






2
Dec
最小熵原理(四):“物以类聚”之从图书馆到词向量
By 苏剑林 | 2018-12-02 | 95318位读者 | 引用从第一篇看下来到这里,我们知道所谓“最小熵原理”就是致力于降低学习成本,试图用最小的成本完成同样的事情。所以整个系列就是一个“偷懒攻略”。那偷懒的秘诀是什么呢?答案是“套路”,所以本系列又称为“套路宝典”。
本篇我们介绍图书馆里边的套路。
先抛出一个问题:词向量出现在什么时候?是2013年Mikolov的Word2Vec?还是是2003年Bengio大神的神经语言模型?都不是,其实词向量可以追溯到千年以前,在那古老的图书馆中...

图书馆一角(图片来源于百度搜索)
走进图书馆
图书馆里有词向量?还是千年以前?在哪本书?我去借来看看。
放书的套路
其实不是哪本书,而是放书的套路。
很明显,图书馆中书的摆放是有“套路”的:它们不是随机摆放的,而是分门别类地放置的,比如数学类放一个区,文学类放一个区,计算机类也放一个区;同一个类也有很多子类,比如数学类中,数学分析放一个子区,代数放一个子区,几何放一个子区,等等。读者是否思考过,为什么要这么分类放置?分类放置有什么好处?跟最小熵又有什么关系?
10
Apr
分享一次专业领域词汇的无监督挖掘
By 苏剑林 | 2019-04-10 | 85660位读者 | 引用去年 Data Fountain 曾举办了一个“电力专业领域词汇挖掘”的比赛,该比赛有意思的地方在于它是一个“无监督”的比赛,也就是说它考验的是从大量的语料中无监督挖掘专业词汇的能力。
这个显然确实是工业界比较有价值的一个能力,又想着我之前也在无监督新词发现中做过一定的研究,加之“无监督比赛”的新颖性,所以当时毫不犹豫地参加了,然而最终排名并不靠前~
不管怎样,还是分享一下我自己的做法,这是一个真正意义上的无监督做法,也许会对部分读者有些参考价值。
基准对比
首先,新词发现部分,用到了我自己写的库nlp zero,基本思路是先分别对“比赛所给语料”、“自己爬的一部分百科百科语料”做新词发现,然后两者进行对比,就能找到一批“比赛所给语料”的特征词。
19
Apr
从DCGAN到SELF-MOD:GAN的模型架构发展一览
By 苏剑林 | 2019-04-19 | 81496位读者 | 引用事实上,O-GAN的发现,已经达到了我对GAN的理想追求,使得我可以很惬意地跳出GAN的大坑了。所以现在我会试图探索更多更广的研究方向,比如NLP中还没做过的任务,又比如图神经网络,又或者其他有趣的东西。
不过,在此之前,我想把之前的GAN的学习结果都记录下来。
这篇文章中,我们来梳理一下GAN的架构发展情况,当然主要的是生成器的发展,判别器一直以来的变动都不大。还有,本文介绍的是GAN在图像方面的模型架构发展,跟NLP的SeqGAN没什么关系。
此外,关于GAN的基本科普,本文就不再赘述了。

棋盘效应图示,体现为放大之后出现如国际象棋棋盘一样的交错效应。图片来自文章《Deconvolution and Checkerboard Artifacts》
11
Nov
JoSE:球面上的词向量和句向量
By 苏剑林 | 2019-11-11 | 69225位读者 | 引用这篇文章介绍一个发表在NeurIPS 2019的做词向量和句向量的模型JoSE(Joint Spherical Embedding),论文名字是《Spherical Text Embedding》。JoSE模型思想上和方法上传承自Doc2Vec,评测结果更加漂亮,但写作有点故弄玄虚之感。不过笔者决定写这篇文章,是因为觉得里边的某些分析过程有点意思,可能会对一般的优化问题都有些参考价值。
优化目标
在思想上,这篇文章基本上跟Doc2Vec是一致的:为了训练句向量,把句子用一个id表示,然后把它也当作一个词,跟句内所有的词都共现,最后训练一个Skip Gram模型,训练的方式都是基于负采样的。跟Doc2Vec不一样的是,JoSE将全体向量的模长都归一化了(也就是只考虑单位球面上的向量),然后训练目标没有用交叉熵,而是用hinge loss:
\begin{equation}\max(0, m - \cos(\boldsymbol{u}, \boldsymbol{v}) - \cos(\boldsymbol{u}, \boldsymbol{d}) + \cos(\boldsymbol{u}', \boldsymbol{v}) + \cos(\boldsymbol{u}', \boldsymbol{d})\label{eq:loss}\end{equation}
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 135230位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 426514位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
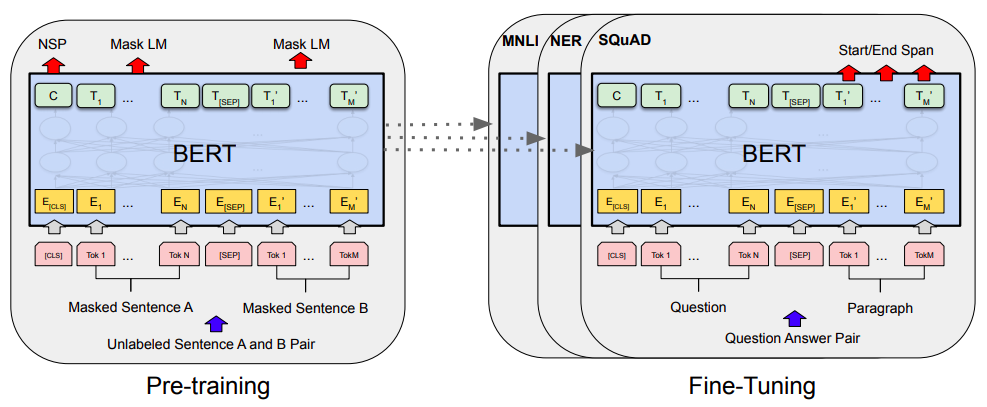
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。
29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 142708位读者 | 引用在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
8
Jul
用时间换取效果:Keras梯度累积优化器
By 苏剑林 | 2019-07-08 | 80489位读者 | 引用现在Keras中你也可以用小的batch size实现大batch size的效果了——只要你愿意花$n$倍的时间,可以达到$n$倍batch size的效果,而不需要增加显存。
Github地址:https://github.com/bojone/accum_optimizer_for_keras
扯淡
在一两年之前,做NLP任务都不用怎么担心OOM问题,因为相比CV领域的模型,其实大多数NLP模型都是很浅的,极少会显存不足。幸运或者不幸的是,Bert出世了,然后火了。Bert及其后来者们(GPT-2、XLNET等)都是以足够庞大的Transformer模型为基础,通过足够多的语料预训练模型,然后通过fine tune的方式来完成特定的NLP任务。

最近评论