






3
Jun
基于DGCNN和概率图的轻量级信息抽取模型
By 苏剑林 | 2019-06-03 | 413489位读者 | 引用背景:前几个月,百度举办了“2019语言与智能技术竞赛”,其中有三个赛道,而我对其中的“信息抽取”赛道颇感兴趣,于是报名参加。经过两个多月的煎熬,比赛终于结束,并且最终结果已经公布。笔者从最初的对信息抽取的一无所知,经过这次比赛的学习和研究,最终探索出在监督学习下做信息抽取的一些经验,遂在此与大家分享。

信息抽取赛道:“科学空间队”在最终的测试结果上排名第七
笔者在最终的测试集上排名第七,指标F1为0.8807(Precision是0.8939,Recall是0.8679),跟第一名相差0.01左右。从比赛角度这个成绩不算突出,但自认为模型有若干创新之处,比如自行设计的抽取结构、CNN+Attention(所以足够快速)、没有用Bert等预训练模型,私以为这对于信息抽取的学术研究和工程应用都有一定的参考价值。
基本分析
信息抽取(Information Extraction, IE)是从自然语言文本中抽取实体、属性、关系及事件等事实类信息的文本处理技术,是信息检索、智能问答、智能对话等人工智能应用的重要基础,一直受到业界的广泛关注。... 本次竞赛将提供业界规模最大的基于schema的中文信息抽取数据集(Schema based Knowledge Extraction, SKE),旨在为研究者提供学术交流平台,进一步提升中文信息抽取技术的研究水平,推动相关人工智能应用的发展。------ 比赛官方网站介绍
27
Jul
为节约而生:从标准Attention到稀疏Attention
By 苏剑林 | 2019-07-27 | 135158位读者 | 引用
attention, please!
如今NLP领域,Attention大行其道,当然也不止NLP,在CV领域Attention也占有一席之地(Non Local、SAGAN等)。在18年初《〈Attention is All You Need〉浅读(简介+代码)》一文中,我们就已经讨论过Attention机制,Attention的核心在于$\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}$三个向量序列的交互和融合,其中$\boldsymbol{Q},\boldsymbol{K}$的交互给出了两两向量之间的某种相关度(权重),而最后的输出序列则是把$\boldsymbol{V}$按照权重求和得到的。
显然,众多NLP&CV的成果已经充分肯定了Attention的有效性。本文我们将会介绍Attention的一些变体,这些变体的共同特点是——“为节约而生”——既节约时间,也节约显存。
背景简述
《Attention is All You Need》一文讨论的我们称之为“乘性Attention”,目前用得比较广泛的也就是这种Attention:
\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\frac{\boldsymbol{Q}\boldsymbol{K}^{\top}}{\sqrt{d_k}}\right)\boldsymbol{V}\end{equation}
29
Jun
基于Bert的NL2SQL模型:一个简明的Baseline
By 苏剑林 | 2019-06-29 | 142640位读者 | 引用在之前的文章《当Bert遇上Keras:这可能是Bert最简单的打开姿势》中,我们介绍了基于微调Bert的三个NLP例子,算是体验了一把Bert的强大和Keras的便捷。而在这篇文章中,我们再添一个例子:基于Bert的NL2SQL模型。
NL2SQL的NL也就是Natural Language,所以NL2SQL的意思就是“自然语言转SQL语句”,近年来也颇多研究,它算是人工智能领域中比较实用的一个任务。而笔者做这个模型的契机,则是今年我司举办的首届“中文NL2SQL挑战赛”:
首届中文NL2SQL挑战赛,使用金融以及通用领域的表格数据作为数据源,提供在此基础上标注的自然语言与SQL语句的匹配对,希望选手可以利用数据训练出可以准确转换自然语言到SQL的模型。
这个NL2SQL比赛算是今年比较大型的NLP赛事了,赛前投入了颇多人力物力进行宣传推广,比赛的奖金也颇丰富,唯一的问题是NL2SQL本身算是偏冷门的研究领域,所以注定不会太火爆,为此主办方也放出了一个Baseline,基于Pytorch写的,希望能降低大家的入门难度。
抱着“Baseline怎么能少得了Keras版”的心态,我抽时间自己用Keras做了做这个比赛,为了简化模型并且提升效果也加载了预训练的Bert模型,最终形成此文。
25
Apr
将“Softmax+交叉熵”推广到多标签分类问题
By 苏剑林 | 2020-04-25 | 348448位读者 | 引用(注:本文的相关内容已整理成论文《ZLPR: A Novel Loss for Multi-label Classification》,如需引用可以直接引用英文论文,谢谢。)
一般来说,在处理常规的多分类问题时,我们会在模型的最后用一个全连接层输出每个类的分数,然后用softmax激活并用交叉熵作为损失函数。在这篇文章里,我们尝试将“Softmax+交叉熵”方案推广到多标签分类场景,希望能得到用于多标签分类任务的、不需要特别调整类权重和阈值的loss。

类别不平衡
单标签到多标签
一般来说,多分类问题指的就是单标签分类问题,即从$n$个候选类别中选$1$个目标类别。假设各个类的得分分别为$s_1,s_2,
\dots,s_n$,目标类为$t\in\{1,2,\dots,n\}$,那么所用的loss为
\begin{equation}-\log \frac{e^{s_t}}{\sum\limits_{i=1}^n e^{s_i}}= - s_t + \log \sum\limits_{i=1}^n e^{s_i}\label{eq:log-softmax}\end{equation}
这个loss的优化方向是让目标类的得分$s_t$变为$s_1,s_2,\dots,s_t$中的最大值。关于softmax的相关内容,还可以参考《寻求一个光滑的最大值函数》、《函数光滑化杂谈:不可导函数的可导逼近》等文章。
2
Apr
bert4keras在手,baseline我有:百度LIC2020
By 苏剑林 | 2020-04-02 | 94346位读者 | 引用百度的“2020语言与智能技术竞赛”开赛了,今年有五个赛道,分别是机器阅读理解、推荐任务对话、语义解析、关系抽取、事件抽取。每个赛道中,主办方都给出了基于PaddlePaddle的baseline模型,这里笔者也基于bert4keras给出其中三个赛道的个人baseline,从中我们可以看到用bert4keras搭建baseline模型的方便快捷与简练。
思路简析
这里简单分析一下这三个赛道的任务特点以及对应的baseline设计。
18
May
鱼与熊掌兼得:融合检索和生成的SimBERT模型
By 苏剑林 | 2020-05-18 | 294964位读者 | 引用前段时间我们开放了一个名为SimBERT的模型权重,它是以Google开源的BERT模型为基础,基于微软的UniLM思想设计了融检索与生成于一体的任务,来进一步微调后得到的模型,所以它同时具备相似问生成和相似句检索能力。不过当时除了放出一个权重文件和示例脚本之外,未对模型原理和训练过程做进一步说明。在这篇文章里,我们来补充这部分内容。
UniLM
UniLM是一个融合NLU和NLG能力的Transformer模型,由微软在去年5月份提出来的,今年2月份则升级到了v2版本。我们之前的文章《从语言模型到Seq2Seq:Transformer如戏,全靠Mask》就简单介绍过UniLM,并且已经集成到了bert4keras中。
UniLM的核心是通过特殊的Attention Mask来赋予模型具有Seq2Seq的能力。假如输入是“你想吃啥”,目标句子是“白切鸡”,那UNILM将这两个句子拼成一个:[CLS] 你 想 吃 啥 [SEP] 白 切 鸡 [SEP],然后接如图的Attention Mask:

UniLM的Mask
7
Sep
动手做个DialoGPT:基于LM的生成式多轮对话模型
By 苏剑林 | 2020-09-07 | 104428位读者 | 引用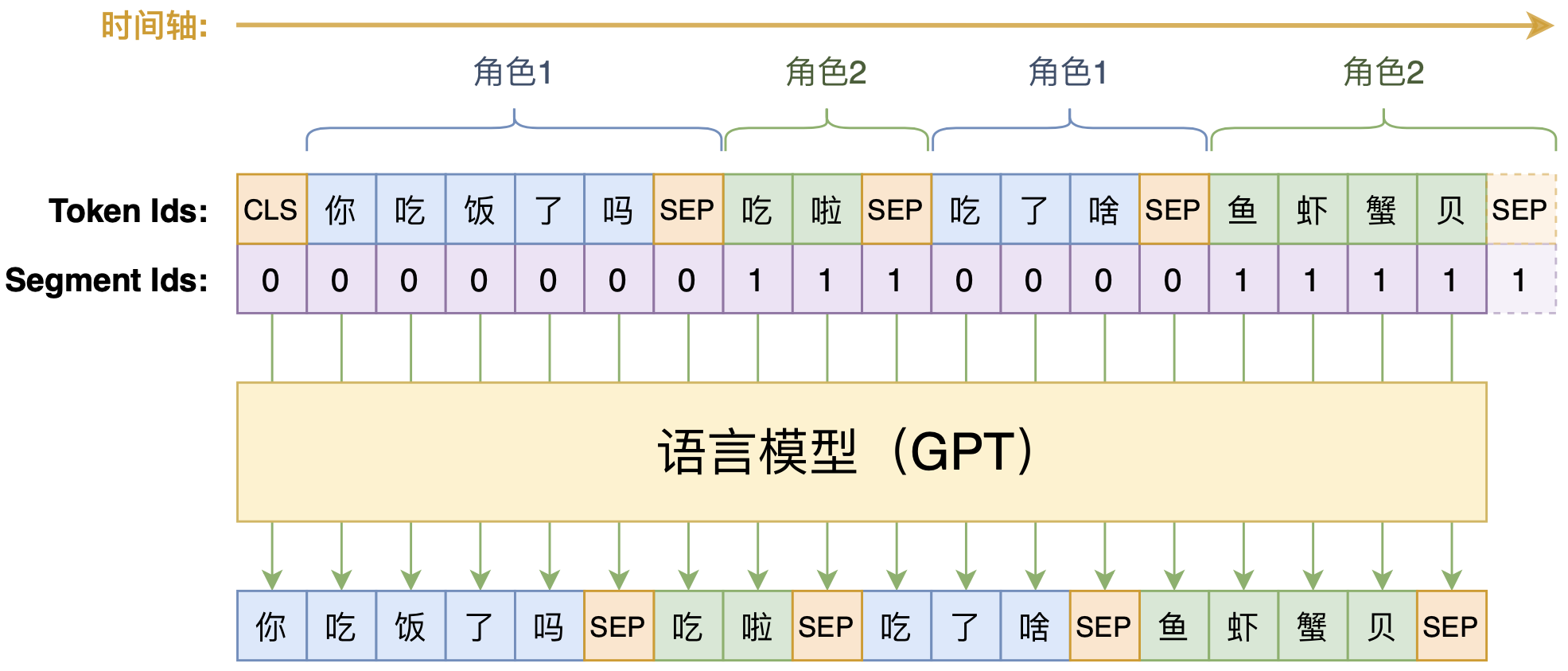
19
Oct
BERT可以上几年级了?Seq2Seq“硬刚”小学数学应用题
By 苏剑林 | 2020-10-19 | 69117位读者 | 引用
“鸡兔同笼”的那些年
“盈亏问题”、“年龄问题”、“植树问题”、“牛吃草问题”、“利润问题”...,小学阶段你是否曾被各种花样的数学应用题折磨过呢?没关系,现在机器学习模型也可以帮助我们去解答应用题了,来看看它可以上几年级了?
本文将给出一个求解小学数学应用题(Math Word Problem)的baseline,基于ape210k数据集训练,直接用Seq2Seq模型生成可执行的数学表达式,最终Large版本的模型能达到75%的准确率,明显高于ape210k论文所报告的结果。所谓“硬刚”,指的是没有对表达式做特别的转换,也没有通过模板处理,就直接生成跟人类做法相近的可读表达式。

最近评论