






28
May
ON-LSTM:用有序神经元表达层次结构
By 苏剑林 | 2019-05-28 | 195651位读者 | 引用今天介绍一个有意思的LSTM变种:ON-LSTM,其中“ON”的全称是“Ordered Neurons”,即有序神经元,换句话说这种LSTM内部的神经元是经过特定排序的,从而能够表达更丰富的信息。ON-LSTM来自文章《Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks》,顾名思义,将神经元经过特定排序是为了将层级结构(树结构)整合到LSTM中去,从而允许LSTM能自动学习到层级结构信息。这篇论文还有另一个身份:ICLR 2019的两篇最佳论文之一,这表明在神经网络中融合层级结构(而不是纯粹简单地全向链接)是很多学者共同感兴趣的课题。
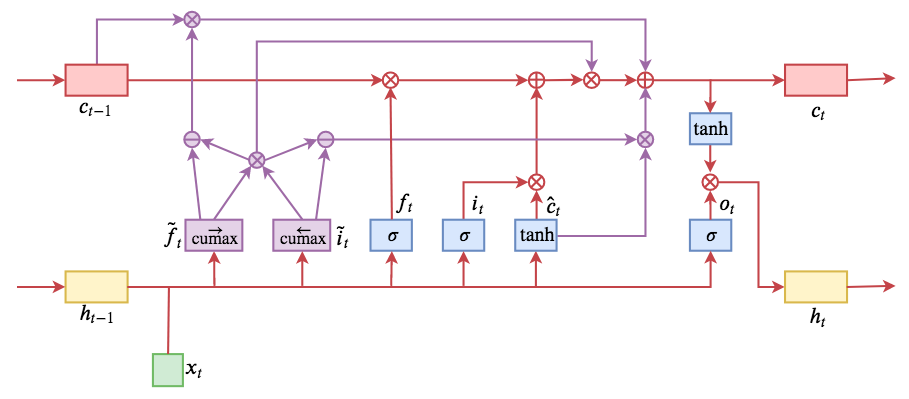
ON-LSTM运算流程示意图。主要是将分段函数用cumax光滑化变成可导。
笔者留意到ON-LSTM是因为机器之心的介绍,里边提到它除了提高了语言模型的效果之外,甚至还可以无监督地学习到句子的句法结构!正是这一点特性深深吸引了我,而它最近获得ICLR 2019最佳论文的认可,更是坚定了我要弄懂它的决心。认真研读、推导了差不多一星期之后,终于有点眉目了,遂写下此文。
在正式介绍ON-LSTM之后,我忍不住要先吐槽一下这篇文章实在是写得太差了,将一个明明很生动形象的设计,讲得异常晦涩难懂,其中的核心是$\tilde{f}_t$和$\tilde{i}_t$的定义,文中几乎没有任何铺垫就贴了出来,也没有多少诠释,开始的读了好几次仍然像天书一样...总之,文章写法实在不敢恭维~
26
Aug
HSIC简介:一个有意思的判断相关性的思路
By 苏剑林 | 2019-08-26 | 100951位读者 | 引用前几天,在机器之心看到这样的一个推送《彻底解决梯度爆炸问题,新方法不用反向传播也能训练ResNet》,当然,媒体的标题党作风我们暂且无视,主要看内容即可。机器之心的这篇文章,介绍的是论文《The HSIC Bottleneck: Deep Learning without Back-Propagation》的成果,里边提出了一种通过HSIC Bottleneck来训练神经网络的算法。
坦白说,这篇论文笔者还没有看明白,因为对笔者来说里边的新概念有点多了。不过论文中的“HSIC”这个概念引起了笔者的兴趣。经过学习,终于基本地理解了这个HSIC的含义和来龙去脉,于是就有了本文,试图给出HSIC的一个尽可能通俗(但可能不严谨)的理解。
背景
HSIC全称“Hilbert-Schmidt independence criterion”,中文可以叫做“希尔伯特-施密特独立性指标”吧,跟互信息一样,它也可以用来衡量两个变量之间的独立性。
18
Sep
从语言模型到Seq2Seq:Transformer如戏,全靠Mask
By 苏剑林 | 2019-09-18 | 332451位读者 | 引用相信近一年来(尤其是近半年来),大家都能很频繁地看到各种Transformer相关工作(比如Bert、GPT、XLNet等等)的报导,连同各种基础评测任务的评测指标不断被刷新。同时,也有很多相关的博客、专栏等对这些模型做科普和解读。
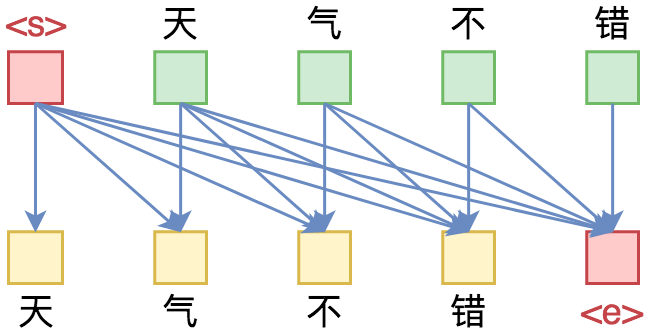
单向语言模型图示。每预测一个token,只依赖于前面的token。
俗话说,“外行看热闹,内行看门道”,我们不仅要在“是什么”这个层面去理解这些工作,我们还需要思考“为什么”。这个“为什么”不仅仅是“为什么要这样做”,还包括“为什么可以这样做”。比如,在谈到XLNet的乱序语言模型时,我们或许已经从诸多介绍中明白了乱序语言模型的好处,那不妨更进一步思考一下:
为什么Transformer可以实现乱序语言模型?是怎么实现的?RNN可以实现吗?
本文从对Attention矩阵进行Mask的角度,来分析为什么众多Transformer模型可以玩得如此“出彩”的基本原因,正如标题所述“Transformer如戏,全靠Mask”,这是各种花式Transformer模型的重要“门道”之一。
读完本文,你或许可以了解到:
1、Attention矩阵的Mask方式与各种预训练方案的关系;
2、直接利用预训练的Bert模型来做Seq2Seq任务。
13
Apr
突破瓶颈,打造更强大的Transformer
By 苏剑林 | 2020-04-13 | 128385位读者 | 引用自《Attention is All You Need》一文发布后,基于Multi-Head Attention的Transformer模型开始流行起来,而去年发布的BERT模型更是将Transformer模型的热度推上了又一个高峰。当然,技术的探索是无止境的,改进的工作也相继涌现:有改进预训练任务的,比如XLNET的PLM、ALBERT的SOP等;有改进归一化的,比如Post-Norm向Pre-Norm的改变,以及T5中去掉了Layer Norm里边的beta参数等;也有改进模型结构的,比如Transformer-XL等;有改进训练方式的,比如ALBERT的参数共享等;...
以上的这些改动,都是在Attention外部进行改动的,也就是说它们都默认了Attention的合理性,没有对Attention本身进行改动。而本文我们则介绍关于两个新结果:它们针对Multi-Head Attention中可能存在建模瓶颈,提出了不同的方案来改进Multi-Head Attention。两篇论文都来自Google,并且做了相当充分的实验,因此结果应该是相当有说服力的了。
再小也不能小key_size
第一个结果来自文章《Low-Rank Bottleneck in Multi-head Attention Models》,它明确地指出了Multi-Head Attention里边的表达能力瓶颈,并提出通过增大key_size的方法来缓解这个瓶颈。
20
Nov
跟风玩玩目前最大的中文GPT2模型(bert4keras)
By 苏剑林 | 2020-11-20 | 72673位读者 | 引用相信不少读者这几天都看到了清华大学与智源人工智能研究院一起搞的“清源计划”(相关链接《中文版GPT-3来了?智源研究院发布清源 CPM —— 以中文为核心的大规模预训练模型》),里边开源了目前最大的中文GPT2模型CPM-LM(26亿参数),据说未来还会开源200亿甚至1000亿参数的模型,要打造“中文界的GPT3”。

官方给出的CPM-LM的Few Shot效果演示图
我们知道,GPT3不需要finetune就可以实现Few Shot,而目前CPM-LM的演示例子中,Few Shot的效果也是相当不错的,让人跃跃欲试,笔者也不例外。既然要尝试,肯定要将它适配到自己的bert4keras中才顺手,于是适配工作便开始了。本以为这是一件很轻松的事情,谁知道踩坑踩了快3天才把它搞好,在此把踩坑与测试的过程稍微记录一下。
11
Jan
你可能不需要BERT-flow:一个线性变换媲美BERT-flow
By 苏剑林 | 2021-01-11 | 209000位读者 | 引用BERT-flow来自论文《On the Sentence Embeddings from Pre-trained Language Models》,中了EMNLP 2020,主要是用flow模型校正了BERT出来的句向量的分布,从而使得计算出来的cos相似度更为合理一些。由于笔者定时刷Arixv的习惯,早在它放到Arxiv时笔者就看到了它,但并没有什么兴趣,想不到前段时间小火了一把,短时间内公众号、知乎等地出现了不少的解读,相信读者们多多少少都被它刷屏了一下。
从实验结果来看,BERT-flow确实是达到了一个新SOTA,但对于这一结果,笔者的第一感觉是:不大对劲!当然,不是说结果有问题,而是根据笔者的理解,flow模型不大可能发挥关键作用。带着这个直觉,笔者做了一些分析,果不其然,笔者发现尽管BERT-flow的思路没有问题,但只要一个线性变换就可以达到相近的效果,flow模型并不是十分关键。
余弦相似度的假设
一般来说,我们语义相似度比较或检索,都是给每个句子算出一个句向量来,然后算它们的夹角余弦来比较或者排序。那么,我们有没有思考过这样的一个问题:余弦相似度对所输入的向量提出了什么假设呢?或者说,满足什么条件的向量用余弦相似度做比较效果会更好呢?
20
Jun
Ladder Side-Tuning:预训练模型的“过墙梯”
By 苏剑林 | 2022-06-20 | 70041位读者 | 引用如果说大型的预训练模型是自然语言处理的“张良计”,那么对应的“过墙梯”是什么呢?笔者认为是高效地微调这些大模型到特定任务上的各种技巧。除了直接微调全部参数外,还有像Adapter、P-Tuning等很多参数高效的微调技巧,它们能够通过只微调很少的参数来达到接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
最近的一篇论文《LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning》则提出了一个新的名为“Ladder Side-Tuning(LST)”的训练技巧,它号称同时达到了参数高效和训练高效。是否真有这么理想的“过墙梯”?本来就让我们一起来学习一下。
26
Jan
Transformer升级之路:16、“复盘”长度外推技术
By 苏剑林 | 2024-01-26 | 75445位读者 | 引用回过头来看,才发现从第7篇《Transformer升级之路:7、长度外推性与局部注意力》开始,“Transformer升级之路”这个系列就跟长度外推“杠”上了,接连9篇文章(不算本文)都是围绕长度外推展开的。如今,距离第7篇文章刚好是一年多一点,在这一年间,开源社区关于长度外推的研究有了显著进展,笔者也逐渐有了一些自己的理解,比如其实这个问题远不像一开始想象那么简单,以往很多基于局部注意力的工作也不总是有效,这暗示着很多旧的分析工作并没触及问题的核心。
在这篇文章中,笔者尝试结合自己的发现和认识,去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。
问题定义
顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等,LongBench就是就属于这类榜单。

最近评论