






4
Dec
开局一段扯,数据全靠编?真被一篇“神论文”气到了
By 苏剑林 | 2021-12-04 | 54145位读者 | 引用这篇文章谈一下笔者被昨天出来的一篇“神论文”气到了的经历。
这篇“神论文”是《How not to Lie with a Benchmark: Rearranging NLP Leaderboards》,论文的大致内容是说目前很多排行榜算平均都用算术平均,而它认为几何平均与调和平均更加合理。最关键是它还对GLUE、SuperGLUE等榜单上的模型用几何平均和调和平均重新算了一下排名,结果发现那些超过人类的模型在新的平均方案下都没超过人类了。
看上去是不是觉得挺有意思的?我也觉得挺有意思的,所以打算写一篇博客介绍一下它。结果博客快写完了,然后在对数据的时候,发现里边表格的数据全是乱来的!!!真实的结果完全不支撑它的结论!!!所以,这篇博客就从“表扬大会”变成了“批评大会”...
25
Feb
FLASH:可能是近来最有意思的高效Transformer设计
By 苏剑林 | 2022-02-25 | 175189位读者 | 引用高效Transformer,泛指所有概率Transformer效率的工作,笔者算是关注得比较早了,最早的博客可以追溯到2019年的《为节约而生:从标准Attention到稀疏Attention》,当时做这块的工作很少。后来,这类工作逐渐多了,笔者也跟进了一些,比如线性Attention、Performer、Nyströmformer,甚至自己也做了一些探索,比如之前的“Transformer升级之路”。再后来,相关工作越来越多,但大多都很无趣,所以笔者就没怎么关注了。
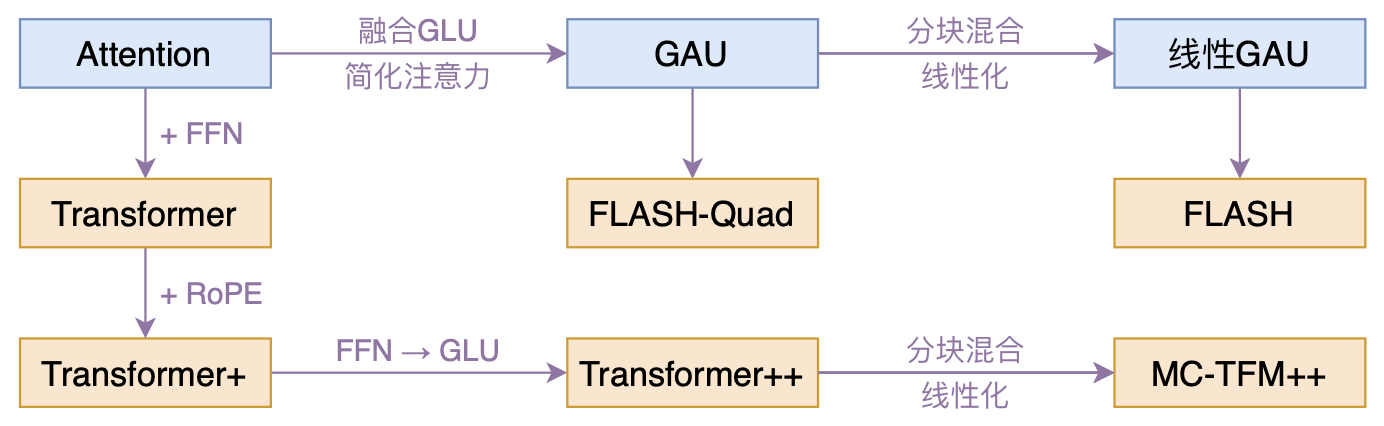
本文模型脉络图
大抵是“久旱逢甘霖”的感觉,最近终于出现了一个比较有意思的高效Transformer工作——来自Google的《Transformer Quality in Linear Time》,经过细读之后,笔者认为论文里边真算得上是“惊喜满满”了~
9
Mar
训练1000层的Transformer究竟有什么困难?
By 苏剑林 | 2022-03-09 | 74800位读者 | 引用众所周知,现在的Transformer越做越大,但这个“大”通常是“宽”而不是“深”,像GPT-3虽然参数有上千亿,但也只是一个96层的Transformer模型,与我们能想象的深度相差甚远。是什么限制了Transformer往“深”发展呢?可能有的读者认为是算力,但“宽而浅”的模型所需的算力不会比“窄而深”的模型少多少,所以算力并非主要限制,归根结底还是Transformer固有的训练困难。一般的观点是,深模型的训练困难源于梯度消失或者梯度爆炸,然而实践显示,哪怕通过各种手段改良了梯度,深模型依然不容易训练。
近来的一些工作(如Admin)指出,深模型训练的根本困难在于“增量爆炸”,即模型越深对输出的扰动就越大。上周的论文《DeepNet: Scaling Transformers to 1,000 Layers》则沿着这个思路进行尺度分析,根据分析结果调整了模型的归一化和初始化方案,最终成功训练出了1000层的Transformer模型。整个分析过程颇有参考价值,我们不妨来学习一下。
增量爆炸
原论文的完整分析比较长,而且有些假设或者描述细酌之下是不够合理的。所以在本文的分享中,笔者会尽量修正这些问题,试图以一个更合理的方式来得到类似结果。
7
Apr
听说Attention与Softmax更配哦~
By 苏剑林 | 2022-04-07 | 72765位读者 | 引用不知道大家留意到一个细节没有,就是当前NLP主流的预训练模式都是在一个固定长度(比如512)上进行,然后直接将预训练好的模型用于不同长度的任务中。大家似乎也没有对这种模式有过怀疑,仿佛模型可以自动泛化到不同长度是一个“理所应当”的能力。
当然,笔者此前同样也没有过类似的质疑,直到前几天笔者做了Base版的GAU实验后才发现GAU的长度泛化能力并不如想象中好。经过进一步分析后,笔者才明白原来这种长度泛化的能力并不是“理所当然”的......
模型回顾
在《FLASH:可能是近来最有意思的高效Transformer设计》中,我们介绍了“门控注意力单元GAU”,它是一种融合了GLU和Attention的新设计。
除了效果,GAU在设计上给我们带来的冲击主要有两点:一是它显示了单头注意力未必就逊色于多头注意力,这奠定了它“快”、“省”的地位;二是它是显示了注意力未必需要Softmax归一化,可以换成简单的$\text{relu}^2$除以序列长度:
\begin{equation}\boldsymbol{A}=\frac{1}{n}\text{relu}^2\left(\frac{\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}}{\sqrt{s}}\right)=\frac{1}{ns}\text{relu}^2\left(\mathcal{Q}(\boldsymbol{Z})\mathcal{K}(\boldsymbol{Z})^{\top}\right)\end{equation}
1
Jun
如何训练你的准确率?
By 苏剑林 | 2022-06-01 | 26394位读者 | 引用最近Arxiv上的一篇论文《EXACT: How to Train Your Accuracy》引起了笔者的兴趣,顾名思义这是介绍如何直接以准确率为训练目标来训练模型的。正好笔者之前也对此有过一些分析,如《函数光滑化杂谈:不可导函数的可导逼近》、《再谈类别不平衡问题:调节权重与魔改Loss的对比联系》等, 所以带着之前的研究经验很快完成了论文的阅读,写下了这篇总结,并附上了最近关于这个主题的一些新思考。
失实的例子
论文开头指出,我们平时用的分类损失函数是交叉熵或者像SVM中的Hinge Loss,这两个损失均不能很好地拟合最终的评价指标准确率。为了说明这一点,论文举了一个很简单的例子:假设数据只有$\{(-0.25,-1),(0,-1),(0.25,,1)\}$三个点,$-1$和$1$分别代表负类和正类,待拟合模型是$f(x)=x-b$,$b$是参数,我们希望通过$\text{sign}(f(x))$来预测类别。如果用“sigmoid + 交叉熵”,那么损失函数就是$-\log \frac{1}{1+e^{-l \cdot f(x)}}$,$(x,l)$代表一对标签数据;如果用Hinge Loss,则是$\max(0, 1 - l\cdot f(x))$。
7
Jun
相对位置编码Transformer的一个理论缺陷与对策
By 苏剑林 | 2022-06-07 | 92440位读者 | 引用位置编码是Transformer中很重要的一环,在《让研究人员绞尽脑汁的Transformer位置编码》中我们就总结了一些常见的位置编码设计。大体上,我们将Transformer的位置编码分为“绝对位置编码”和“相对位置编码”两类,其中“相对位置编码”在众多NLP/CV的实验表现相对来说更加好些。
然而,我们可以发现,目前相对位置编码几乎都是在Softmax之前的Attention矩阵上进行操作的,这种施加方式实际上都存在一个理论上的缺陷,使得Transformer无法成为“万能拟合器”。本文就来分析这个问题,并探讨一些解决方案。
简单探针
顾名思义,位置编码就是用来给模型补充上位置信息的。那么,如何判断一个模型有没有足够的识别位置的能力呢?笔者之前曾构思过一个简单的探针实验:
对于一个有识别位置能力的模型,应该有能力准确实现如下映射 \begin{equation}\begin{array}{lc} \text{输入:} & [0, 0, \cdots, 0, 0] \\ & \downarrow\\ \text{输出:} & [1, 2, \cdots, n-1, n] \end{array}\end{equation}
20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 67150位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
30
Aug
生成扩散模型漫谈(九):条件控制生成结果
By 苏剑林 | 2022-08-30 | 134528位读者 | 引用前面的几篇文章都是比较偏理论的结果,这篇文章我们来讨论一个比较有实用价值的主题——条件控制生成。
作为生成模型,扩散模型跟VAE、GAN、flow等模型的发展史很相似,都是先出来了无条件生成,然后有条件生成就紧接而来。无条件生成往往是为了探索效果上限,而有条件生成则更多是应用层面的内容,因为它可以实现根据我们的意愿来控制输出结果。从DDPM至今,已经出来了很多条件扩散模型的工作,甚至可以说真正带火了扩散模型的就是条件扩散模型,比如脍炙人口的文生图模型DALL·E 2、Imagen。
在这篇文章中,我们对条件扩散模型的理论基础做个简单的学习和总结。
技术分析
从方法上来看,条件控制生成的方式分两种:事后修改(Classifier-Guidance)和事前训练(Classifier-Free)。

最近评论