






25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 183761位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
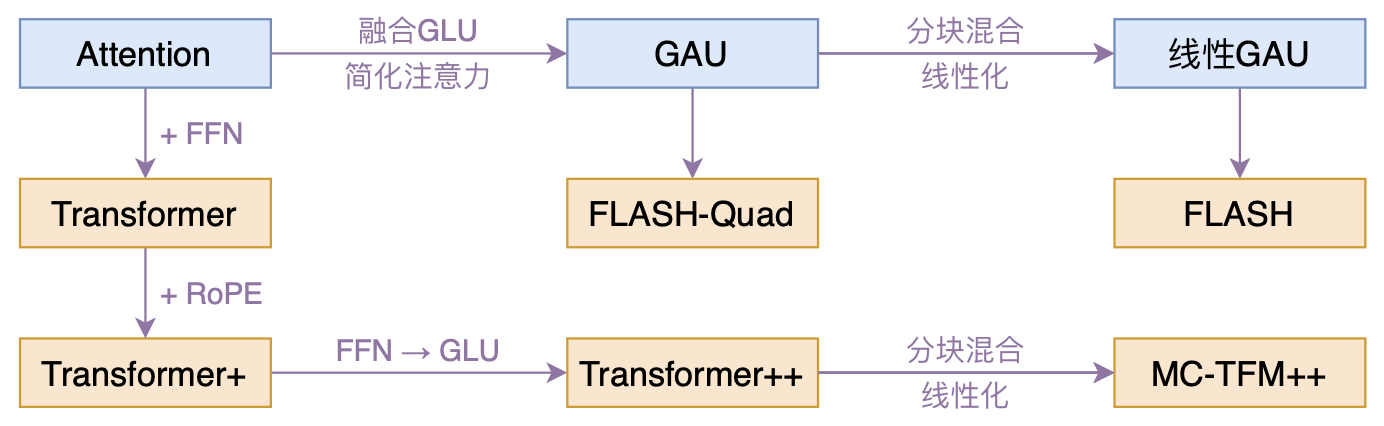
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 78366位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
13
Jun
生成扩散模型漫谈(一):DDPM = 拆楼 + 建楼
By 苏剑林 | 2022-06-13 | 415322位读者 | 引用说到生成模型,VAE、GAN可谓是“如雷贯耳”,本站也有过多次分享。此外,还有一些比较小众的选择,如flow模型、VQ-VAE等,也颇有人气,尤其是VQ-VAE及其变体VQ-GAN,近期已经逐渐发展到“图像的Tokenizer”的地位,用来直接调用NLP的各种预训练方法。除了这些之外,还有一个本来更小众的选择——扩散模型(Diffusion Models)——正在生成模型领域“异军突起”,当前最先进的两个文本生成图像——OpenAI的DALL·E 2和Google的Imagen,都是基于扩散模型来完成的。

Imagen“文本-图片”的部分例子
从本文开始,我们开一个新坑,逐渐介绍一下近两年关于生成扩散模型的一些进展。据说生成扩散模型以数学复杂闻名,似乎比VAE、GAN要难理解得多,是否真的如此?扩散模型真的做不到一个“大白话”的理解?让我们拭目以待。
17
Mar
为什么现在的LLM都是Decoder-only的架构?
By 苏剑林 | 2023-03-17 | 110941位读者 | 引用LLM是“Large Language Model”的简写,目前一般指百亿参数以上的语言模型,主要面向文本生成任务。跟小尺度模型(10亿或以内量级)的“百花齐放”不同,目前LLM的一个现状是Decoder-only架构的研究居多,像OpenAI一直坚持Decoder-only的GPT系列就不说了,即便是Google这样的并非全部押注在Decoder-only的公司,也确实投入了不少的精力去研究Decoder-only的模型,如PaLM就是其中之一。那么,为什么Decoder-only架构会成为LLM的主流选择呢?
知乎上也有同款问题《为什么现在的LLM都是Decoder only的架构?》,上面的回答大多数聚焦于Decoder-only在训练效率和工程实现上的优势,那么它有没有理论上的优势呢?本文试图从这个角度进行简单的分析。
统一视角
需要指出的是,笔者目前训练过的模型,最大也就是10亿级别的,所以从LLM的一般概念来看是没资格回答这个问题的,下面的内容只是笔者根据一些研究经验,从偏理论的角度强行回答一波。文章多数推论以自己的实验结果为引,某些地方可能会跟某些文献的结果冲突,请读者自行取舍。
3
Apr
Bias项的神奇作用:RoPE + Bias = 更好的长度外推性
By 苏剑林 | 2023-04-03 | 43315位读者 | 引用万万没想到,Bias项能跟Transformer的长度外推性联系在一起!
长度外推性是我们希望Transformer具有的一个理想性质,笔者曾在《Transformer升级之路:7、长度外推性与局部注意力》、《Transformer升级之路:8、长度外推性与位置鲁棒性》系统地介绍过这一问题。至于Bias项(偏置项),目前的主流观点是当模型足够大时,Bias项不会有什么特别的作用,所以很多模型选择去掉Bias项,其中代表是Google的T5和PaLM,我们后面做的RoFormerV2和GAU-α也沿用了这个做法。
那么,这两个看上去“风牛马不相及”的东西,究竟是怎么联系起来的呢?Bias项真的可以增强Transformer的长度外推性?且听笔者慢慢道来。
29
Nov
我在Performer中发现了Transformer-VQ的踪迹
By 苏剑林 | 2023-11-29 | 46829位读者 | 引用前些天我们在《VQ一下Key,Transformer的复杂度就变成线性了》介绍了“Transformer-VQ”,这是通过将Key序列做VQ(Vector Quantize)变换来实现Attention复杂度线性化的方案。诚然,Transformer-VQ提供了标准Attention到线性Attentino的一个非常漂亮的过渡,给人一种“大道至简”的美感,但熟悉VQ的读者应该能感觉到,当编码表大小或者模型参数量进一步增加时,VQ很可能会成为效果提升的瓶颈,因为它通过STE(Straight-Through Estimator)估计的梯度大概率是次优的(FSQ的实验结果也算是提供了一些佐证)。此外,Transformer-VQ为了使训练效率也线性化所做的梯度截断,也可能成为将来的效果瓶颈之一。
为此,笔者花了一些时间思考可以替代掉VQ的线性化思路。从Transformer-VQ的$\exp\left(QC^{\top}\right)$形式中,笔者联想到了Performer,继而“顺藤摸瓜”地发现原来Performer可以视为Soft版的Transformer-VQ。进一步地,笔者尝试类比Performer的推导方法来重新导出Transformer-VQ,为其后的优化提供一些参考结果。
9
Nov
VQ一下Key,Transformer的复杂度就变成线性了
By 苏剑林 | 2023-11-09 | 68481位读者 | 引用Efficient Transformer,泛指一切致力于降低Transformer的二次复杂度的工作,开始特指针对Attention的改进,后来更一般的思路,如傅里叶变换、线性RNN等,也被归入这个范畴。不得不说,为了降低Transformer的二次复杂度,各路大牛可谓是“八仙过海,各显神通”,各种神奇的思路“百花齐放”,笔者也从中学习到了不少理论知识。然而,尽管Efficient Transformer在理论上是精彩的,但实际上该领域一直都是不愠不火的状态,并没有实际表现十分出色的模型,在LLM火爆的今天,甚至已经逐渐淡出了大家的视野,也淡出了笔者的兴趣范围。
不过,最近有一篇论文《Transformer-VQ: Linear-Time Transformers via Vector Quantization》,却让笔者为之拍案叫绝。作者非常高明地洞察到,只需要对标准Attention的Key做一下VQ(Vector Quantize),复杂度就会自动降低为线性!这种线性化思路保留了标准Attention的形式,是标准Attention到线性Attention的一个完美过渡,同时最大程度上保留了标准Attention的能力。
高效难题
说起来,本站也算是比较早关注Efficient Transformer相关工作了,最早可以追溯到2019年解读Sparse Transformer的一篇博客《为节约而生:从标准Attention到稀疏Attention》。此后,陆续写的关于Efficient Transformer的其他博文还有
12
Dec
注意力机制真的可以“集中注意力”吗?
By 苏剑林 | 2023-12-12 | 46214位读者 | 引用之前在《Transformer升级之路:3、从Performer到线性Attention》、《为什么现在的LLM都是Decoder-only的架构?》等文章中,我们从Attention矩阵的“秩”的角度探讨了Attention机制,并曾经判断线性Attention不如标准Attention的关键原因正是“低秩瓶颈”。然而,这一解释对于双向的Encoder模型或许成立,但却难以适用于单向的Decoder模型,因为Decoder的Attention矩阵的上三角部分是被mask掉的,留下的下三角矩阵必然是满秩的,而既然都是满秩了,那么低秩瓶颈问题似乎就不复存在了。
所以,“低秩瓶颈”并不能完全解释线性Attention的能力缺陷。在这篇文章中,笔者试图寻求另一个角度的解释。简单来说,与标准Attention相比,线性Attention更难“集中注意力”,从而难以准确地定位到关键token,这大概是它效果稍逊一筹的主要原因。

最近评论