






19
Nov
更别致的词向量模型(三):描述相关的模型
By 苏剑林 | 2017-11-19 | 121048位读者 | 引用几何词向量
上述“月老”之云虽说只是幻想,但所面临的问题却是真实的。按照传统NLP的手段,我们可以统计任意两个词的共现频率以及每个词自身的频率,然后去算它们的相关度,从而得到一个“相关度矩阵”。然而正如前面所说,这个共现矩阵太庞大了,必须压缩降维,同时还要做数据平滑,给未出现的词对的相关度赋予一个合理的估值。
在已有的机器学习方案中,我们已经有一些对庞大的矩阵降维的经验了,比如SVD和pLSA,SVD是对任意矩阵的降维,而pLSA是对转移概率矩阵$P(j|i)$的降维,两者的思想是类似的,都是将一个大矩阵$\boldsymbol{A}$分解为两个小矩阵的乘积$\boldsymbol{A}\approx\boldsymbol{B}\boldsymbol{C}$,其中$\boldsymbol{B}$的行数等于$\boldsymbol{A}$的行数,$\boldsymbol{C}$的列数等于$\boldsymbol{A}$的列数,而它们本身的大小则远小于$\boldsymbol{A}$的大小。如果对$\boldsymbol{B},\boldsymbol{C}$不做约束,那么就是SVD;如果对$\boldsymbol{B},\boldsymbol{C}$做正定归一化约束,那就是pLSA。
但是如果是相关度矩阵,那么情况不大一样,它是正定的但不是归一的,我们需要为它设计一个新的压缩方案。借鉴矩阵分解的经验,我们可以设想把所有的词都放在$n$维空间中,也就是用$n$维空间中的一个向量来表示,并假设它们的相关度就是内积的某个函数(为什么是内积?因为矩阵乘法本身就是不断地做内积):
\[\frac{P(w_i,w_j)}{P(w_i)P(w_j)}=f\big(\langle \boldsymbol{v}_i, \boldsymbol{v}_j\rangle\big)\tag{8}\]
其中加粗的$\boldsymbol{v}_i, \boldsymbol{v}_j$表示词$w_i,w_j$对应的词向量。从几何的角度看,我们就是把词语放置到了$n$维空间中,用空间中的点来表示一个词。
因为几何给我们的感觉是直观的,而语义给我们的感觉是复杂的,因此,理想情况下我们希望能够通过几何关系来反映语义关系。下面我们就根据我们所希望的几何特性,来确定待定的函数$f$。事实上,glove词向量的那篇论文中做过类似的事情,很有启发性,但glove的推导实在是不怎么好看。请留意,这里的观点是新颖的——从我们希望的性质,来确定我们的模型,而不是反过来有了模型再推导性质。
机场-飞机+火车=火车站
7
Jul
从SamplePairing到mixup:神奇的正则项
By 苏剑林 | 2018-07-07 | 80650位读者 | 引用SamplePairing和mixup是两种一脉相承的图像数据扩增手段,它们看起来很不合理,而操作则非常简单,但结果却非常漂亮:在多个图像分类任务中都表明它们能提高最终分类模型的精度。
某些读者会困惑于一个问题:为什么如此不合理的数据扩增手段,能得到如此好的效果?而本文则要表明,它们看起来是一种数据扩增方法,事实上它们是对模型的一种正则化方案。正如周星驰的电影《国产凌凌漆》的一句经典台词:
表面上看这是一个吹风机,其实它是一个刮胡刀。
数据扩增
让我们从数据扩增说起。数据扩增是指我们在对原始数据做一些简单的变换后,它们对应的类别往往不会变化,所以我们可以在原来数据的基础上,“造”出更多的数据来。比如一幅小狗的照片,将它水平翻转、轻微的旋转、裁剪、平移等操作后,我们认为它的类别没有变化,它还是原来的那只狗。这样一来,从一个样本我们可以衍生出好几个样本,从而增加了训练样本量。

狗

旋转的狗
10
Dec
BiGAN-QP:简单清晰的编码&生成模型
By 苏剑林 | 2018-12-10 | 66728位读者 | 引用前不久笔者通过直接在对偶空间中分析的思路,提出了一个称为GAN-QP的对抗模型框架,它的特点是可以从理论上证明既不会梯度消失,又不需要L约束,使得生成模型的搭建和训练都得到简化。
GAN-QP是一个对抗框架,所以理论上原来所有的GAN任务都可以往上面试试。前面《不用L约束又不会梯度消失的GAN,了解一下?》一文中我们只尝试了标准的随机生成任务,而这篇文章中我们尝试既有生成器、又有编码器的情况:BiGAN-QP。
BiGAN与BiGAN-QP
注意这是BiGAN,不是前段时间很火的BigGAN,BiGAN是双向GAN(Bidirectional GAN),提出于《Adversarial feature learning》一文,同期还有一篇非常相似的文章叫做《Adversarially Learned Inference》,提出了叫做ALI的模型,跟BiGAN差不多。总的来说,它们都是往普通的GAN模型中加入了编码器,使得模型既能够具有普通GAN的随机生成功能,又具有编码器的功能,可以用来提取有效的特征。把GAN-QP这种对抗模式用到BiGAN中,就得到了BiGAN-QP。
话不多说,先来上效果图(左边是原图,右边是重构):

BiGAN-QP重构效果图
26
Mar
科学空间浏览指南(FAQ)
By 苏剑林 | 2019-03-26 | 132965位读者 | 引用事实上,除了写博客内容,在这几年里,笔者是花了相当一部分时间来做科学空间的“表面功夫”,为此还专门学了一点php、css和js。虽然不敢说精益求精,但总体来说网站的浏览体验应该比前几年要好得多。
考虑到有些读者可能需要的功能,但一时半会未必能留意到,遂来整理一些站内技巧。
文章篇
什么环境阅读文章最佳?
两年前科学空间就已经加入了响应式设计,自动适应不同分辨率的屏幕。因此,不管哪个分辨率的环境应该都能看清文字内容,唯一的问题是,在小屏幕手机下公式可能会显示不全或者错位。为了较好地阅读公式,最好在7寸以上的屏幕上阅读。如果一定要用小屏幕的手机,可以考虑横屏阅读。
14
Mar
圆周率节快乐!|| 原来已经写了十年博客~
By 苏剑林 | 2019-03-14 | 77386位读者 | 引用
19
Apr
从DCGAN到SELF-MOD:GAN的模型架构发展一览
By 苏剑林 | 2019-04-19 | 81721位读者 | 引用事实上,O-GAN的发现,已经达到了我对GAN的理想追求,使得我可以很惬意地跳出GAN的大坑了。所以现在我会试图探索更多更广的研究方向,比如NLP中还没做过的任务,又比如图神经网络,又或者其他有趣的东西。
不过,在此之前,我想把之前的GAN的学习结果都记录下来。
这篇文章中,我们来梳理一下GAN的架构发展情况,当然主要的是生成器的发展,判别器一直以来的变动都不大。还有,本文介绍的是GAN在图像方面的模型架构发展,跟NLP的SeqGAN没什么关系。
此外,关于GAN的基本科普,本文就不再赘述了。

棋盘效应图示,体现为放大之后出现如国际象棋棋盘一样的交错效应。图片来自文章《Deconvolution and Checkerboard Artifacts》
1
Dec
级联抑制:提升GAN表现的一种简单有效的方法
By 苏剑林 | 2019-12-01 | 34219位读者 | 引用昨天刷arxiv时发现了一篇来自星星韩国的论文,名字很直白,就叫做《A Simple yet Effective Way for Improving the Performance of GANs》。打开一看,发现内容也很简练,就是提出了一种加强GAN的判别器的方法,能让GAN的生成指标有一定的提升。
作者把这个方法叫做Cascading Rejection,我不知道咋翻译,扔到百度翻译里边显示“级联抑制”,想想看好像是有这么点味道,就暂时这样叫着了。介绍这个方法倒不是因为它有多强大,而是觉得它的几何意义很有趣,而且似乎有一定的启发性。
正交分解
GAN的判别器一般是经过多层卷积后,通过flatten或pool得到一个固定长度的向量$\boldsymbol{v}$,然后再与一个权重向量$\boldsymbol{w}$做内积,得到一个标量打分(先不考虑偏置项和激活函数等末节):
\begin{equation}D(\boldsymbol{x})=\langle \boldsymbol{v},\boldsymbol{w}\rangle\end{equation}
也就是说,用$\boldsymbol{v}$作为输入图片的表征,然后通过$\boldsymbol{v}$和$\boldsymbol{w}$的内积大小来判断出这个图片的“真”的程度。
28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 196293位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
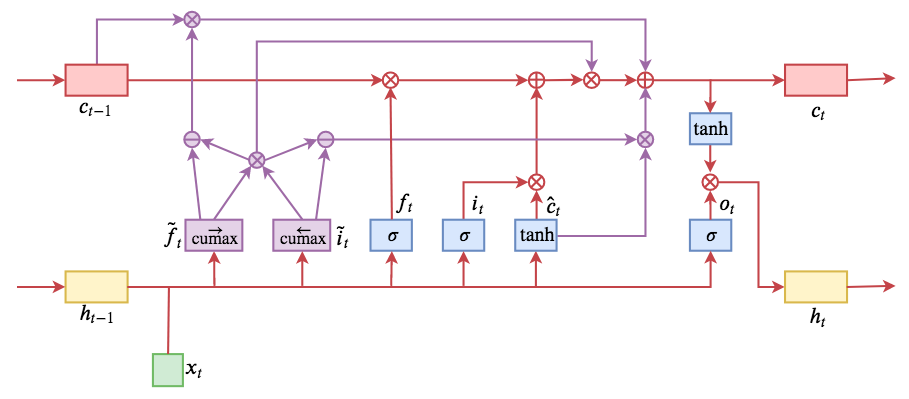
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~

最近评论