






22
Oct
RSGAN:对抗模型中的“图灵测试”思想
By 苏剑林 | 2018-10-22 | 129080位读者 | 引用这两天无意间发现一个非常有意义的工作,称为“相对GAN”,简称RSGAN,来自文章《The relativistic discriminator: a key element missing from standard GAN》,据说该文章还得到了GAN创始人Goodfellow的点赞。这篇文章提出了用相对的判别器来取代标准GAN原有的判别器,使得生成器的收敛更为迅速,训练更为稳定。
可惜的是,这篇文章仅仅从训练和实验角度对结果进行了论述,并没有进行更深入的分析,以至于不少人觉得这只是GAN训练的一个trick。但是在笔者来看,RSGAN具有更为深刻的含义,甚至可以看成它已经开创了一个新的GAN流派。所以,笔者决定对RSGAN模型及其背后的内涵做一个基本的介绍。不过需要指出的是,除了结果一样之外,本文的介绍过程跟原论文相比几乎没有重合之处。
“图灵测试”思想
SGAN
SGAN就是标准的GAN(Standard GAN)。就算没有做过GAN研究的读者,相信也从各种渠道了解到GAN的大概原理:“造假者”不断地进行造假,试图愚弄“鉴别者”;“鉴别者”不断提高鉴别技术,以分辨出真品和赝品。两者相互竞争,共同进步,直到“鉴别者”无法分辨出真、赝品了,“造假者”就功成身退了。
在建模时,通过交替训练实现这个过程:固定生成器,训练一个判别器(二分类模型),将真实样本输出1,将伪造样本输出0;然后固定判别器,训练生成器让伪造样本尽可能输出1,后面这一步不需要真实样本参与。
问题所在
然而,这个建模过程似乎对判别器的要求过于苛刻了,因为判别器是孤立运作的:训练生成器时,真实样本没有参与,所以判别器必须把关于真实样本的所有属性记住,这样才能指导生成器生成更真实的样本。
2
Dec
最小熵原理(四):“物以类聚”之从图书馆到词向量
By 苏剑林 | 2018-12-02 | 95220位读者 | 引用从第一篇看下来到这里,我们知道所谓“最小熵原理”就是致力于降低学习成本,试图用最小的成本完成同样的事情。所以整个系列就是一个“偷懒攻略”。那偷懒的秘诀是什么呢?答案是“套路”,所以本系列又称为“套路宝典”。
本篇我们介绍图书馆里边的套路。
先抛出一个问题:词向量出现在什么时候?是2013年Mikolov的Word2Vec?还是是2003年Bengio大神的神经语言模型?都不是,其实词向量可以追溯到千年以前,在那古老的图书馆中...

图书馆一角(图片来源于百度搜索)
走进图书馆
图书馆里有词向量?还是千年以前?在哪本书?我去借来看看。
放书的套路
其实不是哪本书,而是放书的套路。
很明显,图书馆中书的摆放是有“套路”的:它们不是随机摆放的,而是分门别类地放置的,比如数学类放一个区,文学类放一个区,计算机类也放一个区;同一个类也有很多子类,比如数学类中,数学分析放一个子区,代数放一个子区,几何放一个子区,等等。读者是否思考过,为什么要这么分类放置?分类放置有什么好处?跟最小熵又有什么关系?
8
Jan
从动力学角度看优化算法(三):一个更整体的视角
By 苏剑林 | 2019-01-08 | 59747位读者 | 引用
27
Jan
“让Keras更酷一些!”:随意的输出和灵活的归一化
By 苏剑林 | 2019-01-27 | 103540位读者 | 引用继续“让Keras更酷一些!”系列,让Keras来得更有趣些吧~
这次围绕着Keras的loss、metric、权重和进度条进行展开。
可以不要输出
一般我们用Keras定义一个模型,是这样子的:
x_in = Input(shape=(784,))
x = x_in
x = Dense(100, activation='relu')(x)
x = Dense(10, activation='softmax')(x)
model = Model(x_in, x)
model.compile(loss='categorical_crossentropy ',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
22
Feb
巧断梯度:单个loss实现GAN模型
By 苏剑林 | 2019-02-22 | 46104位读者 | 引用我们知道普通的模型都是搭好架构,然后定义好loss,直接扔给优化器训练就行了。但是GAN不一样,一般来说它涉及有两个不同的loss,这两个loss需要交替优化。现在主流的方案是判别器和生成器都按照1:1的次数交替训练(各训练一次,必要时可以给两者设置不同的学习率,即TTUR),交替优化就意味我们需要传入两次数据(从内存传到显存)、执行两次前向传播和反向传播。
如果我们能把这两步合并起来,作为一步去优化,那么肯定能节省时间的,这也就是GAN的同步训练。
(注:本文不是介绍新的GAN,而是介绍GAN的新写法,这只是一道编程题,不是一道算法题~)
如果在TF中
3
Sep
百度实体链接比赛后记:行为建模和实体链接
By 苏剑林 | 2019-09-03 | 87118位读者 | 引用前几个月曾参加了百度的实体链接比赛,这是CCKS2019的评测任务之一,官方称之为“实体链指”,比赛于前几个星期完全结束。笔者最终的F1是0.78左右(冠军是0.80),排在第14名,成绩并不突出(唯一的特色是模型很轻量级,GTX1060都可以轻松跑起来),所以本文只是纯粹的记录过程,大牛们请一笑置之~
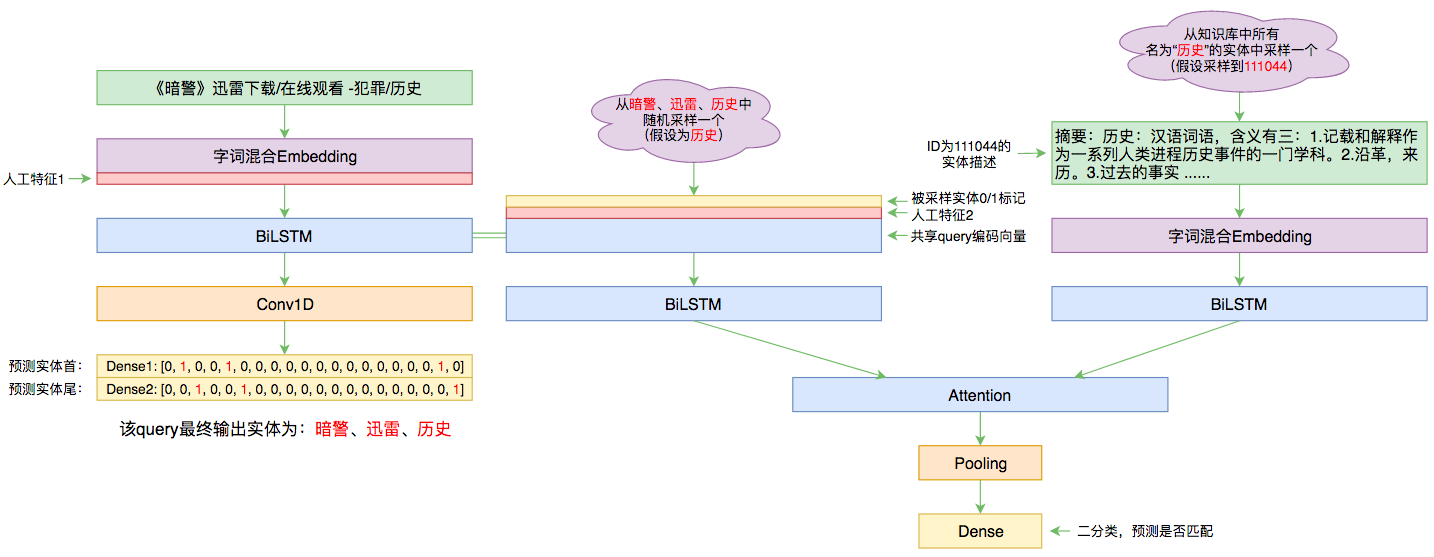
本文的实体链接模型总图(可以点击查看大图)
赛题介绍
所谓实体链接,主要指的是在已有一个知识库的情况下,预测输入query的某个实体对应知识库id。也就是说,知识库里边记录了很多实体,对于同一个名字的实体可能会有多个解释,每个解释用一个唯一id编号,我们要做的就是预测query中的实体究竟对应哪一个解释(id)。这是基于知识图谱的问答系统的必要步骤。
20
Apr
EAE:自编码器 + BN + 最大熵 = 生成模型
By 苏剑林 | 2020-04-20 | 58987位读者 | 引用生成模型一直是笔者比较关注的主题,不管是NLP和CV的生成模型都是如此。这篇文章里,我们介绍一个新颖的生成模型,来自论文《Batch norm with entropic regularization turns deterministic autoencoders into generative models》,论文中称之为EAE(Entropic AutoEncoder)。它要做的事情给变分自编码器(VAE)基本一致,最终效果其实也差不多(略优),说它新颖并不是它生成效果有多好,而是思路上的新奇,颇有别致感。此外,借着这个机会,我们还将学习一种统计量的估计方法——$k$邻近方法,这是一种很有用的非参数估计方法。
自编码器vs生成模型
普通的自编码器是一个“编码-解码”的重构过程,如下图所示:
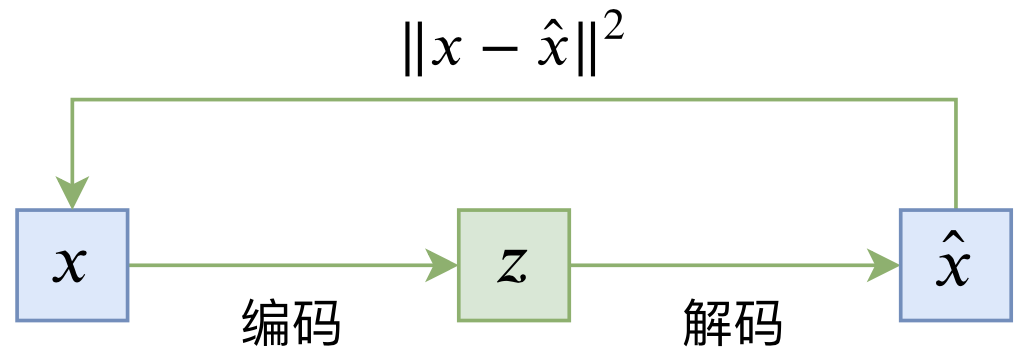
典型自编码器示意图
其loss一般为
\begin{equation}L_{AE} = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - \hat{x}\right\Vert^2\right] = \mathbb{E}_{x\sim \tilde{p}(x)}\left[\left\Vert x - D(E(x))\right\Vert^2\right]\end{equation}
25
Jul
学会提问的BERT:端到端地从篇章中构建问答对
By 苏剑林 | 2020-07-25 | 115917位读者 | 引用机器阅读理解任务,相比不少读者都有所了解了,简单来说就是从给定篇章中寻找给定问题的答案,即“篇章 + 问题 → 答案”这样的流程,笔者之前也写过一些关于阅读理解的文章,比如《基于CNN的阅读理解式问答模型:DGCNN》等。至于问答对构建,则相当于是阅读理解的反任务,即“篇章 → 答案 + 问题”的流程,学术上一般直接叫“问题生成(Question Generation)”,因为大多数情况下,答案可以通过比较规则的随机选择,所以很多文章都只关心“篇章 + 答案 → 问题”这一步。
本文将带来一次全端到端的“篇章 → 答案 + 问题”实践,包括模型介绍以及基于bert4keras的实现代码,欢迎读者尝试。
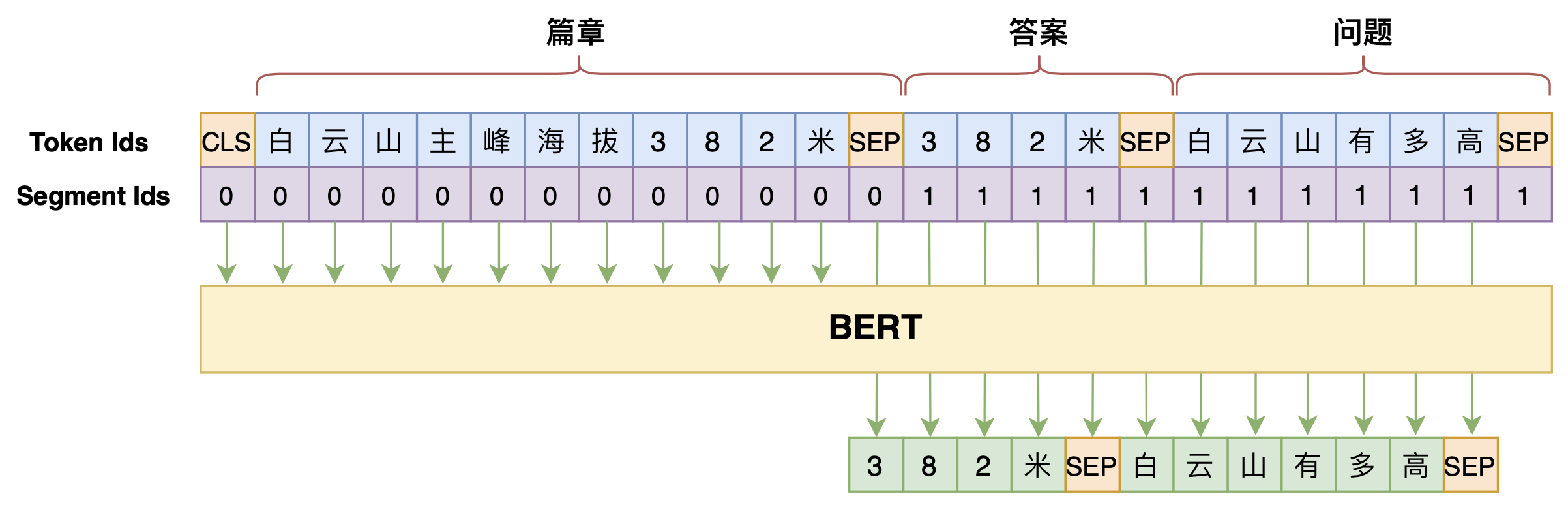
本文的问答生成模型示意图

最近评论