






29
Jan
网站更新记录(2018年01月)
By 苏剑林 | 2018-01-29 | 29364位读者 | 引用也许读者会发现,这几天访问科学空间可能出现不稳定的情况,原因是我这几天都在对网站进行调整。
这次的调整幅度很大,不过从外表上可能很难发现,特此记录留念一下。主要的更新内容包括:
1、主题的优化:本博客用的geekg主题其实比较老了,去年花钱请人对它进行了第一次大升级,加入了响应式设计,这几天主要解决该主题的一些历史遗留问题,包括图片显示、边距、排版等细微调整;
2、内部的优化:大幅度减少了插件的使用,把一些基本的功能(如网站目录、归档页)等都内嵌到主题中,减少了对插件的依赖,也提升了可用性;
3、文章的优化:其实这也是个历史遗留问题,主要是早期写文章的时候比较随意,html代码、公式的LaTeX代码等都不规范,因此早期的文章显示效果可能比较糟糕,于是我就做了一件很疯狂的事情——把800多篇文章都过一遍!经过了两天多的时间,基本上修复了早期文章的大部分问题;
4、域名的优化:网站全面使用https!网站放在阿里云上面,可是阿里云有一套自以为是的监管系统,无故屏蔽我的一些页面。为了应对阿里云的恶意屏蔽,只好转向https,当然,这不会对读者平时访问造成影响,因为跳转https是自动的。目前两个域名spaces.ac.cn和kexue.fm都会自动跳转到https。
2
Mar
三味Capsule:矩阵Capsule与EM路由
By 苏剑林 | 2018-03-02 | 209304位读者 | 引用事实上,在论文《Dynamic Routing Between Capsules》发布不久后,一篇新的Capsule论文《Matrix Capsules with EM Routing》就已经匿名公开了(在ICLR 2018的匿名评审中),而如今作者已经公开,他们是Geoffrey Hinton, Sara Sabour, Nicholas Frosst。不出大家意料,作者果然有Hinton。
大家都知道,像Hinton这些“鼻祖级”的人物,发表出来的结果一般都是比较“重磅”的。那么,这篇新论文有什么特色呢?
在笔者的思考过程中,文章《Understanding Matrix capsules with EM Routing 》给了我颇多启示,知乎上各位大神的相关讨论也加速了我的阅读,在此表示感谢。
论文摘要
让我们先来回忆一下上一篇介绍《再来一顿贺岁宴:从K-Means到Capsule》中的那个图
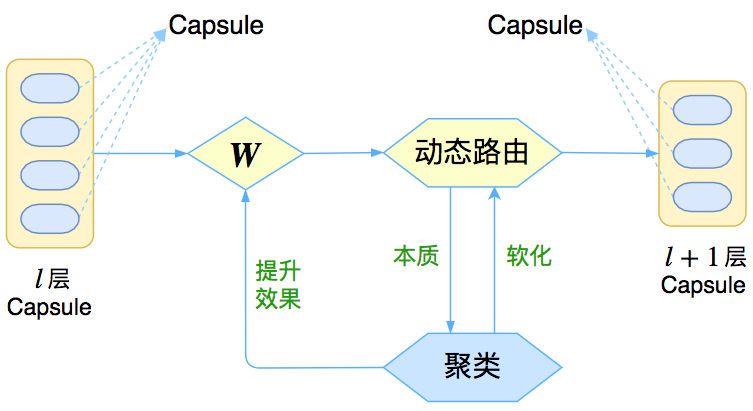
Capsule框架的简明示意图
这个图表明,Capsule事实上描述了一个建模的框架,这个框架中的东西很多都是可以自定义的,最明显的是聚类算法,可以说“有多少种聚类算法就有多少种动态路由”。那么这次Hinton修改了什么呢?总的来说,这篇新论文有以下几点新东西:
1、原来用向量来表示一个Capsule,现在用矩阵来表示;
2、聚类算法换成了GMM(高斯混合模型);
3、在实验部分,实现了Capsule版的卷积。
15
Apr
基于CNN的阅读理解式问答模型:DGCNN
By 苏剑林 | 2018-04-15 | 422236位读者 | 引用2019.08.20更新:开源了一个Keras版(https://kexue.fm/archives/6906)
早在年初的《Attention is All You Need》的介绍文章中就已经承诺过会分享CNN在NLP中的使用心得,然而一直不得其便。这几天终于下定决心来整理一下相关的内容了。
背景
事不宜迟,先来介绍一下模型的基本情况。
模型特点
本模型——我称之为DGCNN——是基于CNN和简单的Attention的模型,由于没有用到RNN结构,因此速度相当快,而且是专门为这种WebQA式的任务定制的,因此也相当轻量级。SQUAD排行榜前面的模型,如AoA、R-Net等,都用到了RNN,并且还伴有比较复杂的注意力交互机制,而这些东西在DGCNN中基本都没有出现。
这是一个在GTX1060上都可以几个小时训练完成的模型!

截止到2018.04.14的排行榜
DGCNN,全名为Dilate Gated Convolutional Neural Network,即“膨胀门卷积神经网络”,顾名思义,融合了两个比较新的卷积用法:膨胀卷积、门卷积,并增加了一些人工特征和trick,最终使得模型在轻、快的基础上达到最佳的效果。在本文撰写之时,本文要介绍的模型还位于榜首,得分(得分是准确率与F1的平均)为0.7583,而且是到目前为止唯一一个一直没有跌出前三名、并且获得周冠军次数最多的模型。
18
Apr
最小熵原理(一):无监督学习的原理
By 苏剑林 | 2018-04-18 | 82738位读者 | 引用话在开头
在深度学习等端到端方案已经逐步席卷NLP的今天,你是否还愿意去思考自然语言背后的基本原理?我们常说“文本挖掘”,你真的感受到了“挖掘”的味道了吗?
无意中的邂逅
前段时间看了一篇关于无监督句法分析的文章,继而从它的参考文献中发现了论文《Redundancy Reduction as a Strategy for Unsupervised Learning》,这篇论文介绍了如何从去掉空格的英文文章中将英文单词复原。对应到中文,这不就是词库构建吗?于是饶有兴致地细读了一番,发现论文思路清晰、理论完整、结果漂亮,让人赏心悦目。
尽管现在看来,这篇论文的价值不是很大,甚至其结果可能已经被很多人学习过了,但是要注意:这是一篇1993年的论文!在PC机还没有流行的年代,就做出了如此前瞻性的研究。虽然如今深度学习流行,NLP任务越做越复杂,这确实是一大进步,但是我们对NLP原理的真正了解,还不一定超过几十年前的前辈们多少。
这篇论文是通过“去冗余”(Redundancy Reduction)来实现无监督地构建词库的,从信息论的角度来看,“去冗余”就是信息熵的最小化。无监督句法分析那篇文章也指出“信息熵最小化是无监督的NLP的唯一可行的方案”。我进而学习了一些相关资料,并且结合自己的理解思考了一番,发现这个评论确实是耐人寻味。我觉得,不仅仅是NLP,信息熵最小化很可能是所有无监督学习的根本。
24
Apr
最小熵原理(二):“当机立断”之词库构建
By 苏剑林 | 2018-04-24 | 79133位读者 | 引用在本文,我们介绍“套路宝典”第一式——“当机立断”:1、导出平均字信息熵的概念,然后基于最小熵原理推导出互信息公式;2、并且完成词库的无监督构建、给出一元分词模型的信息熵诠释,从而展示有关生成套路、识别套路的基本方法和技巧。
这既是最小熵原理的第一个使用案例,也是整个“套路宝典”的总纲。
你练或者不练,套路就在那里,不增不减。
为什么需要词语
从上一篇文章可以看到,假设我们根本不懂中文,那么我们一开始会将中文看成是一系列“字”随机组合的字符串,但是慢慢地我们会发现上下文是有联系的,它并不是“字”的随机组合,它应该是“套路”的随机组合。于是为了减轻我们的记忆成本,我们会去挖掘一些语言的“套路”。第一个“套路”,是相邻的字之间的组合定式,这些组合定式,也就是我们理解的“词”。
平均字信息熵
假如有一批语料,我们将它分好词,以词作为中文的单位,那么每个词的信息量是$-\log p_w$,因此我们就可以计算记忆这批语料所要花费的时间为
$$-\sum_{w\in \text{语料}}\log p_w\tag{2.1}$$
这里$w\in \text{语料}$是对语料逐词求和,不用去重。如果不分词,按照字来理解,那么需要的时间为
$$-\sum_{c\in \text{语料}}\log p_c\tag{2.2}$$
10
May
用Numpy实现高效的Apriori算法
By 苏剑林 | 2018-05-10 | 92821位读者 | 引用
11
May
【致敬】费曼诞辰100年
By 苏剑林 | 2018-05-11 | 29901位读者 | 引用
18
May
简明条件随机场CRF介绍(附带纯Keras实现)
By 苏剑林 | 2018-05-18 | 314452位读者 | 引用笔者去年曾写过博文《果壳中的条件随机场(CRF In A Nutshell)》,以一种比较粗糙的方式介绍了一下条件随机场(CRF)模型。然而那篇文章显然有很多不足的地方,比如介绍不够清晰,也不够完整,还没有实现,在这里我们重提这个模型,将相关内容补充完成。
本文是对CRF基本原理的一个简明的介绍。当然,“简明”是相对而言中,要想真的弄清楚CRF,免不了要提及一些公式,如果只关心调用的读者,可以直接移到文末。
图示
按照之前的思路,我们依旧来对比一下普通的逐帧softmax和CRF的异同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活,如下图所示
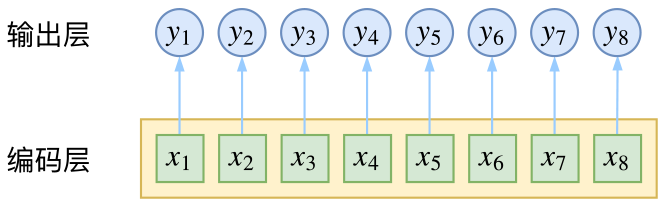
逐帧softmax并没有直接考虑输出的上下文关联

最近评论