






20
Jan
简单的迅雷VIP账号获取器(Python)
By 苏剑林 | 2016-01-20 | 32766位读者 | 引用在Windows工作的时候,经常会用迅雷下载东西,如果速度慢或者没资源,尤其是一些比较冷门的视频,迅雷的VIP会员服务总能够帮上大忙。后来无意间发现了有个“迅雷VIP账号获取器”的软件,可以获取一些临时的VIP账号供使用,这可是个好东西,因为开通迅雷会员虽然不贵,但是我又不经常下载,所以老感觉有点浪费,而有了这个之后,我随时下点东西都可以免费用了。
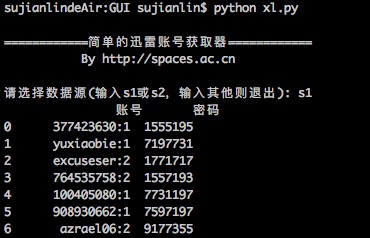
简单的迅雷VIP账号获取器
最近转移到了Mac上,而Mac也有迅雷,但那个账号获取器是exe的,不能在Mac运行。本以为获取器的构造会很复杂,谁知道,经过抓包研究,发现那个账号获取器的原理极其简单,说白了,就是一个简单的爬虫,以下这两个网站提供账号,它就到相应的抓取账号而已:
http://yunbo.xinjipin.com/
http://www.fenxs.com
据此,我也用Python简单写了一个,主要是方便我在Mac使用。读者如果有需要,也可以下载使用,代码兼容2.x和3.x的版本。主要的库是requests和re,pandas和sys的使用只不过是为了更加人性化。本来想用Tkinter写一个简单的GUI的,但是想想看,还是没必要了~~
7
Mar
通过ssh动态端口转发共享校园资源(附带干货)
By 苏剑林 | 2016-03-07 | 36784位读者 | 引用众所周知,校园网最宝贵的资源应该有两样:一是IPv6,IPv6是访问Google等网站的最理想途径,当然IPv6并非所有高校都有;二是论文库,一般高校都会买了一部分论文库(知网、万方等)的下载权,供校园用户使用。如果说访问Google还有VPN等诸多方式的话,那么对于校外用户来说访问知网等资源就显得格外宝贵了,一般只是叫校内用户下载,或者就只能付费了(那个贵呀!)。
站长还是学生,在学校同时享用着IPv6和论文库资源,确实很爽。自从用上Openwrt的路由之后,一直想着怎么把校园网资源共享出去。曾经考虑过搭建PPTP VPN,但是感觉略有复杂(当然,跟其他VPN相比,搭建PPTP VPN算是非常简单的了,可是我还是不怎么喜欢。),而且当时还没解决内网穿透的问题。最近借助ssh反向代理的方式实现了内网穿透,继而认识到,通过ssh动态端口转发,居然还可以搭建代理,并且实现远程访问内网(校园网)资源,而且几乎不用在路由器本身上面做任何配置。不得不说,ssh真是一个极其强大的东西呀。
添加普通帐号
既然要共享,就没理由把root账户都分享出去了,因此,第一步要实现的是在Openwrt上添加一个代理账号,而且为了安全和保密,这个账号不允许真的登陆服务器进行操作,而只允许进行端口转发。
7
Feb
年三十折腾极路由之SSH反向代理
By 苏剑林 | 2016-02-07 | 62205位读者 | 引用
猴年快乐!
今天是年三十了,这里简单祝大家除夕快乐,新年快乐!愿大家在新的一年里都晋升为学神。^_^
这两天主要在折腾家里的路由器。平时家里只有爸妈两人,所以为了节省,家里只是通过中继隔壁家的网络来上网。本来家里用小米路由器mini,可是小米mini中继模式下功能限制非常多,我又不想刷第三方固件(因为这样会失去app控制功能,不是很方便),所以干脆换了个极路由3。极路由在中继模式下仍然保留了大部分功能(我觉得这样才是正常的,我不理解小米mini在中继之后就没了那么多功能究竟是什么逻辑)。
作为折腾派,一个新路由到手,总有很多东西要配置,极路由本身是基于openwrt的,因此可玩性也很强。首先要完成中继,然后上网,这个很简单就不多说了。其次是获得ssh权限,在极路由那里叫做“申请开发者模式”,或者叫root(感觉极路由想做路由界的苹果,但是在如今这个时代,苹果当初那种发展模式估计很难发展起来了),这个步骤也不难,不过申请之后就会失去极路由的保修资格(不理解这是什么逻辑)。
本文主要介绍了怎么在openwrt(极路由)上安装python,以及建立SSH反向代理(实现内网穿透)。
4
Mar
趣题:如何编程列出一个集合的所有子集
By 苏剑林 | 2016-03-04 | 30684位读者 | 引用
6
Mar
Openwrt自动扫描WiFi并连接中继
By 苏剑林 | 2016-03-06 | 56083位读者 | 引用
12
Apr
【备忘】用树莓派3做无线路由器
By 苏剑林 | 2016-04-12 | 66449位读者 | 引用3月初发布的树莓派3自带了WiFi和蓝牙,再加上它本来就有一个网口,因此俨然就是一台无线路由器了。我也忍不住入手了一个,打算用来做路由器和NAS。树莓派做路由器的教程已经有很多了,当然,基本都是基于树莓派2的,3之前的版本都没有自带WiFi,因此需要自己配无线网卡,而3自带了无线网卡,配置就方便多了。参考了两篇外文教程,成功配置,在这里记录一下。
参考教程:
https://frillip.com/using-your-raspberry-pi-3-as-a-wifi-access-point-with-hostapd/
https://gist.github.com/Lewiscowles1986/fecd4de0b45b2029c390#file-rpi3-ap-setup-sh
29
Jun
文本情感分类(三):分词 OR 不分词
By 苏剑林 | 2016-06-29 | 419060位读者 | 引用去年泰迪杯竞赛过后,笔者写了一篇简要介绍深度学习在情感分析中的应用的博文《文本情感分类(二):深度学习模型》。虽然文章很粗糙,但还是得到了不少读者的反响,让我颇为意外。然而,那篇文章中在实现上有些不清楚的地方,这是因为:1、在那篇文章以后,keras已经做了比较大的改动,原来的代码不通用了;2、里边的代码可能经过我随手改动过,所以发出来的时候不是最适当的版本。因此,在近一年之后,我再重拾这个话题,并且完成一些之前没有完成的测试。
为什么要用深度学习模型?除了它更高精度等原因之外,还有一个重要原因,那就是它是目前唯一的能够实现“端到端”的模型。所谓“端到端”,就是能够直接将原始数据和标签输入,然后让模型自己完成一切过程——包括特征的提取、模型的学习。而回顾我们做中文情感分类的过程,一般都是“分词——词向量——句向量(LSTM)——分类”这么几个步骤。虽然很多时候这种模型已经达到了state of art的效果,但是有些疑问还是需要进一步测试解决的。对于中文来说,字才是最低粒度的文字单位,因此从“端到端”的角度来看,应该将直接将句子以字的方式进行输入,而不是先将句子分好词。那到底有没有分词的必要性呢?本文测试比较了字one hot、字向量、词向量三者之间的效果。
模型测试
本文测试了三个模型,或者说,是三套框架,具体代码在文末给出。这三套框架分别是:
1、one hot:以字为单位,不分词,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-one hot”的矩阵形式输入到LSTM模型中进行学习分类;
2、one embedding:以字为单位,不分词,,将每个句子截断为200字(不够则补空字符串),然后将句子以“字-字向量(embedding)“的矩阵形式输入到LSTM模型中进行学习分类;
3、word embedding:以词为单位,分词,,将每个句子截断为100词(不够则补空字符串),然后将句子以“词-词向量(embedding)”的矩阵形式输入到LSTM模型中进行学习分类。
26
Jun

最近评论