






9
Jan
增强typecho的搜索功能
By 苏剑林 | 2018-01-09 | 68946位读者 | 引用科学空间是使用typecho程序搭建的博客,侧边栏提供了搜索功能,然而typecho内置搜索功能仅仅是基于字符串的全匹配查找,因此导致很多合理的查询都没法得到结果,比如“2018天象”、“新词算法”都没法给出结果,原因就是文章中都不包含这些字符串。
于是就萌生了加强搜索功能的想法,之前也有读者建议过这个事情。这两天搜索了一下,本来计划用Python下的Whoosh库来建立一个全文检索引擎,但感觉整合和后期维护的工作量太大,还是放弃了。后来想到在typecho自身的搜索上加强,在公司同事(大佬)的帮助下,完成了这个改进。
由于是直接修改typecho源文件实现的改进,因此如果typecho升级后就可能被覆盖,因此在这里做个备忘。
探索
通过在Github检索我发现,typecho的搜索功能是在var/Widget/Archive.php中实现的,具体代码大概在1185~1192行:
30
Jul
Keras实现两个优化器:Lookahead和LazyOptimizer
By 苏剑林 | 2019-07-30 | 47101位读者 | 引用最近用Keras实现了两个优化器,也算是有点实现技巧,遂放在一起写篇文章简介一下(如果只有一个的话我就不写了)。这两个优化器的名字都挺有意思的,一个是look ahead(往前看?),一个是lazy(偷懒?),难道是两个完全不同的优化思路么?非也非也~只能说发明者们起名字太有创意了。
Lookahead
首先登场的是Lookahead优化器,它源于论文《Lookahead Optimizer: k steps forward, 1 step back》,是最近才提出来的优化器,有意思的是大牛Hinton和Adam的作者之一Jimmy Ba也出现在了论文作者列表当中,有这两个大神加持,这个优化器的出现便吸引了不少目光。
14
Dec
Mitchell近似:乘法变为加法,误差不超过1/9
By 苏剑林 | 2020-12-14 | 40361位读者 | 引用今天给大家介绍一篇1962年的论文《Computer Multiplication and Division Using Binary Logarithms》,作者是John N. Mitchell,他在里边提出了一个相当有意思的算法:在二进制下,可以完全通过加法来近似完成两个数的相乘,最大误差不超过1/9。整个算法相当巧妙,更有意思的是它还有着非常简洁的编程实现,让人拍案叫绝。然而,笔者发现网上居然找不到介绍这个算法的网页,所以在此介绍一番。
你以为这只是过时的玩意?那你就错了,前不久才有人利用它发了一篇NeurIPS 2020呢!所以,确定不来了解一下吗?
22
Nov
ChildTuning:试试把Dropout加到梯度上去?
By 苏剑林 | 2021-11-22 | 66458位读者 | 引用Dropout是经典的防止过拟合的思路了,想必很多读者已经了解过它。有意思的是,最近Dropout有点“老树发新芽”的感觉,出现了一些有趣的新玩法,比如最近引起过热议的SimCSE和R-Drop,尤其是在文章《又是Dropout两次!这次它做到了有监督任务的SOTA》中,我们发现简单的R-Drop甚至能媲美对抗训练,不得不说让人意外。
一般来说,Dropout是被加在每一层的输出中,或者是加在模型参数上,这是Dropout的两个经典用法。不过,最近笔者从论文《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》中学到了一种新颖的用法:加到梯度上面。
梯度加上Dropout?相信大部分读者都是没听说过的。那么效果究竟如何呢?让我们来详细看看。
7
Oct
深度学习中的Lipschitz约束:泛化与生成模型
By 苏剑林 | 2018-10-07 | 152187位读者 | 引用前言:去年写过一篇WGAN-GP的入门读物《互怼的艺术:从零直达WGAN-GP》,提到通过梯度惩罚来为WGAN的判别器增加Lipschitz约束(下面简称“L约束”)。前几天遐想时再次想到了WGAN,总觉得WGAN的梯度惩罚不够优雅,后来也听说WGAN在条件生成时很难搞(因为不同类的随机插值就开始乱了...),所以就想琢磨一下能不能搞出个新的方案来给判别器增加L约束。
闭门造车想了几天,然后发现想出来的东西别人都已经做了,果然是只有你想不到,没有别人做不到。主要包含在这两篇论文中:《Spectral Norm Regularization for Improving the Generalizability of Deep Learning》和《Spectral Normalization for Generative Adversarial Networks》。
所以这篇文章就按照自己的理解思路,对L约束相关的内容进行简单的介绍。注意本文的主题是L约束,并不只是WGAN。它可以用在生成模型中,也可以用在一般的监督学习中。
L约束与泛化
扰动敏感
记输入为$x$,输出为$y$,模型为$f$,模型参数为$w$,记为
$$\begin{equation}y = f_w(x)\end{equation}$$
很多时候,我们希望得到一个“稳健”的模型。何为稳健?一般来说有两种含义,一是对于参数扰动的稳定性,比如模型变成了$f_{w+\Delta w}(x)$后是否还能达到相近的效果?如果在动力学系统中,还要考虑模型最终是否能恢复到$f_w(x)$;二是对于输入扰动的稳定性,比如输入从$x$变成了$x+\Delta x$后,$f_w(x+\Delta x)$是否能给出相近的预测结果。读者或许已经听说过深度学习模型存在“对抗攻击样本”,比如图片只改变一个像素就给出完全不一样的分类结果,这就是模型对输入过于敏感的案例。
9
Oct
关于WhiteningBERT原创性的疑问和沟通
By 苏剑林 | 2021-10-09 | 66990位读者 | 引用在文章《你可能不需要BERT-flow:一个线性变换媲美BERT-flow》中,笔者受到BERT-flow的启发,提出了一种名为BERT-whitening的替代方案,它比BERT-flow更简单,但多数数据集下能取得相近甚至更好的效果,此外它还可以用于对句向量降维以提高检索速度。后来,笔者跟几位合作者一起补充了BERT-whitening的实验,并将其写成了英文论文《Whitening Sentence Representations for Better Semantics and Faster Retrieval》,在今年3月29日发布在Arxiv上。
然而,大约一周后,一篇名为《WhiteningBERT: An Easy Unsupervised Sentence Embedding Approach》的论文 (下面简称WhiteningBERT)出现在Arxiv上,内容跟BERT-whitening高度重合,有读者看到后向我反馈WhiteningBERT抄袭了BERT-whitening。本文跟关心此事的读者汇报一下跟WhiteningBERT的作者之间的沟通结果。
时间节点
首先,回顾一下BERT-whitening的相关时间节点,以帮助大家捋一下事情的发展顺序:
3
Apr
P-tuning:自动构建模版,释放语言模型潜能
By 苏剑林 | 2021-04-03 | 148791位读者 | 引用在之前的文章《必须要GPT3吗?不,BERT的MLM模型也能小样本学习》中,我们介绍了一种名为Pattern-Exploiting Training(PET)的方法,它通过人工构建的模版与BERT的MLM模型结合,能够起到非常好的零样本、小样本乃至半监督学习效果,而且该思路比较优雅漂亮,因为它将预训练任务和下游任务统一起来了。然而,人工构建这样的模版有时候也是比较困难的,而且不同的模版效果差别也很大,如果能够通过少量样本来自动构建模版,也是非常有价值的。
![P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性](/usr/uploads/2021/04/2868831073.png)
P-tuning直接使用[unused]来构建模版,不关心模版的自然语言性
最近Arxiv上的论文《GPT Understands, Too》提出了名为P-tuning的方法,成功地实现了模版的自动构建。不仅如此,借助P-tuning,GPT在SuperGLUE上的成绩首次超过了同等级别的BERT模型,这颠覆了一直以来“GPT不擅长NLU”的结论,也是该论文命名的缘由。
18
Jun
当Bert遇上Keras:这可能是Bert最简单的打开姿势
By 苏剑林 | 2019-06-18 | 426093位读者 | 引用Bert是什么,估计也不用笔者来诸多介绍了。虽然笔者不是很喜欢Bert,但不得不说,Bert确实在NLP界引起了一阵轩然大波。现在不管是中文还是英文,关于Bert的科普和解读已经满天飞了,隐隐已经超过了当年Word2Vec刚出来的势头了。有意思的是,Bert是Google搞出来的,当年的word2vec也是Google搞出来的,不管你用哪个,都是在跟着Google大佬的屁股跑啊~
Bert刚出来不久,就有读者建议我写个解读,但我终究还是没有写。一来,Bert的解读已经不少了,二来其实Bert也就是基于Attention的搞出来的大规模语料预训练的模型,本身在技术上不算什么创新,而关于Google的Attention我已经写过解读了,所以就提不起劲来写了。
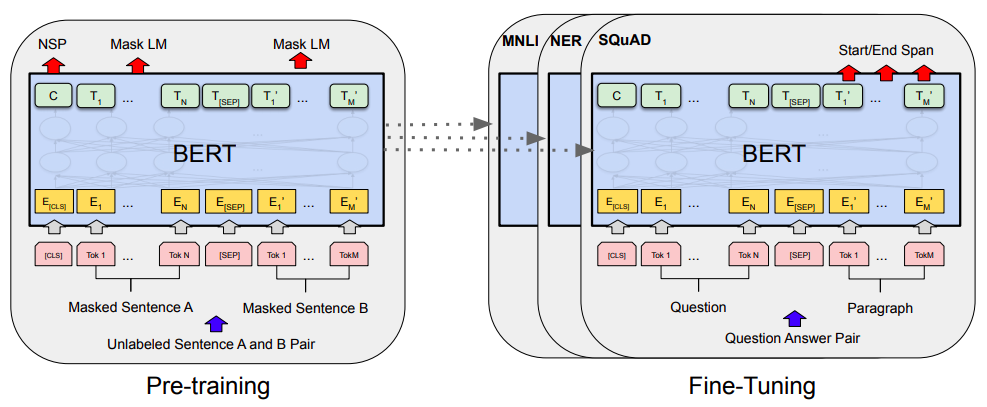
Bert的预训练和微调(图片来自Bert的原论文)
总的来说,我个人对Bert一直也没啥兴趣,直到上个月末在做信息抽取比赛时,才首次尝试了Bert。因为后来想到,即使不感兴趣,终究也是得学会它,毕竟用不用是一回事,会不会又是另一回事。再加上在Keras中使用(fine tune)Bert,似乎还没有什么文章介绍,所以就分享一下自己的使用经验。

最近评论