,并且从理论上给出了关于错误率的证明。
以二分类问题为例子,假设我们有一批样本$\{x_i,y_i\},i=1,2,\dots,n$,其中$x_i$是样本数据,有可能是多维度的输入,$y_i\in\{1,-1\}$为样本标签,这里用1和-1来描述样本标签而不是之前惯用的1和0,只是为了后面证明上的方便,没有什么特殊的含义。接着假设我们已经有了一个弱分类器$G(x)$,比如逻辑回归、SVM、决策树等,对分类器的唯一要求是它的准确率要严格大于随机(在二分类问题中就是要严格大于0.5),所谓严格大于,就是存在一个大于0的常数$\epsilon$,每次的准确率都不低于$\frac{1}{2}+\epsilon$。
30
Mar
文本情感分类(四):更好的损失函数
By 苏剑林 | 2017-03-30 | 124310位读者 | 引用文本情感分类其实就是一个二分类问题,事实上,对于分类模型,都会存在这样一个毛病:优化目标跟考核指标不一致。通常来说,对于分类(包括多分类),我们都会采用交叉熵作为损失函数,它的来源就是最大似然估计(参考《梯度下降和EM算法:系出同源,一脉相承》)。但是,我们最后的评估目标,并非要看交叉熵有多小,而是看模型的准确率。一般来说,交叉熵很小,准确率也会很高,但这个关系并非必然的。
要平均,不一定要拔尖
一个更通俗的例子是:一个数学老师,在努力提高同学们的平均分,但期末考核的指标却是及格率(60分及格)。假如平均分是100分(也就意味着所有同学都考到了100分),那么自然及格率是100%,这是最理想的。但现实不一定这么美好,平均分越高,只要平均分还没有达到100,那么及格率却不一定越高,比如两个人分别考40和90,那么平均分就是65,及格率只有50%;如果两个人的成绩都是60,平均分就是60,及格率却有100%。这也就是说,平均分可以作为一个目标,但这个目标并不直接跟考核目标挂钩。
那么,为了提升最后的考核目标,这个老师应该怎么做呢?很显然,首先看看所有学生中,哪些同学已经及格了,及格的同学先不管他们,而针对不及格的同学进行补课加强,这样一来,原则上来说有很多不及格的同学都能考上60分了,也有可能一些本来及格的同学考不够60分了,但这个过程可以迭代,最终使得大家都在60分以上,当然,最终的平均分不一定很高,但没办法,谁叫考核目标是及格率呢?
16
Feb
Nyströmformer:基于矩阵分解的线性化Attention方案
By 苏剑林 | 2021-02-16 | 46072位读者 | 引用标准Attention的$\mathcal{O}(n^2)$复杂度可真是让研究人员头大。前段时间我们在博文《Performer:用随机投影将Attention的复杂度线性化》中介绍了Google的Performer模型,它通过随机投影的方式将标准Attention转化为线性Attention。无独有偶,前些天Arxiv上放出了AAAI 2021的一篇论文《Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention》,里边又提出了一种从另一个角度把标准Attention线性化的方案。
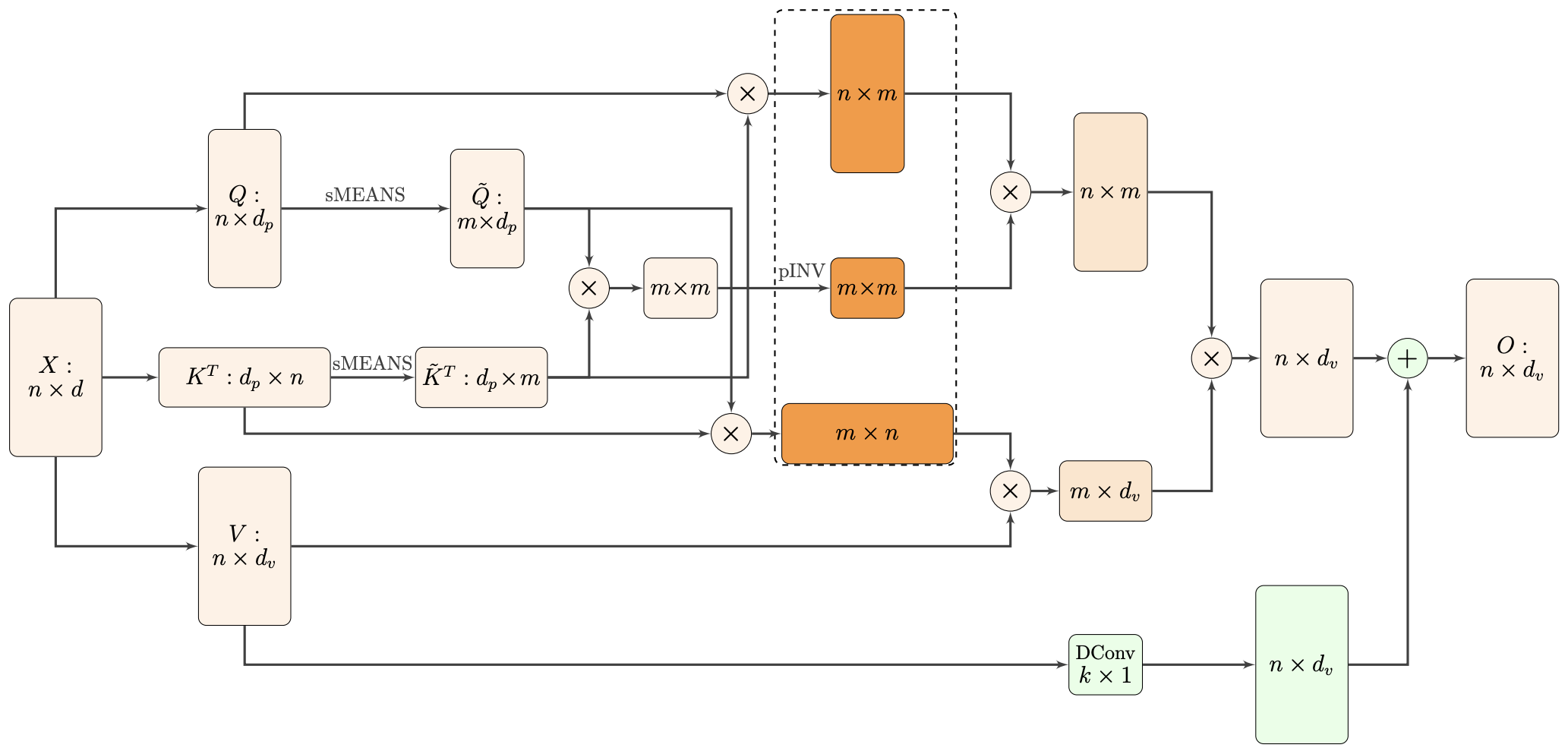
Nyströmformer结构示意图
该方案写的是Nyström-Based,顾名思义是利用了Nyström方法来近似标准Attention的。但是坦白说,在看到这篇论文之前,笔者也完全没听说过Nyström方法,而纵观整篇论文,里边也全是笔者一眼看上去感觉很茫然的矩阵分解推导,理解起来颇为困难。不过有趣的是,尽管作者的推导很复杂,但笔者发现最终的结果可以通过一个相对来说更简明的方式来理解,遂将笔者对Nyströmformer的理解整理在此,供大家参考。
22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 66659位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。

最近评论